TiDB
是
PingCAP
公司设计的开源分布式
NewSQL
数据库。由于它兼容
MySQL
协议,并支持绝大多数
SQL
功能(比如
joins
,
subqueries
,
transaction
等)。业务能够直接通过
MySQL connector
去使用它来替换
MySQL
。
TiDB
适合场景:
- 数据量大,
MySQL
Online DDL
-
MySQL
Sharding
- 有高并发实时写入、实时查询、实时统计分析的需求。
- 有分布式事务、多数据中心的数据
100%
auto-failover
TiDB
与
MySQL
相比,有什么优势,让它更适合上述场景?接下来将从以下六个方面进行对比。
1. TiDB
SQL
TiDB
SQL
MySQL
水平扩展一般是主从复制,典型的就是一主多从模式。但这种只适合读多写少的业务。碰到大写入量的业务,这种模式反而会成为瓶颈。那么就必须寻求其他的分布式方案,有以下两种思路:
- 基于修改
MySQL
MySQL
Server
InnoDB
MySQL
Plan
- 基于中间件方式的分布式方案,比如 ProxySQL 。做一款中间件需要考虑很多,比如通过解析
SQL
ShardKey
ShardKey
Session
Transaction
Join
Plan
Subqueries
ShardKey
ORM
以上
MySQL
的问题是由传统架构模式本身带来的,而
TiDB
的模式是不一样的。它在
TiDB Server
层实现了分布式的SQL引擎,依赖
TiKV
来提供分布式存储和
分布式事务支持,分布式的设计也方便做水平扩展。以上
MySQL
分布式方案带来的问题,
TiDB
都能做很好的解决,这是架构本身带来的优势。
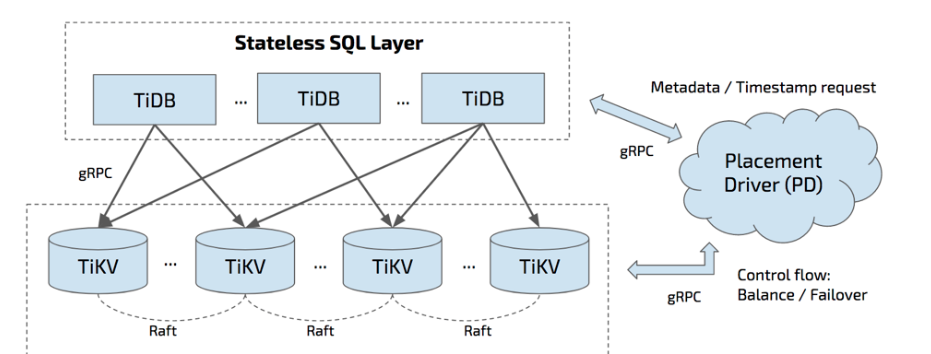
如上图所示,
TiDB
集群主要分为以下三个组件:
-
TiDB Server
TiDB Server
SQL
SQL
PD
TiKV
TiKV
TiDB Server
LVS
HAProxy
F5
-
PD Server
Placement Driver
PD
Key
TiKV
Raft group leader
ID
-
TiKV Server

TiDB原理解析系列(一)---Why Do We Use it?
