背景:
在使用阿里云OpenSearch过程中发现官方SDK存在以下问题:
- 搜索条件设置需要拼接字符串来实现,不太友好;
- 搜索返回结果是字符串类型,需要业务自己解析;
- 应用结构schema只能hard coding;
- 有一定的学习成本,比如某种类型的索引查询语法有哪些限制。
改进思路:
封装一个starter,具有以下功能:
- 自动根据OpenSearch的应用结构schema生成代码(查询条件类和返回结果类);
- 搜索条件的封装使用流式API的方式,隐藏复杂性;用API引导用户对语法有差异的索引或属性字段设置查询或过滤条件。
接入步骤:
引入SDK包:
<dependency>
<groupId>com.github.zougeren</groupId>
<artifactId>fluent-search-processor</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency> 工程本地新建一个工具类,使用如下方式生成代码:
package com.aliyun.gts.xaccount.user.util;
import com.aliyun.opensearch.sdk.generated.commons.OpenSearchClientException;
import com.aliyun.opensearch.sdk.generated.commons.OpenSearchException;
import com.google.common.collect.Lists;
import java.io.IOException;
/**
* @author zouge
*/
public class FluentSearchGenerator {
public static void main(String[] args) throws OpenSearchClientException, OpenSearchException, IOException, ClassNotFoundException {
com.github.zougeren.fluent.search.processor.util.FluentSearchGenerator.builder()
//配置opensearch公网接入点
.host("http://opensearch-cn-zhangjiakou.aliyuncs.com")
//填入ak和sk,注意只是临时填写,生成完代码之后一定删掉,不要提交到git里!
.accessKey("")
.accessSecret("")
//设置要生成哪些应用的代码,可以配置完整的应用名称,也可以配置*通配符
//比如目前我这边应用命名规则是库名_表名,则可以配置"dayu_xaccount_*"来生成账号库涉及的所有应用代码
.appNames(Lists.newArrayList("dayu_xaccount_*"))
//生成代码放在哪个包
.basePkg("com.aliyun.gts.xaccount.user.search")
//生成代码放在哪个模块
.srcDir("xuser-platform/user-core/src/main/java")
.build()
.generate();
}
} 运行之后,每个应用会生成两个类:
XxxSearchParam: 这个是搜索条件的封装;
XxxSearchResult: 这个是搜索返回结果的封装;
其中Xxx表示OpenSearch控制台中的应用名称。
应用增加配置:
fluent:
search:
#目前仅支持openSearch,后续支持es等
engine: openSearch
#配置ak和sk
openSearchAccessKey:
openSearchAccessSecret:
#openSearch接入点
openSearchHost: http://opensearch-cn-shanghai.aliyuncs.com 开始搜索:
@Autowired
private OpenSearchClient openSearchClient;
public void test(){
//此处省略了param的详细构造过程,可参考下方示例
ZougetestSearchParam param = new ZougetestSearchParam();
Page<ZougetestSearchResult> search = openSearchClient.search(param);
int pageNo = search.getPageNo();
int pageSize = search.getPageSize();
long total = search.getTotal();
List<ZougetestSearchResult> data = search.getData();
} XxxSearchParam详细语法示例:
我建了一个测试应用,应用名称:zougetest(starter本身支持多表关联,这里为了测试方便我只建了主表),包含了OpenSearch目前支持的所有类型:
