| 这个作业属于哪个课程 | |
| 这个作业要求在哪里 | j |
| 这个作业的目的 | 熟悉一个项目的完整开发流程,锻炼个人编程能力 学习使用代码质量分析工具和性能分析工具,学会进行单元测试 |
作业GitHub链接:https://github.com/blip00/blip00
1. PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
| Planning | 计划 | 30 | |
| · Estimate | · 估计这个任务需要多少时间 | ||
| Development | 开发 | 890 | 940 |
| · Analysis | · 需求分析 (包括学习新技术) | 180 | |
| · Design Spec | · 生成设计文档 | 60 | 40 |
| · Design Review | · 设计复审 | 20 | |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | ||
| · Design | · 具体设计 | ||
| · Coding | · 具体编码 | 360 | 330 |
| · Code Review | · 代码复审 | ||
| · Test | · 测试(自我测试,修改代码,提交修改) | 120 | 240 |
| Reporting | 报告 | 200 | |
| · Test Report | · 测试报告 | 150 | |
| · Size Measurement | · 计算工作量 | ||
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | ||
| · 合计 |
2. 计算模块接口的设计与实现过程
-
模块接口设计
考虑到整个程序的运行过程并降低功能模块之间的耦合性,我设计将程序分为三个模块,分别是负责读写文件的文件IO操作模块、负责计算文本相似度的核心算法模块、负责调用前两者的主模块。
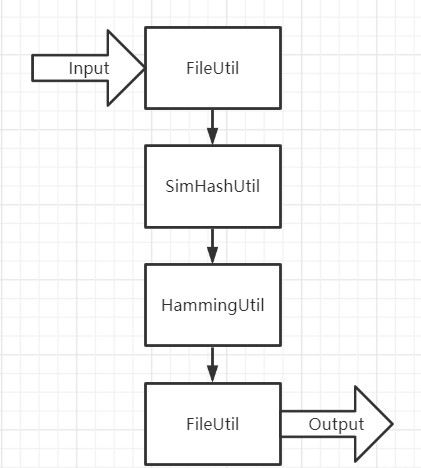
个人项目作业 -
算法关键及独到之处
经过资料搜集(参考链接:javascript:void(0) ),发现 SimHash 局部敏感哈希算法相比其他常见算法对长文本的相似度检测更加理想,故最终确定采用它作为核心算法。

个人项目作业 算法的独到之处还在于采用了当下比较成熟的 HanLP 汉语言处理包(HanLP官网)用于文本分词,在面对混杂在 html 标签中的文本时,也能有效排除噪声词提取出词语。除此以外,还采用了 MD5 加密算法生成数字签名,以及通过计算 Hamming 距离作为衡量文本相似度的指标。
本程序的“加权”操作比较简单粗暴,仅仅只是遍历出各个词语并按顺序赋权,个人认为更进阶的一步是根据词频(遍历统计,词频越高则权重越高)或者根据词性(借助HanLP包的分析词性功能并自己定义规则,让名词、动词等实义词赋予更高的权重)进行更合理的赋权,奈何时间不允许,只好作罢。
以下为实现该算法的关键函数的流程图。
个人项目作业
3. 计算模块接口部分的性能
-
性能分析图(由性能分析工具 JProfiler 自动生成)
从分析结果可以看出,浮点运算、分词和处理字符串占用了最多资源。对于分词操作我能做出的改变很少,只能尽量选用最新、最先进的分词工具。而针对浮点运算和字符串处理,我观察到程序当中有很多需要循环的地方,所以我的改进思路是尽可能简化或者拆分浮点运算和字符串处理,将公共运算提到循环体之外,从而减少运算次数。
个人项目作业 个人项目作业
4. 计算模块部分单元测试展示
-
部分单元测试代码展示
构造数据的思路主要是从正常情况和异常情况两方面来考虑的,正常情况是指论文原文与各抄袭版论文逐一比较,异常情况主要是指传入参数不合理的情况。
test 文件夹除了增加了 UnitTest 单元测试类,其余结构与 main 文件夹中的正式代码结构完全相同,UnitTest 类中的各个测试方法通过调用同文件夹下 Main 包的 main() 方法进行测试。
个人项目作业 package com.similarity.main; import org.junit.Test; public class UnitTest { //获取当前项目路径 public static final String PATH = System.getProperty("user.dir")+"/src/test/resources/"; /** 传入参数个数不正确 */ @Test public void test0_1(){ String[] args = { // PATH + "test/orig.txt", PATH + "test/orig_0.8_add.txt", PATH + "out/ans.txt" }; Main.main(args); } /** 传入的文件路径不存在 */ @Test public void test0_2(){ String[] args = new String[3]; args[0] = PATH + "test/abc.txt"; args[1] = PATH + "test/orig_0.8_add.txt"; args[2] = PATH + "out/ans.txt"; Main.main(args); } /** test包内文件检测 */ @Test public void test1_1(){ String[] args = new String[3]; args[0] = PATH + "test/orig.txt"; args[1] = PATH + "test/orig_0.8_add.txt"; args[2] = PATH + "out/ans1_1.txt"; Main.main(args); } /** test2包内文件检测 */ @Test public void test2_1(){ String[] args = new String[3]; args[0] = PATH + "test2/orig.txt"; args[1] = PATH + "test2/orig_0.8_add.txt"; args[2] = PATH + "out/ans2_1.txt"; Main.main(args); }
-
测试覆盖率
没有覆盖到的代码行主要是捕获异常的部分。
个人项目作业
5. 计算模块部分异常处理说明
- FileUtil.readFile()该方法集中捕获了 IOException,其中包括了 UnsupportedEncodingException、FileNotFoundException。
- FileNotFoundException 的主要出现场景:用户输入了不存在的文件输入路径。(见测试用例 test0_2)
个人项目作业 - IOException 的主要出现场景:reader 读取字符输入流时出现异常情况,如流为空时。
- UnsupportedEncodingException:经过测试,字符集名“ UTF-8 ”确认无误,一般情况下不会抛出该异常。
个人项目作业
- FileUtil.writeFile()该方法集中捕获了 IOException,其中包括了 FileNotFoundException。
- FileNotFoundException 的主要出现场景:用户输入了不存在的文件输出路径。(同见测试用例 test0_2,此处不再附图)
- IOException 的主要出现场景:创建文件方法 createNewFile() 失败时;文件输出流写入、刷新、关闭操作出现异常时。
个人项目作业
-
SimHashUtil.hash()
该方法直接捕获了Exception,其中包括了 java.security.NoSuchAlgorithmException 和 java.io.UnsupportedEncodingException。经过测试,算法名“ MD5 ”和字符集名“ UTF-8 ”确认无误,一般情况下不会抛出以上异常。
个人项目作业