操作系统:linux
调试工具:gdb
文章分为实验前准备、复习、拆炸弹三个模块。读者可以自取所需。
目录
Bomb Lab
实验前准备
复习
拆炸弹
phase_1
phase_2
phase_3
phase_4
phase_5
phase_6
secret_phase
结语
实验由<code>phase_1 ~ phase_6</code>组成,共6个阶段,
我们需要分别输入6个字符串密码,以便解除Dr. Evil的炸弹,
但只要有1个字符串输错,炸弹就会爆炸。
那么如何知道6个正确的字符串呢?
我们需要分别查看<code>phase_1 ~ phase_6</code>的汇编代码,
而炸弹就存放在其中,我们要根据汇编代码小心地避开炸弹,分析出正确的字符串即可。
而分析需要用到学习的汇编知识、常用的gdb指令以及linux终端指令。
需要用到的linux终端指令:
别忘了先进入文件地址中
<code>objdump -d bomb > assembly.s</code>
反编译出<code>bomb.c</code>的汇编代码,并存放在<code>assembly.s</code>中(assembly.s是自己命名的)
<code>gdb 文件名</code>
用gdb调试工具打开某个文件
eg. <code>gdb bomb</code> 用gdb调试工具打开bomb.c文件
而我们就是要用gdb调试工具打开bomb.c文件后做实验
常用gdb指令:
gdb指令必须用gdb调试工具打开文件后才能调用
<code>run</code> (可简写为:<code>r</code>)
运行文件。
<code>quit</code> (可简写为:<code>q</code>)
停止运行,跳出gdb调试工具
<code>break 函数名</code> (可简写为:<code>b 函数名</code>)
在某个函数处打断点,以便之后用disas展示这个函数的汇编代码。
eg. <code>b phase_1</code> 在phase_1函数打断点
<code>disas 函数名</code>
展示这个函数的汇编代码(但必须先打断点)
eg. <code>disas phase_1</code> 展示phase_1的汇编代码
<code>x/NFU address or register</code>
用指定格式(FU)、指定数量(N)输出地址或者寄存器对应内容
eg1. <code>x/s 0x40139b</code> 输出0x40139b对应内容
eg2. <code>x/s $rsi</code> 输出%rsi对应内容
eg3.<code>x/4xw 0x6032d0</code> 按24个十六进制4字节格式输出0x6032d0对应内容
<code>p/F *address or *register</code>
用指定格式(F)打印地址或者寄存器对应内容(效果上,<code>x/F = p/F</code>)
eg1. <code>p/x *(0x6032f0)</code> 按十六进制打印0x6032f0对应内容
格式F、单位U都与c语言类似,参考链接gdb:Format、Variables and Memory部分
测试和比较指令
- <code>ZF、OF、SF、CF</code>(条件码)
zero flag 零标志位;overflow flag 溢出标志位;sign flag 符号标志位;carry flag 进位标志位。
- <code>test S1,S2</code>即 <code>S1 & S2</code>
测试指令,进行位级与操作,若结果为0,返回<code>ZF = 1</code>;若结果非0,返回<code>ZF = 0</code>,但不会改变两个数的值。同时,需要特殊注意的是,可以对同一个寄存器使用test指令,例如<code>test %eax,%eax</code>。
- <code>cmp S1,S2</code>即<code>S2 - S1</code>
比较指令,进行减法操作,但不会改变两个数的值。
部分跳转指令
不区分unsiged(无符号)、siged(有符号)跳转
<code>jne</code>
根据ZF的值判断是否跳转,当<code>ZF = 0</code>才跳转。
<code>je</code>
根据ZF的值判断是否跳转,当<code>ZF = 1</code>才跳转。
siged jump 指令
<code>jle</code> (<code>jump<=</code>)
j:jump;l:less(小于);e:equal
<code>jge</code> (<code>jump<=</code>)
j:jump;g:great(大于);e:equal
<code>jg</code> (<code>jump></code>)
j:jump;g:great(大于)
unsiged jump 指令
<code>jb</code>(<code>jump<</code>)
