Python中有一些内置模块可以非常便捷地将json字符串转换为Python对象。比如json模块中的json.relaods()方法可以将json字符串解析为相应的字典。
<a></a>
运行结果:
要对json文件进行分析,首先我们逐行读取该文件,并把每行转换成对应的字典对象,然后组成一个列表。
{u'a': u'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.78 Safari/535.11', u'c': u'US', u'nk': 1, u'tz': u'America/New_York', u'gr': u'MA', u'g': u'A6qOVH', u'h': u'wfLQtf', u'cy': u'Danvers', u'l': u'orofrog', u'al': u'en-US,en;q=0.8', u'hh': u'1.usa.gov', u'r': u'http://www.facebook.com/l/7AQEFzjSi/1.usa.gov/wfLQtf', u'u': u'http://www.ncbi.nlm.nih.gov/pubmed/22415991', u't': 1331923247, u'hc': 1331822918, u'll': [42.576698, -70.954903]} America/New_York
[u'America/New_York', u'America/Denver', u'America/New_York', u'America/Sao_Paulo', u'America/New_York']
[(191, u'America/Denver'), (382, u'America/Los_Angeles'), (400, u'America/Chicago'), (521, u''), (1251, u'America/New_York')]
Python标准库collections对一些数据结构进行了拓展操作,使用起来更加便捷,其中defaultdict可以给字典赋值默认value。
#运行结果:[(u'America/New_York', 1251), (u'', 521), (u'America/Chicago', 400), (u'America/Los_Angeles', 382), (u'America/Denver', 191)]
①DataFrame是pandas中很常用的数据结构,它把数据转换为一个类似表格的结构。
0 America/New_York 1 America/Denver 2 America/New_York 3 America/Sao_Paulo 4 America/New_York
②frame['tz']有value_counts()函数,可以直接返回对应的计数。
#打印出现次数最多的5个时区
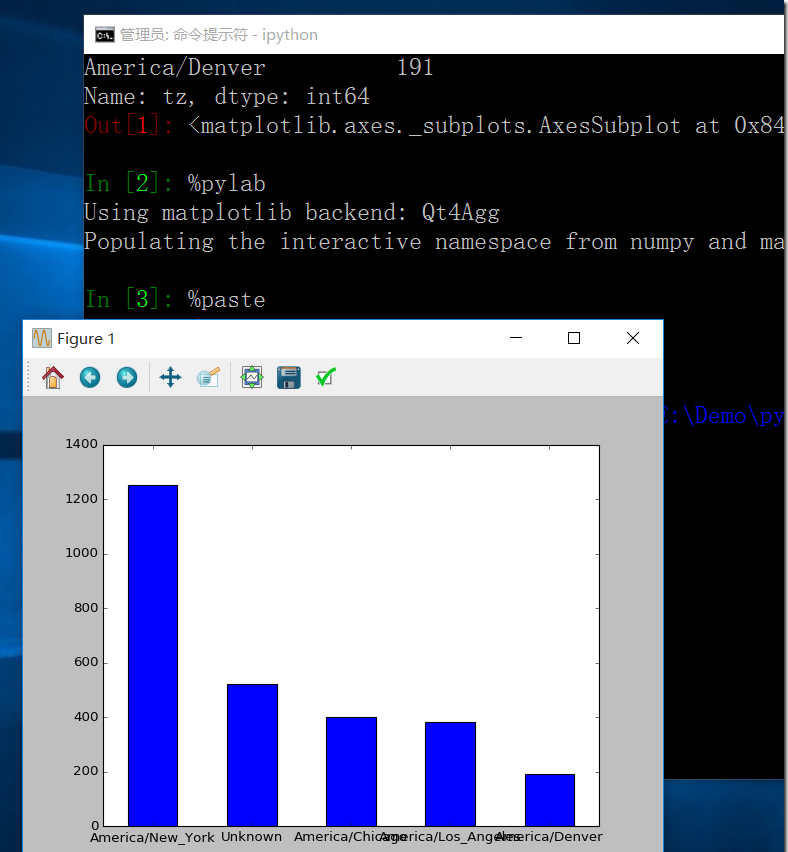
America/New_York 1251 521 America/Chicago 400 America/Los_Angeles 382 America/Denver 191
③为不存在时区数据或者时区为空字符串的数据补全默认值。
fillna()函数可以补全不存在的字段;空字符串可以通过布尔型索引的形式进行替换。
Unknown 521
这样我们就完成了之前用标准Python库相同的工作,完整代码如下:
tzList.value_counts()[:5].plot(kind='bar',rot=0)
运行:我们可以利用%paste命令将代码粘贴运行。
命令行:
参考:《利用Python进行数据分析》
本文转自 陈敬(Cathy) 博客园博客,原文链接:http://www.cnblogs.com/janes/p/5546673.html,如需转载请自行联系原作者
![27. Remove Element(列表)题目代码[图]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)