k8s高可用架构解析
Kubeadm基本环境配置
Kubeadm系统及内核升级
Kubeadm基本组件安装
Kubeadm高可用组件安装
Kubeadm集群初始化
高可用Master及Token过期处理
Kubeadm Node及Calico节点配置
Dashboard&Metrics Server安装
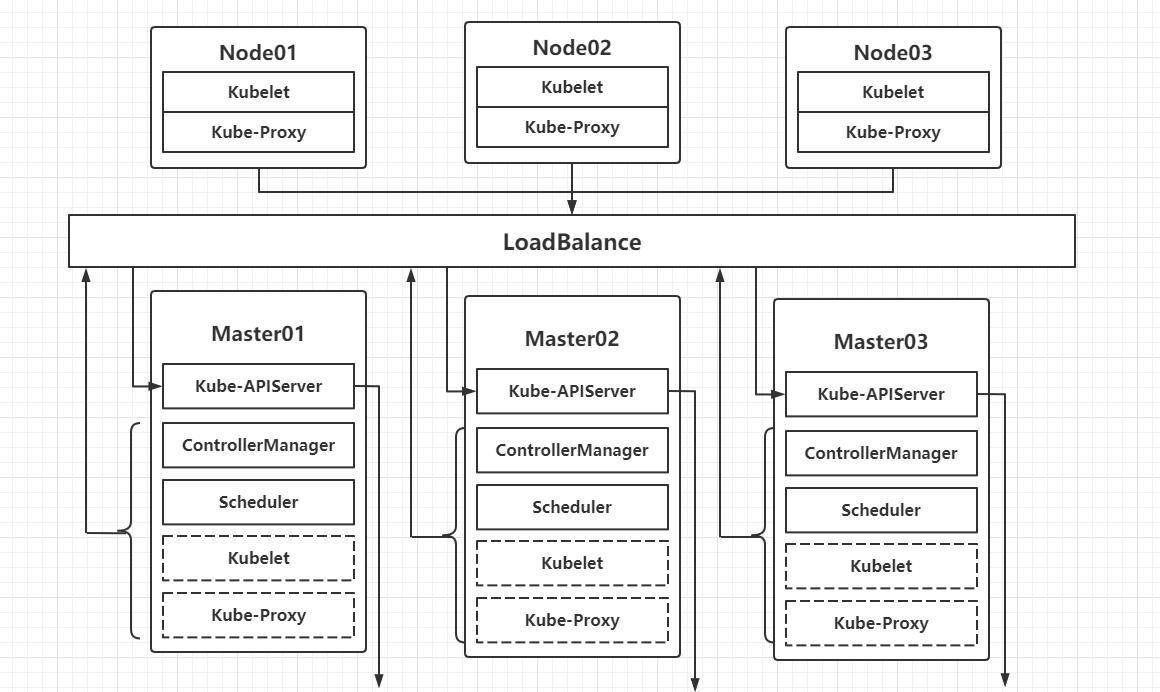
Etcd Cluster:键值数据库,存放k8s的数据,比如我们创建的资源,所做的变更
Master:控制节点,控制整个集群
Node:主要用来跑pod和容器
Kube-APIServer:它是整个k8s的控制大脑,所有的流量都会经过APIServer
ControllerManager:集群的控制器
Scheduler:集群的调度器,控制pod调度到哪一个node节点
Load Balancer:负载均衡,一般使用nginx + keepalived,或者keepalived + haproxy,如果有硬件资源如f5,就不需要Load Balancer,通过虚拟IP连接
Kubeadm 是官方推荐的安装方式,但是生产环境推荐使用二进制的方式安装
Kubeadm 证书的有效期是一年,因为官方建议运行一年的过程中必须要升级一次
主机名
IP地址
说明
k8s-master01 ~ 03
192.168.232.128 ~ 130
master节点 * 3
k8s-master-lb
192.168.232.236
keepalived虚拟IP
k8s-node01 ~ 02
192.168.232.131 ~ 132
worker节点 * 2
配置信息
备注
Pod网段
172.168.0.0/12
Service网段
10.96.0.0/12
VIP(虚拟IP)不要和公司内网IP重复,首先去ping一下,不通才可用。VIP需要和主机在同一个局域网内
公有云上搭建VIP是公有云的负载均衡的IP,比如阿里云的内网SLB的地址,腾讯云内网ELB的地址
环境搭建
静态ip设置
节点配置
不要使用带中文的服务器和克隆的虚拟机
安装虚拟机:https://www.cnblogs.com/mr-xiong/p/12468280.html
下载centos-7镜像:https://zhuanlan.zhihu.com/p/104118123
三台master节点,两台node节点,每台虚拟机分配2核2G,存储使用20G硬盘

安装完成后启动并通过Xshell 7连接五台虚拟机
Xshell 7下载地址:https://downloadly.net/2020/15/4832/03/xmanager/01/?#/4832-netsaran-122140071106.html
使用Xshell 7可以同时发送命令到所有会话,菜单栏--工具--发送键输入到所有会话
通过 VMware 菜单栏编辑,虚拟网络编辑器查看子网地址,192.168.232.0
打开目录
修改文件 ifcfg-ens33
重启网络服务
查看当前IP地址
根据集群规划分别设置五台虚拟机静态ip,设置完成后使用 Xshell 7 连接到五台虚拟机
Xshell 7 切换tab快捷键:ctrl + tab
所有节点配置hosts,修改/etc/hosts如下:
CentOS 7安装yum源如下:
必备工具安装
所有节点关闭防火墙、selinux、dnsmasq、swap。服务器配置如下:
查看config文件,SELINUX被设为disabled
关闭swap分区
注释后重启服务器,swap分区就不会再打开
安装ntpdate,保证五台服务器时间一致,云服务器不需要
所有节点同步时间。时间同步配置如下:
所有节点配置limit:
设置limit永久生效
取消发送键输入到所有会话
Master01节点免密钥登录其他节点,安装过程中生成配置文件和证书均在Master01上操作,集群管理也在Master01上操作,阿里云或者AWS上需要单独一台kubectl服务器。密钥配置如下:
下载安装所有的源码文件:
无法下载的可以通过本地拉取压缩再上传到服务器
yum安装zip
解压文件
所有节点(发送键输入到所有会话)升级系统并重启,此处升级没有升级内核,下节会单独升级内核:
推荐centos7,因为CentOS8在2021年停止维护,而centos7到2024年才停止维护
重启完成之后,查看版本(CentOS Linux release 7.9.2009 (Core))
查看内核版本
内核3.10版本使用docker会有一些bug,需要升级
CentOS7 需要升级内核至4.18+,本地升级的版本为4.19
在master01节点(取消发送键输入到所有会话)下载内核:
从master01节点传到其他节点:
所有节点(发送键输入到所有会话)安装内核
所有节点更改内核启动顺序,因为默认是3.10的