j:jump;b:below(小于)
<code>jbe</code> (<code>jump<=</code>)
j:jump;b:below(小于);e:equal
<code>ja</code> (<code>jump></code>)
j:jump;a:above(大于)
<code>cmp</code>与signed jump、unsigned jump的联系(原理与条件码有关,在此不解释了)
当<code>cmp S1,S2</code>伴随signed jump指令使用时,S1置前,S2置后,例如:
当<code>cmp S1,S2</code>伴随unsigned jump指令使用时,S2置前,S1置后,例如:
部分二元操作
<code>lea S,D</code> (即<code>D <-- S</code>,等价于赋值算式<code>D = S</code>)
不是读取数据,是加载有效地址,但和<code>mov</code>指令效果相同,常用于执行简洁的算术操作。
<code>sub S,D</code> (即<code>D <-- D - S</code>,等价于赋值算式<code>D -= S</code>)
减法,D - S后赋值给D。
<code>sar S,D</code> (即<code>D <-- D >> S</code>,等价于赋值算式<code>D >>= S</code>)
算术右移,补符号位(sign),D >> S后赋值给D。注意:若<code>sar D</code>,则默认是算术右移<code>1</code>位。
<code>shr S,D</code> (即<code>D <-- D >> S</code>,等价于赋值算式<code>D >>= S</code>)
算术右移,补<code>0</code>,D >> S后赋值给D。
当寄存器为空时,其值为<code>0</code>
<code>%rdi</code>
系统往往要把一个值赋给%rdi后,才能当作入参(即输入的参数)
<code>register</code>
注意:汇编代码为了优化常常使用同一个系列的<code>register</code>表示同一个变量
例如:
register(64bits)
作用
%rax
存放返回值
%rbx
被调用者保存(存放被调用者的地址,可以是函数地址,也可以是其它地址,callee save)
%rcx
第4个参数(存储参数,可以是数字字符参数,也可以是地址参数)
%rdx
第3个参数
%rsi
第2个参数
%rdi
第1个参数(经常作入参使用)
%rbp
被调用者保存
%rsp
栈指针(用以开辟栈空间,注意入参的先进后出)
%r8
第5个参数
%r9
第6个参数
%10
调用者保存(存放调用者函数的地址,可以是函数地址,也可以是其它地址,caller save)
%r11
调用者保存
%r12
%r13
%r14
%r15
优化
有些看似毫无作用的汇编代码,其实是在做优化。
在正式拆炸弹之前需要注意到一点,我们输入的字符串都是放入到<code>%rdi</code>当中的。
(其实一般情况下,输入也是放到<code>%rdi</code>的)
也就是说,在每个<code>phase</code>调用时,默认<code>%rdi</code>这个寄存器存放着输入的字符串。
如何得到这点的呢?是通过分析<code>main</code>函数的汇编代码得出的。
分析:
我们可以看到,在每个<code>phase</code>调用前,都<code>callq 0x40149e <read_line></code>,然后<code>mov %rax,%rdi</code>,这样子会将我们输入的字符串最终存到<code>%rdi</code>中。(我们是把字符串输入到<code>read_line</code>的,而<code>read_line</code>会返回到<code>%rax</code>中,<code>mov</code>操作将<code>%rax</code>存到<code>%rdi</code>。注意,<code>%rax</code>往往用来放返回值)
至于<code>read_line</code>的汇编代码我就不分析了,通过名字也可以看出:它是用来返回我们的输入值的
下面开始分析<code>phase_1 ~ phase_6</code>的汇编代码,
得出认为正确的字符串,并逐个解除炸弹
查看<code>phase_1</code>的汇编代码:
重点就是<code><+14></code>的test指令,可以看出当<code>%eax</code>为0时才不会爆炸。也就是说函数<code>strings_not_equal</code>的返回值必须为0才行,根据名字我们可以猜测,字符串不相等时返回1,字符串相等时返回0。下面查看<code>string_not_equal</code>的汇编代码验证我们的猜测。
