详细的题目要求和资源可以到 http://csapp.cs.cmu.edu/3e/labs.html 或者 http://www.cs.cmu.edu/~./213/schedule.html 获取。
在这个实验中我们需要实现自己的动态内存申请器(malloc、free、realloc)
完全阅读书本第9章
<code>man 3 realloc</code>
1.先从小的测试文件开始,例如short1-bal.rep
2.为了调试方便,在Makefile中将CFLAGS更改为:
这样用GDB调试的时候就能看到源码了
3.地址要对8字节对齐。
4.注意<code>realloc</code>的实现要和libc一致。
5.本实验环境WORD=4=sizeof(void *),DWORD=8(gcc -m32)
对于速度(thru)而言,我们需要关注malloc、free、realloc每次操作的复杂度。对于内存利用率(util)而言,我们需要关注internal fragmentation (块内损失)和 external fragmentation (块是分散不连续的,无法整体利用),即我们free和malloc的时候要注意整体大块利用(例如合并free块、realloc的时候判断下一个块是否空闲)。
我这里实现的是书上9.9.13和9.9.14提到的Explicit Free Lists + Segregated Free Lists + Segregated Fits ,详细的介绍参考书上写的。
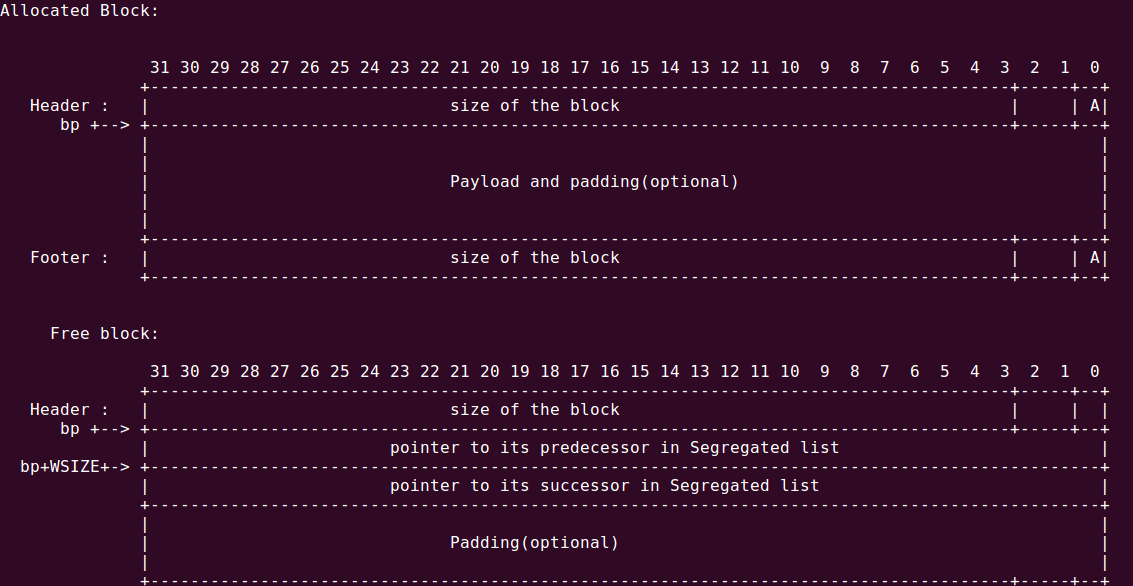
块的结构如下,其中低三位由于内存对齐的原因总会是0,A代表最低位为1,即该块已经allocated:
堆的起始和结束结构如下:

Free list的结构如下,每条链上的块按大小由小到大排列,这样我们用“first hit”策略搜索链表的时候就能获得“best hit”的性能,例如第一条链,A是B的successor,B是A的predecessor,A的大小小于等于B;不同链以块大小区分,依次为{1}{2}{34}{58}...{1025~2048}... :
更新:这里的箭头应该是双向的,画错了。
下面是各个模块的实现,**部分代码改编自CS:APP3e官网的Code examples 的mm.c(完整代码),如需使用请联系Randy Bryant and Dave O'Hallaron ** 。这次注释用中文写的,就不另外解释了。
常数及指针运算的宏定义
全局变量
Helper functions
Helper functions: extend_heap
Helper functions: insert_node
Helper functions: delete_node
Helper functions: coalesce
Helper functions: place
初始化堆 mm_init:
申请块:mm_malloc:
释放块:mm_free:
调整块:mm_realloc:
最终结果: