本文将利用 TorchVision Faster R-CNN 预训练模型,于 Kaggle: 全球小麦检测 🌾 上实践迁移学习中的一种常用技术:微调(fine tuning)。
本文相关的 Kaggle Notebooks 可见:
TorchVision Faster R-CNN Finetuning
TorchVision Faster R-CNN Inference
如果你没有 GPU ,也可于 Kaggle 上在线训练。使用介绍:
Use Kaggle Notebooks
那么,我们开始吧 💪
Kaggle: 全球小麦检测 <code>Data</code> 页下载数据,内容如下:
train.csv - the training data
sample_submission.csv - a sample submission file in the correct format
train.zip - training images
test.zip - test images
读取 <code>train.csv</code> 内容:
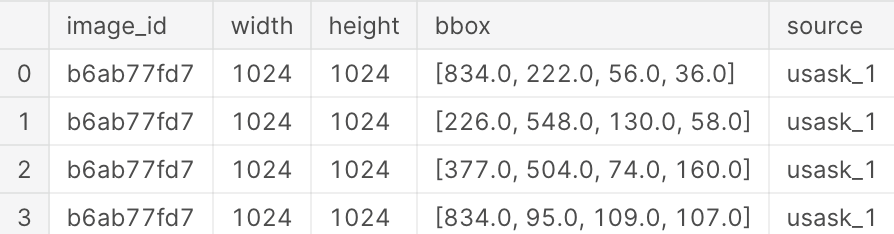
image_id - the unique image ID
width, height - the width and height of the images
bbox - a bounding box, formatted as a Python-style list of [xmin, ymin, width, height]
etc.
把 <code>bbox</code> 替换成 <code>x</code> <code>y</code> <code>w</code> <code>h</code>:

训练数据大小:
(147793, 8)
唯一 <code>image_id</code> 数量:
3373
<code>train</code> 目录下图片数量:
3423
说明有 <code>3422-3373=49</code> 张图片没有标注。
训练数据,图片大小:
(array([1024]), array([1024]))
都是 <code>1024x1024</code> 的。
查看标注数量的分布情况:
number of boxes, range [1, 116]
一张图最多的有 <code>116</code> 个标注。
查看标注坐标和宽高的分布情况:
把数据集分为训练集和验证集,比例 <code>8:2</code>:
((122577, 10), (25216, 10))
定义下辅助函数:
预览图片,不加标注:
预览图片,加上标注:
继承 <code>torch.utils.data.Dataset</code> 抽象类,实现 <code>__len__</code> <code>__getitem__</code> 。且 <code>__getitem__</code> 返回数据为:
image: a <code>numpy.ndarray</code> image
target: a dict containing the following fields
<code>boxes</code> (<code>FloatTensor[N, 4]</code>): the coordinates of the <code>N</code> bounding boxes in <code>[x0, y0, x1, y1]</code> format, ranging from <code>0</code> to <code>W</code> and <code>0</code> to <code>H</code>
<code>labels</code> (<code>Int64Tensor[N]</code>): the label for each bounding box
<code>image_id</code> (<code>Int64Tensor[1]</code>): an image identifier. It should be unique between all the images in the dataset, and is used during evaluation
<code>area</code> (<code>Tensor[N]</code>): The area of the bounding box. This is used during evaluation with the COCO metric, to separate the metric scores between small, medium and large boxes.
<code>iscrowd</code> (<code>UInt8Tensor[N]</code>): instances with <code>iscrowd=True</code> will be ignored during evaluation.
albumentations 是一个优秀的图像增强的库,用它定义了 <code>train</code> <code>valid</code> 的转换方法。
现在创建 <code>train</code> <code>valid</code> 数据集:
预览下数据集里的图片:
创建一个 Faster R-CNN 预训练模型:
输出模型最后一层:
替换该层,指明输出特征大小为 <code>2</code>:
再次输出模型最后一层:
这里我们从头准备数据,再载入模型,进行预测。
用于提交结果的文件。一行内容,表示一个图片的预测结果。如下:
<code>ce4833752,0.5 0 0 100 100</code>
<code>image_id</code> <code>ce4833752</code> 的图片,预测出 <code>x y w h</code> <code>0 0 100 100</code> 处是小麦,置信度 <code>0.5</code>。如果有多个预测框,能空格分隔。
实例化测试数据集:
{'image_id': 'aac893a91', 'PredictionString': '0.9928 72 2 96 166 0.9925 553 528 123 203 0.9912 613 921 85 102 0.9862 691 392 125 193 0.9855 819 708 105 204 0.9842 356 531 100 88 0.982 586 781 100 119 0.9795 739 768 82 122 0.9779 324 662 126 160 0.9764 27 454 102 156 0.9763 545 76 145 182 0.9736 450 858 90 95 0.9626 241 91 137 146 0.9406 306 0 75 68 0.9404 89 618 128 80 0.9366 177 576 114 182 0.9363 234 845 144 91 0.9265 64 857 115 69 0.824 822 630 90 124 0.7516 815 921 134 100'}
这就是 baseline 了,可以试着继续调优 😊
TorchVision Instance Segmentation Finetuning Tutorial
Kaggle: Global Wheat Detection
Pytorch Starter - FasterRCNN Train
Global Wheat Detection: Starter EDA
GoCoding 个人实践的经验分享,可关注公众号!