检查默认内核是不是4.19
所有节点重启,然后检查内核是不是4.19
所有节点安装ipvsadm:
所有节点配置ipvs模块,在内核4.19+版本nf_conntrack_ipv4已经改为nf_conntrack, 4.18以下使用nf_conntrack_ipv4即可:
加载配置
开启一些k8s集群中必须的内核参数,所有节点配置k8s内核:
所有节点配置完内核后,重启服务器,保证重启后内核依旧加载
检查是否加载
所有节点安装Docker-ce 19.03,不需要太新,这是官方已经经过验证的版本
由于新版kubelet建议使用systemd,所以可以把docker的CgroupDriver改成systemd
所有节点设置开机自启动Docker:
查看docker版本(Server Version: 19.03.15,Cgroup Driver: systemd)
查看k8s最新版本(取消发送键输入到所有会话):
最新版本是1.21.2-0,但是推荐小版本大于5才使用,所以安装1.20版本
所有节点(发送键输入到所有会话)安装最新版本kubeadm:
默认配置的pause镜像使用gcr.io仓库,国内可能无法访问,所以这里配置Kubelet使用阿里云的pause镜像:
设置Kubelet开机自启动:
如果不是高可用集群,haproxy和keepalived无需安装
公有云要用公有云自带的负载均衡,比如阿里云的SLB,腾讯云的ELB,用来替代haproxy和keepalived,因为公有云大部分都是不支持keepalived的
如果用阿里云的话,kubectl控制端不能放在master节点,因为阿里云的slb有回环的问题,也就是slb代理的服务器不能反向访问SLB,推荐使用腾讯云,腾讯云修复了这个问题。
所有Master节点(node节点取消发送键输入到所有会话)通过yum安装HAProxy和KeepAlived:
所有Master节点配置HAProxy(详细配置参考HAProxy文档,所有Master节点的HAProxy配置相同):
删除所有内容
添加以下内容,注意首行global是否复制完整
所有Master节点配置KeepAlived,配置不一样,注意每个节点的IP和网卡(interface参数)
查看网卡名称(ens33)
如果网卡名称不是ens33,不要把配置文件中的网卡配置替换
Master01节点的配置:
添加以下内容,注意首行是否复制完整
Master02节点的配置:
Master03节点的配置:
所有master节点(发送键输入到所有会话,取消node节点)配置KeepAlived健康检查文件:
我们通过KeepAlived虚拟出来一个VIP,VIP会配置到一个master节点上面,它会通过haproxy暴露的16443的端口反向代理到我们的三个master节点上面,所以我们可以通过VIP的地址加上16443访问到我们的API server
健康检查会检查haproxy的状态,三次失败就会将KeepAlived停掉,停掉之后KeepAlived会跳到其他的节点
添加权限
启动haproxy
查看端口(16443)
启动keepalived
查看系统日志(Sending gratuitous ARP on ens33 for 192.168.232.236)
查看ip
可以看到192.168.232.236绑定到了master01,其他两个节点是没有的
测试VIP
如果ping不通且telnet没有出现 ] ,则认为VIP不可以,不可在继续往下执行,需要排查keepalived的问题
比如防火墙和selinux,haproxy和keepalived的状态,监听端口等
所有节点查看防火墙状态必须为disable和inactive:systemctl status firewalld
所有节点查看selinux状态,必须为disable:getenforce
master节点查看haproxy和keepalived状态:systemctl status keepalived haproxy
master节点查看监听端口:netstat -lntp
官方初始化文档:https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/high-availability/
在生产环境中有些配置需要修改,因为使用默认的配置可能会导致网段冲突,所以我们使用配置文件的形式初始化
发送键输入到所有会话
Master01节点创建 kubeadm-config.yaml 配置文件如下:
Master01:(# 注意,如果不是高可用集群,192.168.232.236:16443改为master01的地址,16443改为apiserver的端口,默认是6443,注意更改v1.18.5自己服务器kubeadm的版本:kubeadm version)