通过查看<code>string_not_equal</code>函数的汇编代码,可以找到,<code>string_not_equal</code>函数先是比较了输入字符串和地址<code>0x402400</code>对应的字符长度,再逐个比较字符,最终,字符相同返回<code>0</code>,字符不同返回<code>1</code>。我们可以看到,汇编进行不少优化。例如,如果第一个字符已经是不同的,就不用循环进行更多的操作。
key:由此可以知道,只要我们输入的字符和地址<code>0x402400</code>对应的字符相同即可。那么,我们通过gdb指令<code>x/s 0x402400</code>即可访问<code>0x402400</code>对应的字符。代码如下:
那么,只要在运行界面输入<code>Border relations with Canada have never been better.</code>即可。(译为:与加拿大的边境关系从来没有这么好过。)
我们先查看<code>phase_2</code>的汇编代码:
<code>callq 0x40145c <read_six_numbers></code>,我们查看这个函数的汇编代码:
(根据名字,我们猜测其作用是读取6个数字)
注意到<code>phase_2</code>中<code><+6></code>已经将%rsp赋给%rsi,那么,对%rsi进行操作也就是之后对<code>phase_2</code>中的%rsp操作。
以下表格是对%rsi操作的展示:
0x4(%rsi)
0x8(%rsi)
0xc(%rsi)
0x10(%rsi)
0x14(%rsi)
(%rsp)
0x8(%rsp)
注意,<code>0x10 = 16D</code>,<code>0x14 = 20D</code>。十进制后缀<code>D</code>,Decimal.
可以看到,这样操作传递了6个地址参数,其地址间隔为<code>4</code>,最后两个因为参数寄存器不够用了,只能用栈帧%rsp。(注意,此处的%rsp是<code>read_six_numbers</code>自己开辟的,原先<code>phase_2</code>的%rsp已经中断)
<code><+36></code>处,<code>mov $0x4025c3,%esi</code>,访问0x4025c3内容:
可以知道%eax中存放着格式字符串
<code><+46></code>处,<code>callq 0x400bf0 <__isoc99_sscanf@plt></code>,函数<code>sscanf</code>是c语言自带的函数,同<code>scanf</code>类似,作用是读取输入的字符串,并根据指定格式存储到指定地址。这告诉了我们的输入的字符串,应该是6个整型数字,而且之间用空格隔开。同时,它们存放在上述的6个参数地址中,也就是之后<code>phase_2</code>的%rsp按<code>4</code>递增地址的栈帧中。符合我们的猜测。
我们回到<code>phase_2</code>继续分析: 可以知道第一个参数数值<code>(%rsp)</code>必须是<code>1</code>,之后会进入一个循环。我们把这个循环单独拿出来看:
我们已经知道<code>(%rsp) = 1</code>,那么第一次循环中,<code><+32></code>处的<code>%eax = 2</code>,故只有<code>(%rbx) = 0x4(%rsp) = 2</code>,才不爆炸;第二次循环中,<code><+32></code>处的<code>%eax = 4</code>,故<code>(%rbx) = 0x8(%rsp) = 4</code>;第三次循环中,<code><+32></code>处的<code>%eax = 8</code>,故<code>(%rbx) = 0xc(%rsp) = 8</code>,可以看出是以1为首项,后一项是前一项两倍的递增数列,共6项,以此类推,有下表。
0x4(%rsp)
0xc(%rsp)
0x10(%rsp)
0x14(%rsp)
1
2
4
8
16
32
key: 由此得知,phase_2该输入的字符串为<code>1 2 4 8 16 32</code>
<code>phase_3</code>的汇编代码如下:
访问<code>0x4025cf</code>,可知字符串格式为<code>"%d %d"</code>,从而得知输入字符串是两个整数。根据<code><+39>: cmpl $0x7,0x8(%rsp)</code>和<code><+44>: ja 0x400fad <phase_3+106></code>可以知道<code>0x8(%rsp) <= 7</code>。那么,第一个参数%rdx取值要小于等于7。
