在机器学习里面,常见的预测算法有以下几种:
简易平均法:包括几何平均法、算数平均法及加权平均法;
移动平均法:包括简单移动平均法和加权移动平均法;
指数平滑法:包括一次指数平滑法和二次指数平滑法,以及三次指数平滑法;
线性回归法:包括一元线性回归和二元线性回归。
本篇博客,笔者将为大家主要介绍多元线性回归的相关内容。
线性回归是基础且广泛使用的预测分析算法,它允许在数字输入和输出值之间建立关系(不能用于分类数据)。简而言之,我们的目标是将复杂形式显示的实际值显示为如下图中的单线。
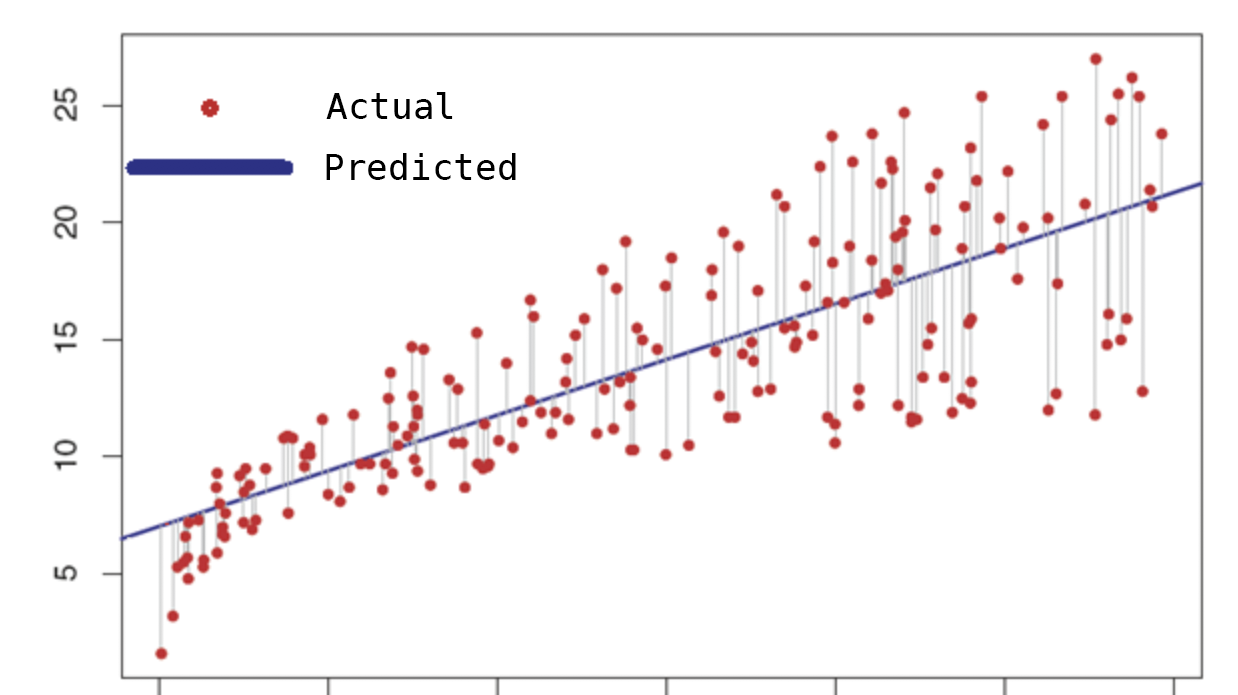
具有一个因变量和一个自变量的回归方程的最简单形式由如下公式组成:
误差量是真实值中的点与直线之间的距离。
例如,下面我们通过一个案例,读取一个包含按月销售额的文件,将进行线性回归月销售额的预测,代码如下所示:
执行上述代码,结果显示如下:

多元线性回归是使用最广发的线性回归分析。在一元线性回归中,它使用了一个因变量和一个自变量。在多元线性回归中可以与多个独立变量一起使用。
例如,在线性回归中,我们按月预测销售量。在多元线性回归中,我们可以根据体重、年龄和身高数据估算鞋子的大小。因此,此时体重、年龄和身高是自变量。
年龄
身高
体重
性别
20
175
82
m
35
182
65
f
45
168
73
32
176
42
虚拟变量可以定义为表示变量的另一个变量,比如上面性别列使用OneHotEncoder从类别数据转换为数值数据。如下所示:
1
转换之后,我们将列数从4列增加到了6列。OneHotEncoder结果包含在m和f列中,但是,如果我们将此数据集直接提供给机器学习算法,则我们的结果可能是错误的,因为这6列中的3列(性别、m、f)本质是相同的,也就是说,其中一个的更改会影响另一个列值。
为了避免这种情况,我们必须减去3列中的两列(性别、m、f),并将数据集提供给机器学习算法。裁剪后的数据列表如下所示:
P值即概率,反应某一时间发生的可能性大小。统计学根据显著性检验方法所得到的P值,一般以P小于0.05为显著,P小于0.01为非常显著,其含义是样本间的差异由抽样误差所致的概率小于0.05或者0.01。在线性回归中,P小于0.01(或者0.05)表示两个变量非常显著线性相关。
下面,我们通过执行示例代码,通过获取年龄、国家、性别和体重数据,并尝试预测人的身高。代码如下所示:
执行结果如下:
每个变量都会系统产生影响,有些变量对系统有很大影响,而有些则较少。消除对系统影响很小的自变量,使我们可以构建更好的模型。我们可以使用向后淘汰方法创建更好的模型。
选择P值(通常此值为0.05)
建立一个包含所有参数的模型
检查每个自变量的P值,如果P值大于为模型指定的值,则将从模型中删除此自变量,然后再次运行
如果所有P值都小于我们确定的值,那么我们的模型基本算准备就绪了
运行如下代码:
输出结果如下所示:
在图中,P > | t | 这一列是我们的P值,在x5对应的列高于我们确定的P值(0.05),接下来,将删除此列,然后再次运行该程序,这个过程一直持续到 P > | t | 这列中所有值都小于P值为止。
数据有时是非线性的,在这种情况下,将使用多项式回归。
在上图公式中,h是多项式的次数。它被称为h的二次方、三次方、四次方。
代码如下所示:
输出结果如下:
更改不同的度数参数后的结果如下所示:
需要注意的是,在非线性回归中,不可以用P值检验相关显著性,因为在非线性回归中,残差均值平方不再是误差方差的无偏估计,因为不能使用线性模型的检验方法来检验非线性模型,从而并不能用F统计量及其P值进行检验。
这篇博客就和大家分享到这里,如果大家在研究学习的过程当中有什么问题,可以加群进行讨论或发送邮件给我,我会尽我所能为您解答,与君共勉!
另外,博主出书了《Kafka并不难学》和《Hadoop大数据挖掘从入门到进阶实战》,喜欢的朋友或同学, 可以在公告栏那里点击购买链接购买博主的书进行学习,在此感谢大家的支持。关注下面公众号,根据提示,可免费获取书籍的教学视频。
<b></b><b></b><b></b><b></b>
联系方式:
Twitter:https://twitter.com/smartloli
QQ群(Hadoop - 交流社区1):424769183
QQ群(Kafka并不难学): 825943084
温馨提示:请大家加群的时候写上加群理由(姓名+公司/学校),方便管理员审核,谢谢!