TiKV Server
负责存储数据,从外部看
TiKV
是一个分布式的提供事务的
Key-Value
存储引擎。存储数据的基本单位是
Region
,每个
Region
负责存储一个
Key Range
(从
StartKey
到
EndKey
的左闭右开区间)的数据,每个
TiKV
节点会负责多个
Region
TiKV
使用
Raft
协议做复制,保持数据的一致性和容灾。副本以
Region
为单位进行管理,不同节点上的多个
Region
构成一个
Raft Group
。数据在多个
TiKV
之间的负载均衡由
PD
调度,是以
Region
为单位进行调度。
2. TiDB
TiDB
MySQL
的复制方式是半同步或者是异步,半同步也可以降级成异步。也就是说任何时候数据出了问题是不敢切换的,因为有可能是异步复制,有一部分数据还没有同步过来,这时候切换数据就不一致了。多数据中心的复制和数据中心的容灾,
MySQL
在这上面是做不好的。
而
TiDB/TiKV/PD
的三个组件都能容忍部分实例失效,并且不影响整个集群的可用性,支持
跨中心部署下面分别说明这三个组件的单个实例失效后的服务状态,以及如何进行恢复。
-
TiDB Server
TiDB Server
-
PD Server
PD
Raft
Raft
leader
Raft
leader
Raft leader
PD
PD
-
TiKV Server
TiKV
Raft
PD
Region
Region
Leader
Region
Follower
TiKV
10
PD
TiKV
3. TiDB
RocksDB
TiDB
RocksDB
MySQL
默认存储引擎从2010年起就一直是
InnoDB
InnoDB
B+
树数据结构,这与传统的商业数据库相似。
TiDB
RocksDB
作为
TiKV
的存储引擎。
读写性能的测试对比:
-
RocksDB
InnoDB-Compress
70%
RocksDB
InnoDB-Compress好
InnoDB
-
RocksDB
QPS
InnoDB-Compress
10
RocksDB
优势是在于处理大型数据集,因为它可以更有效地压缩数据并且插入数据性能优秀。
6亿4千万数据导入
MySQL
InnoDB
未经压缩大小为
160GB
InnoDB-Compress
为
86GB
RocksDB
62GB
TiDB
更加适合大规模数据场景。数据条数少于
5000w
的场景下通常用不到
TiDB
,单机
MySQL
能满足的场景也不需要用到
TiDB
4. TiDB
Online DDL
TiDB
Online DDL
业务发展迅速,应用模式频繁更改是常态。相应地,数据库访问模式和
Schema
也随之变化。
DDL
SQL
的一类,主要作用是创建和更改数据的
Schema
信息,最常见的操作包括:加减列、更改列类型、加减索引等。
5.6
版本以后,
MySQL
内部开始支持
Online DDL
。但
MySQL
Online DDL
方案始终没有解决下面问题:
MySQL
主备副本之间通过
Binlog
同步,主的
Schema
变更成功后,才会写
BinLog
同步给备库,然后备库才开始做
DDL
。假设一个
DDL
变更需要一个小时,那么备库最多可能会延迟两倍的变更时间。若变更期间,主库发生故障,备库数据还未追平,则无法提供服务的。
TiDB
Google F1
论文介绍的协议实现
在线DDLTikv
基本不感知
DDL
操作。对于
Tikv
来说,所有的操作都是
PUT/GET/DELETE
,所以副本间的变更也与普通
DML
没有差异。任何时候,只要底层
raft
协议能正常
work
,三副本高可用和强一致就能得到保证。这个方案虽然
Schema
变更比较麻烦,但对于
Tikv
存储层特别友好,不用感知
DDL
,共用一套机制保证高可用和强一致。不会出现类似
MySQL
主备延迟和主备
Schema
不一致问题。
DDL
更改也被分解成更小的转换阶段,这样它们可以防止数据损坏场景,并且系统允许单个节点一次最多支持一个
DDL
版本。
5. TiDB
HTAP
TiDB
HTAP
MySQL
团队把注意力放在优化联机事务处理(
OLTP
)查询的性能上。也就是说,
MySQL
团队花费更多的时间使简单查询执行得更好,而不是使所有或复杂查询执行得更好。这种方法没有错,因为许多应用程序只使用简单的查询。
TiDB
设计目标在处理混合事务/分析处理(
HTAP
)的性能上。对于那些希望对数据进行实时分析的应用来说,这是一个主要的卖点,因为它消除了在
MySQL
数据库和分析数据库之间进行的批量加载。一份存储同时处理
OLTP & OLAP
,无需传统繁琐的
ETL
过程。
6. TiDB
TiDB
这一点对运维非常友好。
MySQL
将关键监控指标放在内存表中,获取它需要通过
SQL
查询,可视化与告警部分都需要额外开发。而TiDB提供
Metrics接口,使用
Prometheus
记录组件中各种操作的详细信息,使用
Grafana
进行可视化展示。无须其他开发额外,根据需要,即可配置定制化自己的监控图表和报警。
总结
在替代
MySQL
的场景中,
TiDB
MySQL
相比更加适合大数量的场景;同时也补充了
MySQL
的不足,比如处理
Online DDL
问题;在
MySQL
不适合的场景中,比如
HTAP
场景中也能发挥很好的优势。如果你想更多了解
TiDB
作者的初衷,参阅
How do we build TiDB Meet TiDB: An open source NewSQL database