什么是kafka:其实就是一个分布式的消息队列.
消息(message):把各个应用给kafka发送的内容称之为消息.
topic:不同类的消息被氛围不同的topic,一个topic类似于数据库的一个表.
partition:每个topic可以被分成多个partition.写消息到topic的时候会根据分发规则写到不同的partition,每个partition中是有序的,但是多个partition之间无法保证顺序
为什么使用partition ? 1.scalable 可以根据业务量扩展多partition 2.high availablity,partitions部署在多台机器可以防止单点故障
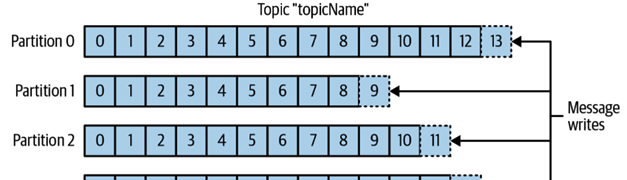
producer 消息生产者,consumer 消息消费者
producer生产的消息会根据预先设定的机制来决定发送到那个partition
consumer 可以订阅多个topic的多个partition,它是通过offset来判断是否已经取得了相应的消息。
consumer group:多个consumer还可以组成一个consumer group,1个partition只能被同一个consumergroup中的1个consumer来处理。当这个consumer出现问题后,可以让consumer group中的其他consumer来继续consume 对应的partition

kafka中的server即为broker,1.用来接受producer消息并增加offset 2.服务于consumer 处理consume request。 1个broker可以支持几千个partition,QPS可以达到百万
多个broker(server)就组成了1个cluster,其中一个broker(server)会被选举为controller,负责不同的partition assign给不同的broker 等。
为了高可用,partition level还可以有多个replica,leader+followers,跟数据库类似,写需要通过leader去写,但是读(consum)可以通过leader或者任一follower
kafka的消息可以持久保存,要保存多久可以在topic层级进行设置
有时会使用不同的cluster来隔离不同域的数据,但是不同域又有消息交互使用,那么就可以使用mirrormaker
1.支持多producer,多个应用可以给同一个或者不同的topic发送消息。
2.支持多consumer,可以多个consumer订阅同一个topic
3.消息磁盘持久化。
4.scalable 可以通过扩展partition/broker 增大处理能力
5.high available replica的存在确保了ha