本文的目的:分享一下在学校的时候分析shell源码的一些收获,帮助大家了解shell的一个工作流程,从软件设计的角度,看看shell这样一个历史悠久的软件的一些设计优点和缺陷。本文重点不是讲SHELL语法,相信很多同事玩shell都很熟了。
本文的局限:限于本人技术水平和时间,肯定有不少错误和遗漏的地方,在当时的源码注释的过程中,也确实会有一直都不理解和存疑的地方,还请指正。但总的来说,主要逻辑和流程还是可以理清的。
分析的版本:首先选用最常用的bash,然后版本是bash4.2-release
bash代码简介:之前做过一个统计,shell源码大概有10万行,其中核心逻辑在1万多行,这也是分析的目标代码。剩下的包括引入的readline库(也是个开源库,处理输入的),yacc语法分析器生成工具(开源库,相信很多学过编译原理的都知道这东西),以及很多为提高用户界面友好性做得优化和辅助代码(比如!的历史操作)。
建议:在了解shell运行机制的同时,从软件设计的角度来看他,会发现有很多可以优化和改进的地方(当然,因为shell本身是从比较久远的年代发展而来,各种历史因素相关),特别是,读了下面内容的同学应该可以发现,命令解析那一块,用C++的OO思想可以合理的设计命令的类层次结构,大大简化代码量和逻辑,有兴趣的同学甚至可以自己动手写来试试替换掉这一部分。
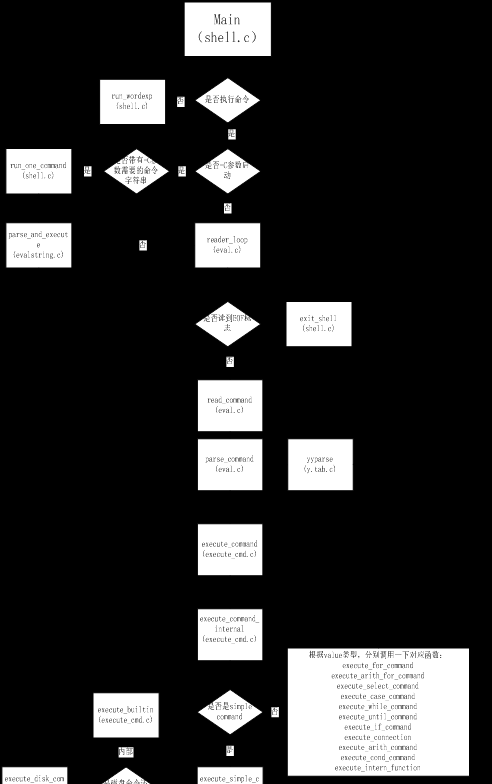
<code>shell.c</code>是shell主函数main所在文件。因此shell的启动可以认为从<code>shell.c</code>文件开始。main函数完成的主要工作流程是包括:检查启动的运行环境(是否通过sshd启动,是否运行于emacs环境下,是否运行于cgywin环境下,是否是交互式shell,是否是login shell等,对系统进行内存泄露检查,是否是受限shell),读取配置文件(顺序为<code>/etc/profile and</code>( <code>~/.bash_profile OR ~/.bash_login OR ~/.profile</code>)前面的存在不会读后面的),设置运行需要的全局变量的值(当前环境变量、shell的名称、启动时间、输入输出文件描述符、语言本地化的相关设置),处理参数和选项(即带有<code>-c -s --debugger</code>等参数和选项),设置参数和选项的值(<code>run_shopt_alist ()</code>函数调用<code>shopt_setopt</code>函数设置选项的值;绑定$位置参数的值),然后根据不同的启动参数进入以下不同分支:
如果是只进行参数扩展而不执行命令,调用<code>run_wordexp</code>函数扩展参数,然后调用<code>exit_shell</code> (<code>last_command_exit_value</code>)函数以上次命令执行的返回值为返回值退出。
如果是以-c参数模式启动shell,分为两种情况:一:如果是附带了字符串参数作为要执行的命令,则调用<code>run_one_command (command_execution_string)</code>执行-c附带的命令,参数<code>command_execution_string</code>保存-c后面附带的字符串命令值。执行完毕后调用<code>exit_shell (last_command_exit_value)</code>退出。二:如果是期待用户输入要执行的命令,则跳转到分支3。
将<code>shell_initialized</code>置为1表示shell初始化完成。调用<code>eval.c</code>中定义的函数<code>reader_loop()</code>不断的读取和解析用户输入,如果<code>reader_loop</code>函数返回,则调用<code>exit_shell</code>、<code>(last_command_exit_value)</code>退出shell。
shell中用如下结构体来表示一个命令。
其中一个很关键的成员是联合union类型value,它指出了该命令的类型,也给出了保存命令具体内容的指针。从该结构的可选值来看,shell定义的命令共有for循环、case条件、while循环、函数定义、协同异步命令等14种。
其中,经过对所有命令执行路径的分析,确定类型为simple的command是经过命令替换后的最原子的命令操作,其余类型的命令都是由若干simple command构成的。
在shell启动之后,无论是进入上面的2和3两个分支中的哪一个,最后解析命令所用到的函数都是<code>execute_cmd.c</code>中定义的函数。分支1不涉及到命令的解析,所以不在这里分析。
run_one_command (command_execution_string) 执行的过程中调用<code>parse_and_execute</code> (在evalstring.c中定义)解析与执行命令,<code>parse_and_execute</code>中实际调用<code>execute_command_internal</code>函数进行命令的执行。
