与创建基于微服务的架构相关的最常提到的挑战之一是监控。每个微服务都应该在与其他微服务隔离的环境中运行,因此它不会与它们共享数据库或日志文件等资源。然而,微服务架构的基本要求是相对容易访问调用历史,包括能够查看多个微服务之间的请求传播。Grepping 日志不是该问题的正确解决方案。在使用 Spring Boot 和 Spring Cloud 框架创建微服务时,可以使用一些有用的工具,比如:Spring Cloud Sleuth,Zipkin 。
Spring Cloud Sleuth – 作为 Spring Cloud 项目的一部分提供的库。允许您通过向 HTTP 请求添加适当的标头来跟踪后续微服务的进度。该库基于 MDC(Mapped Diagnostic Context)概念,您可以在其中轻松提取放入上下文的值并将其显示在日志中。
Zipkin – 分布式跟踪系统,有助于为在独立服务之间传播的每个请求收集计时数据。它有简单的管理控制台,我们可以在其中找到后续服务生成的时间统计的可视化报告。
ELK – Elasticsearch、Logstash、Kibana:通常一起使用的三种不同工具。它们用于实时搜索、分析和可视化日志数据。
关于ELK更多内容请参阅作者的Elasticsearch从入门到精通 Kibana从入门到精通 logstash快速入门实战指南
可能很多人,即使您之前没有接触过 Java 或微服务,也听说过 Logstash 和 Kibana。例如,如果您在hub.docker.com中查看最流行的images,您会发现上述工具。在我们的示例中,我们将使用这些工具。让我们从使用 Elasticsearch 运行容器开始。
docker run -d -it --name es -p 9200:9200 -p 9300:9300 elasticsearch 我们可以运行 Kibana 容器并将其链接到 Elasticsearch。
docker run -d -it --name kibana --link es:elasticsearch -p 5601:5601 kibana 最后,我们将启动 Logstash,并声明输入和输出。作为输入,我们声明 TCP,它与
LogstashTcpSocketAppender
在我们的示例应用程序中用作日志附加程序兼容。作为输出,elasticsearch 已被声明。每个微服务都将以其名称为索引,并带有micro前缀。
docker run -d -it --name logstash -p 5000:5000 logstash -e 'input { tcp { port => 5000 codec => "json" } } output { elasticsearch { hosts => ["192.168.99.100"] index => "micro-%{serviceName}"} }' 现在我们可以看看示例微服务。这篇文章是我之前文章使用 Zuul、Ribbon、Feign、Eureka 和 Sleuth、Zipkin 创建简单spring cloud微服务用例-spring cloud 入门教程的延续。体系结构和公开的服务与前一个示例中的相同。就像之前提到的,我们将使用 Logback 库将日志数据发送到 Logstash。 除了三个 Logback 依赖项之外,我们还添加了用于 Zipkin 集成和 Spring Cloud Sleuth starter 的库。这是微服务的pom.xml片段。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | |
Logback 配置文件位于src/main/resources目录下 。下面展现的是logback.xml文件内容片段。我们可以配置哪些日志字段发送到Logstash,我们还附加服务名称字段到索引中。
| 24 25 | |
Spring Cloud Sleuth 的配置非常简单。我们只需要将
spring-cloud-starter-sleuth
依赖添加到pom.xml,在采样的类上声明
@Bean
。
|
启动 ELK docker 容器后,我们需要运行我们的微服务。有 5 个 Spring Boot 应用程序需要运行discovery-service、account-service、customer-service、gateway-service和zipkin-service。全部启动后,我们可以尝试调用一些服务,例如http://localhost:8765/api/customer/customers/ {id},这会导致客户和帐户服务的调用。所有日志都将存储在带有micro-%{serviceName}索引的elasticsearch 中。可以使用micro-*索引模式在 Kibana 中搜索它们。索引模式在 Kibana 中的管理部分下创建->索引模式(Management -> Index patterns)。Kibana 的访问地址http://192.168.99.100:5601。第一次运行后,我们会提示输入索引模式,所以让我们输入micro-*。在“Discover(发现)”部分下,我们可以通过时间线可视化查看所有匹配类型模式的日志。
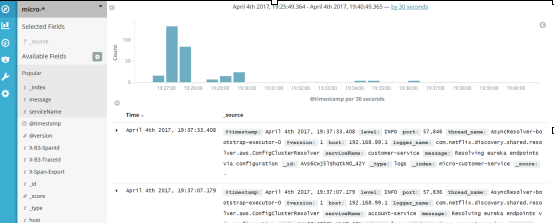
Kibana 是相当直观且用户友好的工具。Kibana 的使用方法我就不详细介绍了,你自己看文档或者直接点击 UI 就可以很容易地找到了。最重要的是能够通过过滤条件搜索日志。下图中有一个通过X-B3-TraceId字段搜索日志的示例,该字段由 Spring Cloud Sleuth 添加到请求头中。Sleuth 还添加了X-B3-SpanId来标记单个微服务的请求。我们可以选择在结果列表中显示哪个字段——在这个示例中,我选择了message和serviceName,就像您在图片的左窗格中看到的那样。

这是带有单个请求详细信息的图片。展开每个日志行后可见。
Spring Cloud Sleuth 还将统计信息发送到 Zipkin。这是另一种数据报告形式,而不是存储在 Logstash 中。它展现的是每个请求的计时统计信息。Zipkin UI 非常简单。您可以按时间、服务名称、端点名称等条件过滤请求。这是使用 Kibana 可视化的具有相同请求的图片:http://localhost:8765/api/customer/customers/ {id}。
我们始终可以通过单击来查看每个请求的详细信息。然后你会看到类似于下面可见的图片。一开始,请求已经在 API 网关上进行了处理。然后网关在 Eureka 服务器上发现客户服务并调用该服务。客户服务也必须发现帐户服务,然后调用它。在此视图中,您可以轻松找出最耗时的操作。
使用 Zuul、Ribbon、Feign、Eureka 和 Sleuth、Zipkin 创建简单spring cloud微服务用例-spring cloud 入门教程
微服务集成SPRING CLOUD SLEUTH、ELK 和 ZIPKIN 进行监控-spring cloud 入门教程
使用Hystrix 、Feign 和 Ribbon构建微服务-spring cloud 入门教程
使用 Spring Boot Admin 监控微服务-spring cloud 入门教程
基于Redis做Spring Cloud Gateway 中的速率限制实践-spring cloud 入门教程
集成SWAGGER2服务-spring cloud 入门教程
Hystrix 简介-spring cloud 入门教程
Hystrix 原理深入分析-spring cloud 入门教程
使用Apache Camel构建微服务-spring cloud 入门教程
集成 Kubernetes 来构建微服务-spring cloud 入门教程
集成SPRINGDOC OPENAPI 的微服务实践-spring cloud 入门教程
SPRING CLOUD 微服务快速指南-spring cloud 入门教程
基于GraphQL的微服务实践-spring cloud 入门教程
最火的Spring Cloud Gateway 为经过身份验证的用户启用速率限制实践-spring cloud 入门教程