运用共享技术有效的支持大量细粒度的对象
假设开发了一款简单的游戏:玩家们在地图上移动并进行相互射击。大量的子弹、导弹和爆炸弹片在整个地图上穿行,为玩家提供紧张刺激的游戏体验。但是,运行了几分钟后,游戏因为内存容量不足而发生了崩溃。研究发现,每个粒子(一颗子弹、 一枚导弹或一块弹片)都由包含完整数据的独立对象来表示。当玩家在游戏中鏖战进入高潮后的某一时刻,游戏将无法在剩余内存中载入新建粒子,于是程序就崩溃了
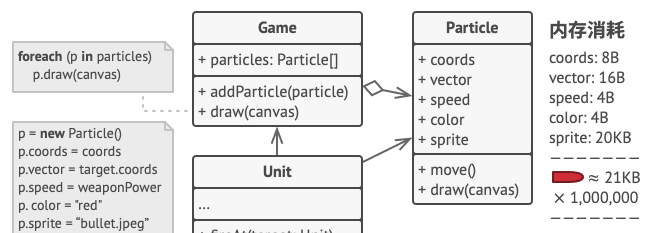
仔细观察粒子Particle类,会注意到颜色(color)和精灵图(sprite)这两个成员变量所消耗的内存要比其他变量多得多。另外,对所有例子来说,这两个成员变量所存储的数据几乎完全一样 (比如所有子弹的颜色和精灵图都一样)。每个粒子的另一些状态 (坐标、 移动矢量和速度)则是不同的,因为这些成员变量的数值会不断变化。内在状态存储于flyweight中,它包含了独立于场景的信息,这些信息使得flyweight可以被共享。而外部状态取决于flyweight场景,并根据场景而变化,因此不可共享。用户对象负责在必要的时候将外部状态传递给Flyweight

程序需要生成巨大的相似对象,以至于消耗目标对象的所有内存
对象中包含可抽取且能在多个对象间共享的重复状态
使用FlyWeight模式时,传输、查找和/或计算外部状态都会产生运行时开销,尤其当flyweight原先被存储为内部状态时。然而,空间上的节省抵消了这些开销。共享的flyweight越多,空间节省越大
存储节约由以下因素决定:
1. 由于共享带来的实例总数减少的数量
2. 对象内部状态的平均数量
3. 外部状态是计算的还是存储的
共享的flyweight越多,存储节约的也就越多。节约量随着共享状态的增多而增大。当对象使用大量的内部及外部状态,并且外部状态是计算出来的而非存储的时候,节约量将达到最大
如果渲染一片森林 (1,000,000 棵树)!每棵树都由包含一些状态的对象来表示 (坐标和纹理等)。 尽管程序能够完成其主要工作,但很显然它需要消耗大量内存。因为,太多树对象包含重复数据 (名称、 纹理和颜色)。因此我们可用享元模式来将这些数值存储在单独的享元对象中 (TreeType类)。现在我们不再将相同数据存储在数千个 Tree对象中,而是使用一组特殊的数值来引用其中一个享元对象。客户端代码不会知道任何事情, 因为重用享元对象的复杂机制隐藏在了享元工厂中
trees/Tree.java: 包含每棵树的独特状态
trees/TreeType.java: 包含多棵树共享的状态
trees/TreeFactory.java: 封装创建享元的复杂机制
forest/Forest.java: 我们绘制的森林
Demo.java: 客户端代码
运行结果
可以使用享元模式实现组合模式树的共享叶节点以节省内存
享元展示了如何生成大量的小型对象,外观模式则展示了如何用一个对象来代表整个子系统
如果你能将对象的所有共享状态简化为一个享元对象,那么享元就和单例模式类似了。但这两个模式有两个根本性的不同:
1. 只会有一个单例实体,但是享元类可以有多个实体,各实体的内在状态也可以不同
2. 单例对象可以是可变的。享元对象是不可变的
java.lang.Integer#valueOf(int) (以及 Boolean、Byte、Character、Short、Long 和 BigDecimal)
识别方法:享元可以通过构建方法来识别,它会返回缓存对象而不是创建新的对象