在PyTorch中,autograd是所有神经网络的核心内容,为Tensor所有操作提供自动求导方法。
它是一个按运行方式定义的框架,这意味着backprop是由代码的运行方式定义的。
autograd.Variable 是autograd中最核心的类。 它包装了一个Tensor,并且几乎支持所有在其上定义的操作。一旦完成了你的运算,你可以调用 .backward()来自动计算出所有的梯度。
Variable有三个属性:data,grad以及creator。
访问原始的tensor使用属性.data; 关于这一Variable的梯度则集中于 .grad; .creator反映了创建者,标识了是否由用户使用.Variable直接创建(None)。
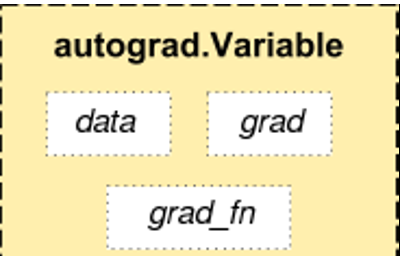
还有一个对autograd的实现非常重要的类——Function。Variable 和Function数是相互关联的,并建立一个非循环图,从而编码完整的计算过程。每个变量都有一个.grad_fn属性引用创建变量的函数(除了用户创建的变量,它们的grad_fn是None)。
创建变量x:
输出结果:
在x基础上进行运算:
输出结果:
<code>查看x的</code>grad_fn:
<code>查看y的</code>grad_fn:
<code>可以看到y是作为运算的结果产生的,所以y有</code><code>grad_fn,而x是直接创建的,所以x没有grad_fn。</code>
在y基础上进行运算:
<code>如果Variable是一个标量(例如它包含一个单元素数据),你无需对backward()指定任何参数.</code>
<code>out.backward()</code>等价于<code>out.backward(torch.Tensor([1.0])).</code>

如果它有更多的元素(矢量),你需要指定一个和tensor的形状匹配的grad_output参数(y在指定方向投影对x的导数)
不传入参数:
传入参数:
简单测试一下不同参数的效果:
参数1:[1,1,1]
参数2:[3,2,1]