以下文件内容,宿主机网段、podSubnet网段、serviceSubnet网段不能重复,具体看前面的高可用Kubernetes集群规划
更新kubeadm文件
查看kubeadm版本(GitVersion:"v1.20.8")
将配置文件中的 kubernetesVersion: v1.20.0 改为一致的 kubernetesVersion: v1.20.8
node节点取消发送键输入到所有会话
将new.yaml文件复制到其他master节点,之后所有Master节点提前下载镜像,可以节省初始化时间:
因为配置了阿里云镜像(imageRepository: registry.cn-hangzhou.aliyuncs.com/google_containers),所以下载速度比默认使用的gcr镜像快,国内访问不了gcr镜像
因为配置了token过期时间(ttl: 24h0m0s),所以可能出现今天生成token,明天加入不了集群的问题
同时master节点为我们配置了一个污点(taints),这个污点可以让我们的mater不部署容器
criSocket就是通过哪一个socket连接我们的docker,dockershim在k8s 1.20版本废弃,官方不维护,后期可能有人会维护,也可以改成其他cri的runtime
Master01节点(取消发送键输入到所有会话)初始化,初始化以后会在/etc/kubernetes目录下生成对应的证书和配置文件,之后其他Master节点加入Master01即可:
kubeadm 的配置管理是通过 pod 管理的,所有的组件都是通过容器启动的,通过 /etc/kubernetes/manifests 目录下面的 yaml 文件启动,这就是 kubelet 生命周期管理的目录,在这里面配置一个 pod 的 yaml 文件,它就会为你管理 pod 的生命周期
进入到该目录中
可以看到以下文件
kubeadm 与二进制安装不一样的地方在于它的配置管理都在 yaml 文件中,可以编辑文件查看,二进制是一个单独的server文件,如果更改了配置,千万不要手动让它生效,kubelet 会自动帮我们加载配置,重启容器
如果初始化失败,重置后再次初始化,命令如下:
初始化成功以后,会产生Token值,用于其他节点加入时使用,因此要记录下初始化成功生成的token值(令牌值):
Master01节点配置环境变量,用于访问Kubernetes集群:
管理集群的命令 kubectl 只需要在一个节点上面有就可以,这个节点可以是 k8s 节点,也可以不是,它就是通过 admin.conf 文件和 k8s 通讯的,文件中定义了一个变量 KUBECONFIG,指定了文件的地址,然后我们就可以操作我们的集群了
查看节点状态:
可以看到它添加了一个规则 control-plane
查看server:
可以看到以下的server
采用初始化安装方式,所有的系统组件均以容器的方式运行并且在kube-system命名空间内,生产环境建议创建一个namespaces
此时可以查看Pod状态:
可以看到以下的pod
注意:以下步骤是上述init命令产生的Token过期了才需要执行以下步骤,如果没有过期不需要执行
Token过期后生成新的token:
Master需要生成--certificate-key
Token没有过期直接执行Join
初始化master02加入集群
在master01查看其他节点
可以看到master02节点
尝试重新生成token
替换参数,初始化master03加入集群
可以在master01查看新生成的token
这就是新生成的token
查看token内容:
可以看到过期时间(这是通过base64加密的):
解密一下:
可以看到解密后的时间
Node节点上主要部署公司的一些业务应用,生产环境中不建议Master节点部署系统组件之外的其他Pod,测试环境可以允许Master节点部署Pod以节省系统资源。
初始化node01,node02加入集群(与master相比,不需要control-plane)
所有节点初始化完成后,查看集群状态
可以看到所有节点
以下步骤只在master01执行
如果是本地下载上传的话需要现在本地切换分支再上传
修改calico-etcd.yaml的以下位置:
修改etcd的节点
使用默认配置
把 etcd_key 放到 secret 里面,secret 会挂载到 calico 容器的 pod 里面,挂载的名称就是 ETCD_CA,这样 calico 就能找到证书,就可以连接到 etcd,就可以把 pod 信息存储到 etcd 里面
修改 pod 网段
注意下面的这个步骤是把calico-etcd.yaml文件里面的CALICO_IPV4POOL_CIDR下的网段改成自己的Pod网段,也就是把192.168.x.x/16改成自己的集群网段,并打开注释,所以更改的时候请确保这个步骤的这个网段没有被统一替换掉,如果被替换掉了,还请改回来:
检查文件:
可以看到 etcd-key 已经导入进来,它就是把证书 /etc/kubernetes/pki/etcd/ca.crt 读取出来,再经过 base64 加密,再填到这个位置
安装 calico
查看容器状态
成功运行
目前用的是阿里云的镜像,生产环境需要推荐使用自己的镜像仓库,这样速度更快
在新版的Kubernetes中系统资源的采集均使用Metrics-server,可以通过Metrics采集节点和Pod的内存、磁盘、CPU和网络的使用率。
github 地址:https://github.com/kubernetes-sigs/metrics-server
查看yaml文件配置
添加了证书,不然可能导致获取不到度量指标
镜像地址也修改为阿里云
将Master01节点的front-proxy-ca.crt复制到所有Node节点
安装metrics server
查看状态
显示CPU状态,内存使用量
Dashboard用于展示集群中的各类资源,同时也可以通过Dashboard实时查看Pod的日志和在容器中执行一些命令等。
github 地址:https://github.com/kubernetes/dashboard
可以看到只修改了镜像地址
注意:所有的镜像包括caclico, coredns, etcd等等都要放到自己公司内部的镜像仓库,这样发布、更新、故障恢复的速度更快
安装
如果需要访问最新版本可以访问官方github获取连接,但是没必要安装最新
创建管理员用户vim admin.yaml
应用
在谷歌浏览器(Chrome)启动文件中加入启动参数,用于解决无法访问Dashboard的问题
右键--属性--快捷方式--目标
更改dashboard的svc为NodePort:
将ClusterIP更改为NodePort(如果已经为NodePort忽略此步骤)
查看端口号:
端口号为10.99.156.65
查看容器是否启动完成
根据自己的实例端口号,通过任意安装了kube-proxy的宿主机或者VIP的IP+端口即可访问到dashboard:
访问Dashboard:https://192.168.232.236:32272(请更改32272为自己的端口),选择登录方式为令牌(即token方式)
也可以通过宿主机的ip访问:https://192.168.232.128:32272
查看端口占用
占用情况
可以看到 NodePort 所做的事情就是在宿主机上启动一个端口号 32272,这个端口号会对应到 dashboard,每一台服务器都会启动这个端口,都可以访问到 dashboard
查看token值:
得到token值:
将token值输入到令牌后,单击登录即可访问Dashboard
切换 namespace 到 kube-system
将Kube-proxy改为ipvs模式,因为在初始化集群的时候注释了ipvs配置,所以需要自行修改一下:
在master01节点执行
搜索定位到mode
修改为 ipvs
保存退出:shift + z + z
更新 Kube-Proxy 的 Pod:
查看 pod 滚动更新
可以看到新起的是在 master03
在 master03 验证 Kube-Proxy 模式,接着可以在所有服务器验证一下
kubeadm安装的集群,证书有效期默认是一年。master节点的kube-apiserver、kube-scheduler、kube-controller-manager、etcd都是以容器运行的。可以通过kubectl get po -n kube-system查看。
kubelet的配置文件在/etc/sysconfig/kubelet和/var/lib/kubelet/config.yaml,修改后需要重启kubelet进程
其他组件的配置文件在/etc/kubernetes/manifests目录下,比如kube-apiserver.yaml,该yaml文件更改后,kubelet会自动刷新配置,也就是会重启pod。不能再次创建该文件
kube-proxy的配置在kube-system命名空间下的configmap中,可以通过
进行更改,更改完成后,可以通过patch重启kube-proxy
Kubeadm安装后,master节点默认不允许部署pod,会占用资源,在学习过程中可以通过以下方式打开:
查看Taints:
可以看到三个污点
删除Taint:
http://www.kubeasy.com/
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
欢迎转载、使用、重新发布,但务必保留文章署名 郑子铭 (包含链接: http://www.cnblogs.com/MingsonZheng/ ),不得用于商业目的,基于本文修改后的作品务必以相同的许可发布。