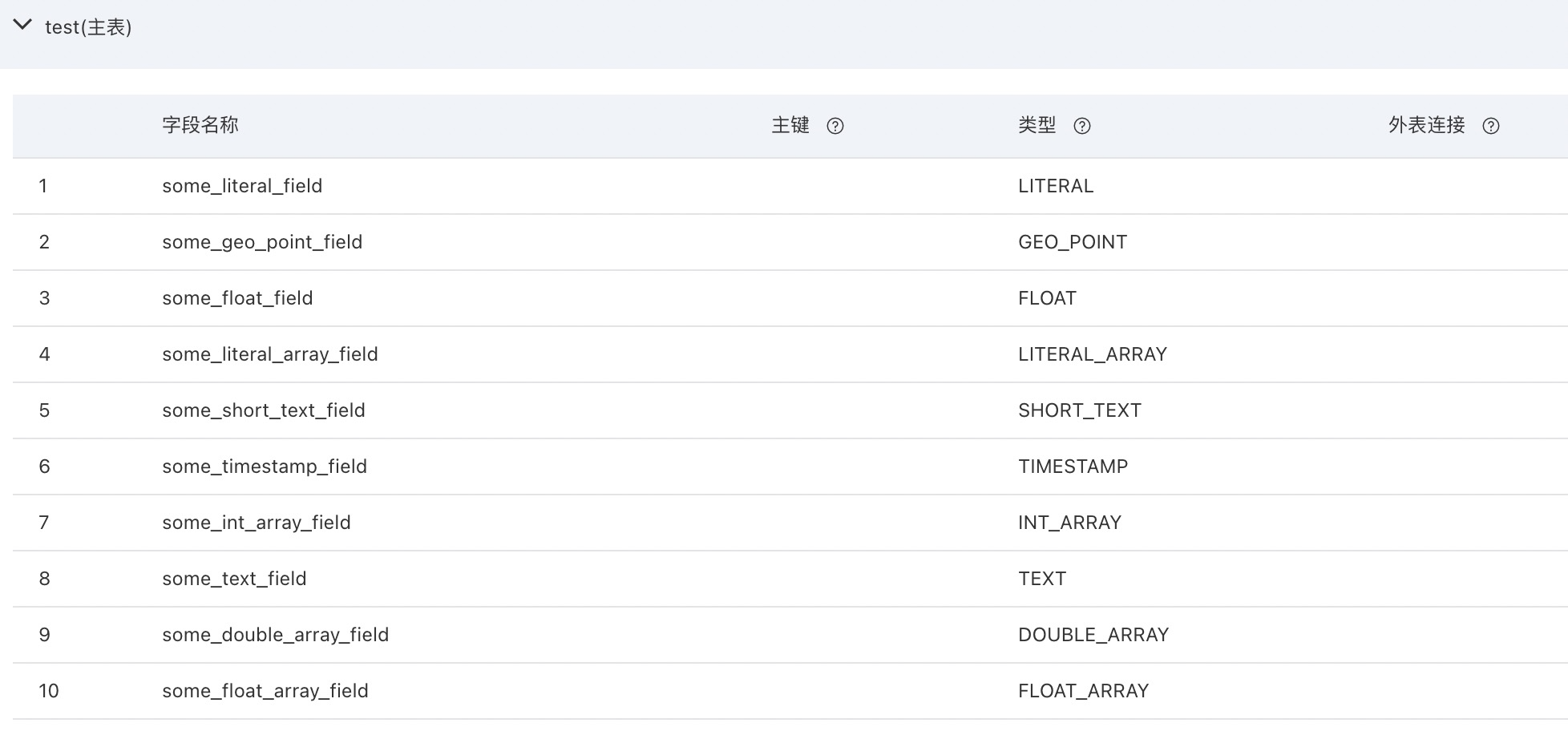
所有可建立索引的字段均建立索引,some_int_field当使用关键字或数值分析时,query子句语法会不同,所以我建了两个索引方便测试:

所有可设置为属性字段的均设置为属性字段:
示例代码:
ZougetestSearchParam param = new ZougetestSearchParam()
//查询所有字段
.selectAll()
//或者指定要查询哪些字段,以end结束
.select.someIntField().someFloatField().end
//query子句,每个索引字段都有 andXxx() orXxx() andNotXxx() rankXxx() 四个方法,表示四种连接符
//主要分为四类:关键字分析、地理位置分析、数值分析、其他分析
.where
//关键字分析
//.rankId()
//.orSomeIntArrayField()
//.andNotSomeLiteralArrayField()
.andSomeLiteralField()
//AND some_literal_field:'hh' 每个方法都有一个含有Predicate的重载版本,后续示例不再赘述
.equal("hh", Objects::nonNull)
//AND some_literal_field:'hehe'|'haha' 当前字段继续增加条件,则连接符保持和上一步的一致
.in(Lists.newArrayList("hehe", "haha"))
//以end结束当前索引字段的条件
.end
//地理位置分析
.orSomeGeoPointField()
//OR some_geo_point_field:'point(50 51)'
.point(50d, 51d)
//OR some_geo_point_field:'circle(50 51,1000)'
.circle(50d, 51d, 1000)
//OR some_geo_point_field:'rectangle(51 52,53 54)'
.rectangle(51d, 52d, 53d, 54d)
.end
//其他分析
//.rankSomeTextField()
.rankSomeShortTextField()
//RANK some_short_text_field:'haha'
.like("haha")
//RANK some_short_text_field:'heh'|'haha'
.likes(Lists.newArrayList("heh", "haha"))
//RANK some_short_text_field:"hehe"
.phaseLike("hehe")
//RANK some_short_text_field:"heh"|"haha"
.phaseLikes(Lists.newArrayList("heh", "haha"))
.end
//数值分析
//.andSomeIntField()
.andSomeTimestampField()
//AND some_timestamp_field:[-9223372036854775808,123]
.le(123L)
//AND some_timestamp_field:[123,9223372036854775807]
.ge(123L)
//AND some_timestamp_field:[-9223372036854775808,123)
.lt(123L)
//AND some_timestamp_field:(123,9223372036854775807]
.gt(123L)
//AND some_timestamp_field:[12,23]
.rangeAllInclusive(12L, 23L)
//AND some_timestamp_field:(12,23)
.rangeAllExclusive(12L, 23L)
//AND some_timestamp_field:(12,23]
.rangeLeftExclusiveRightInclusive(12L, 23L)
//AND some_timestamp_field:[12,23)
.rangeLeftInclusiveRightExclusive(12L, 23L)
.end
//实际使用场景中,四个操作符的优先级可能大家不一定记得清楚,会使用()定义优先级,所以这里有额外的四个方法来生成带括号的嵌套查询
//and() or() andNot() rank()
.and(query -> query.andSomeIntField().gt(123).end
.orId().equal(123).end)
//结束query子句,生成queryStr时.where后紧跟的第一个条件和所有括号中的第一个条件的连接符会被trim掉
.end
//filter子句,每个属性字段都有 andXxx() orXxx() 两个方法,表示两种连接符
