说道大数据和机器学习,就少不了Spark.本文主要介绍在Linux下搭建单机环境的Spark的步骤。
1、下载JAVA SE linux版本。下载地址为:
http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
注意选择Linux版本,根据机器类型选择32位或者64位。
2、下载jdk-8u131-linux-x64.tar.gz后,解压到自己指定目录。
3、配置JAVA环境变量。
打开.bashrc文件。
在.bashrc文件末尾增加如下内容:
保存后退出,运行如下命令,使修改环境变量即可生效:
4、检测java是否成功安装。
如果显示了java安装的版本,则表示已正确安装,可以进行下一步了。
1、下载Scala的压缩文件。下载地址为:
http://www.scala-lang.org/download/
2、下载scala-2.12.2.tgz后,解压到指定的目录:
3、配置scala环境变量。
4、检测scala是否正确安装。
若显示如上信息,则表示scala已安装正确。
1、下载Spark的压缩文件。下载地址为:
http://spark.apache.org/downloads.html
2、下载spark-2.1.1-bin-hadoop2.7.tgz后,解压到指定的目录:
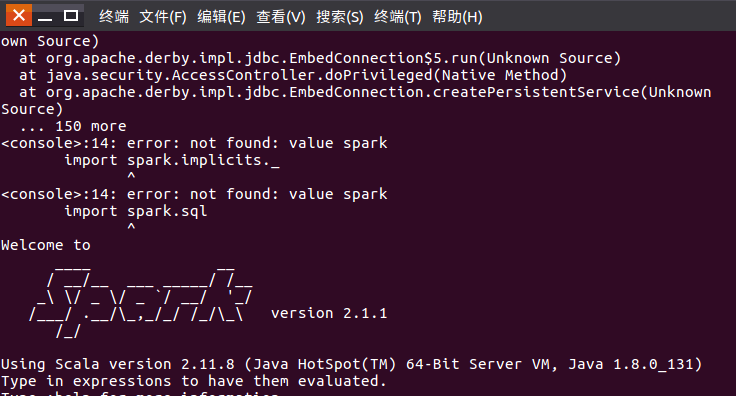
4、检测spark是否正确安装。
如果出现如下界面,则表示spark已正确安装:
http://www.scala-sbt.org/download.html
2、下载sbt-0.13.15.tgz后,解压到指定的目录:
3、配置sbt环境变量。
4、建立启动sbt的脚本。
脚本内容如下,注意sbt-launch.jar的路径
修改sbt文件的权限
5、检测sbt是否正确安装。
第一次执行的时候会下载很多东西,不用管它,后来就好了。
如果出现sbt的版本信息就表示安装成功。
至此,Linux下Spark单机环境已经成功搭建完毕!