<code>reader_loop</code>函数调用<code>read_command</code>函数解析命令,<code>read_command</code>函数调用<code>parse_command()</code>函数进行语法分析,<code>parse_command()</code>调用语法分析器y.tab.c中的yyparse()(该函数由yyac自动生成,因此不再往函数内部跟进),将解析结果的命令字符串保存在全局变量<code>GLOBAL_COMMAND</code>中,然后执行<code>execute_command</code>函数(定义在<code>execute_cmd.c</code>中),<code>execute_command</code>函数再调用<code>execute_command_internal</code>函数进行命令的执行。至此分支2和分支3的情况又合并到<code>execute_command_internal</code>的执行上。
该函数是shell源码中执行命令的实际操作函数。他需要对作为操作参数传入的具体命令结构的value成员进行分析,并针对不同的value类型,再调用具体类型的命令执行函数进行具体命令的解释执行工作。
具体来说:如果value是simple,则直接调用<code>execute_simple_command</code>函数进行执行,<code>execute_simple_command</code>再根据命令是内部命令或磁盘外部命令分别调用<code>execute_builtin</code>和<code>execute_disk_command</code>来执行,其中,<code>execute_disk_comman</code>d在执行外部命令的时候调用<code>make_child</code>函数fork子进程执行外部命令。
如果value是其他类型,则调用对应类型的函数进行分支控制。举例来说,如果是value是<code>for_commmand</code>,即这是一个for循环控制结构命令,则调用<code>execute_for_command</code>函数。在该函数中,将枚举每一个操作域中的元素,对其再次调用<code>execute_command</code>函数进行分析。即<code>execute_for_command</code>这一类函数实现的是一个命令的展开以及流程控制以及递归调用<code>execute_command</code>的功能。
因此,从main函数启动到命令执行的主要流程图可以表现为下图所示:
括号内为函数定义所在的文件。
BASH中主要通过变量上下文和变量两个结构体来描述一个变量结构。以下分别介绍。
变量上下文:上下文又可以理解为作用域,可以比照C语言中的函数作用域,全局作用域来理解。一个上下文中的变量都是在这个上下文中可见的。
变量上下文结构定义:
描述一个变量的作用域的结构体。一个上下文中的所有变量,存放在var_context的table成员中。
变量:bash中的变量不强调类型,可以认为都是字符串。其存储结构如下
由于所有变量笼统的由字符串来表示,因此提供了attributes属性成员来修饰变量的特性,比如属性可以是<code>att_readonly</code>表示只读,<code>att_array</code>表示是数组变量,<code>att_function</code>表示是个函数,<code>att_integer</code>表示是整型类变量等等。
shell程序的执行伴随着一个个上下文的切换,shell源码中的变量控制也是基于这一点。将变量绑定于一个一个的上下文中。
举例来说,一开始默认存在的是全局上下文,这里称为global,其中包含有由main函数的参数或者配置文件传入的变量值。如果这时进入了一个函数foo的执行中,则foo先从全局上下文获取要导出的变量,加上自己新增的变量,构成foo的上下文局部变量,将foo的上下文压入调用栈。这时调用栈看起来如下所示。
栈顶 :foo上下文(包含foo上下文的所有局部变量)
栈底:global全局上下文(包含所有全局变量)
为了解释更详细的情况,假设在foo中又调用了fun函数,则fun先从foo中获取要导出的变量,加上自己新增的变量,构成fun的上下文局部变量,然后将fun的上下文压入调用栈的栈顶
。这是调用栈看起来如下所示。
栈顶 :fun上下文(包含fun上下文的所有局部变量)
栈中 :foo上下文(包含foo上下文的所有局部变量)
此时假设fun函数执行完毕,则将fun上下文从栈中pop出,局部变量全部失效。调用栈又变成如下所示。
变量的查找顺序:从栈顶往栈底,即如果栈顶上下文中没有要查找的变量,则查找其在栈中的下一个上下文,如果整个调用栈查找完毕也没有找到,则查找失败。举例来说,如果在栈顶上下文中有PWD变量(当前工作路径),就不会去查找全局的PWD变量,这保证了局部变量覆盖的正确语义。
bash中定义了若干特殊变量,特殊变量的意思是在该变量被修改后需要做一些额外的连贯工作。比如表示时区的变量TZ被修改了之后需要调用tzset函数修改系统中相应的时区设置。bash给这一类变量提供了一个回调函数接口,供其值发生改变的情况下来调用该回调函数。这可以类比数据库中的触发器机制。在bash中,特殊变量保存在一个全局数组<code>special_vars</code>中。其定义如下:
该结构表示一个特殊变量结构,用于生成specialvars数组。回调函数一般是sv变量名的命名方式。