//主要分为四类:数字、数字数组、字符串、字符串数组
.filter
//数字
//.andSomeTimestampField()
//.andSomeIntField()
//.andSomeDoubleField()
.andSomeFloatField()
//AND some_float_field>123
.gt(123)
//AND some_float_field>=123
.ge(123)
//AND some_float_field<123
.lt(123)
//AND some_float_field<=123
.le(123)
//AND some_float_field=123
.equal(123)
//AND in(some_float_field,"123|345")
.in(Lists.newArrayList(123, 345))
//AND some_float_field!=123
.notEqual(123)
//AND notin(some_float_field,"123|345")
.notIn(Lists.newArrayList(123, 345))
.end
//数字数组
//.andSomeGeoPointField()
//.andSomeDoubleArrayField()
//.andSomeIntArrayField()
.orSomeFloatArrayField()
//OR some_float_array_field=123
.equal(123)
//OR some_float_array_field!=123
.notEqual(123)
//OR (some_float_array_field=123 OR some_float_array_field=345)
.in(Lists.newArrayList(123, 345))
//OR (some_float_array_field!=123 AND some_float_array_field!=345)
.notIn(Lists.newArrayList(123, 345))
.end
//字符串
.andSomeLiteralField()
//AND some_literal_field="haha"
.equal("haha")
//AND some_literal_field!="haha"
.notEqual("hehe")
//AND in(some_literal_field,"heh|jaj")
.in(Lists.newArrayList("heh", "jaj"))
//AND notin(some_literal_field,"e|a")
.notIn(Lists.newArrayList("e", "a"))
.end
//字符串数组
.andSomeLiteralArrayField()
//AND some_literal_array_field="haha"
.equal("haha")
//AND some_literal_array_field!="hah"
.notEqual("hah")
//AND (some_literal_array_field="hah" OR some_literal_array_field="heh")
.in(Lists.newArrayList("hah", "heh"))
//AND (some_literal_array_field!="a" AND some_literal_array_field!="e")
.notIn(Lists.newArrayList("a", "e"))
.end
//同样支持嵌套查询 and() or()
.and(filter -> filter.andSomeFloatField().le(123).end
.orSomeDoubleField().gt(123).end)
//结束filter子句,生成filterStr时.filter后紧跟的第一个条件和所有括号中的第一个条件的连接符会被trim掉
.end
//排序,支持自定义列名
.orderBy("some_float_field").desc().end
//或者根据具体字段排序
.orderBy.someDoubleArrayField().asc().someDoubleField().desc().end
//分页参数
.limit(1, 10); 目前还有一些高级的查询没有封装好,如果仅仅想使用结果自动转javaBean,而查询条件仍然使用原生的SDK,则可以使用第二个方法:
com.github.zougeren.fluent.search.processor.client.OpenSearchClient#search(com.aliyun.opensearch.sdk.generated.search.SearchParams, java.lang.Class<R>)
第二个参数传入对应的XxxSearchResult
后续规划:
其他高级用法(aggregate、distinct、scroll查询、底纹、热搜、下拉选)的封装还在开发中,欢迎交流~