根据<code><+50>: jmpq *0x402470(,%rax,8)</code>可以知道,跳转的地址是指针<code>*0x402470</code>的变换,增量为<code>8</code>,此时为<code>0x8(%rsp)</code>即为%eax。
下面我们用<code>x/s</code>指令逐个访问,指针地址是递增的,但对应存放的<code>phase_3</code>的地址并不是递增的。到这时,答案已经呼之欲出了。
(由此可以知道指针<code>*0x402470</code>指向一个存放<code>phase_3</code>部分地址的字符串。一开始我想的是对<code>phase_3</code>的部分地址直接进行增<code>8</code>操作,没有想到是对指针<code>*0x402470</code>进行增<code>8</code>操作,从而访问不同的<code>phase_3</code>中的地址,耽误了许久)
对<code>phase_3</code>继续分析:
根据<code><+123>: cmp 0xc(%rsp),%eax</code>和<code><+127>: je 0x400fc9 <phase_3+134></code>知道,第二个参数<code>0xc(%rsp)</code>必须和%eax相同,此时的%eax根据<code>0x8(%rsp)</code>不同而不同。
key:
整理上述分析可以知道,共有<code>8</code>组答案如下:
3
x/s
*0x402470
*(~ +8)
*(~ +16)
*(~ +24)
<phase_3+n>
+57
+118
+64
+71
0xc(%rsp) H
0xcf
0x137
0x2c3
0x100
0xc(%rsp) D
207
311
707
256
5
6
7
*(~ +32)
*(~ +40)
*(~ +48)
*(~ +56)
+78
+85
+92
+99
0x185
0xce
0x2aa
0x147
389
206
682
327
(十六进制后缀,H,hexadecimal;十进制后缀,D,Decimal)
我们选择第8组答案<code>7 327</code>作为输入:
<code>phase_4</code>的汇编代码如下:
分析:仍旧是输入两个<code>int</code>参数,根据<code><+34></code>处可知,第一个参数<code>0x8(%rsp)</code>满足<code>0xe > 0x8(%rsp)</code>,第二个参数<code>0xc(%rsp)</code>必须为0。但是第一个参数需要根据<code><func4></code>函数来确定。
<code><func4></code>的汇编代码如下:
第一次进入func4函数:
分析:其实这个时候答案已经出来了,只要第一个参数为<code>7</code>和<code>%ecx=7</code>相同即可。但显然<code>func</code>是一个递归函数,我们进入递归看看,还有什么答案。
第一次递归:(记为<code>R1</code>)
第一个参数为<code>3</code>和<code>%ecx=3</code>相同即可。
第二次递归:(记为<code>R2</code>)
第一个参数为<code>1</code>和<code>%ecx=1</code>相同即可。
第三次递归:(记为<code>R3</code>)
第一个参数为<code>0</code>和<code>%ecx=0</code>相同即可。
第四次递归:(记为<code>R4</code>)
第五次递归:(记为<code>R5</code>,此时<code>R5 = R3</code>)
由此可以知道,<code>R4</code>之后会一直在<code>R3、R4</code>之间无限循环,直到程序崩溃。那么,第一个参数的取值只能为:<code>0 1 3 7</code>
得出<code>4</code>组答案为:
0x8(%rsp) 第一个输入参数
0xc(%rsp) 第二个输入参数
我们取<code>0 0</code>这组输入。
<code>phase_5</code>的汇编代码如下:
很显然,输入的字符串长度得为<code>6</code>。利用x/s指令,在<code><+55></code>处我们查看<code>x/s 0x4024b0</code>,给出一句嘲讽我们的话,<code>"maduiersnfotvbylSo you think you can stop the bomb with ctrl-c, do you?"</code>,很明显不是答案,也许是答案,也许不是答案,也许在暗示答案不能单单copy,我们无视他的嘲讽,对<code><+41> ~ <+74></code>处的循环进行专门分析。
第二次循环:
以此类推至第六次循环后,应当有<code><+41>: %ecx = %rbx+5</code>和<code><+62>: %rsp+0x10+5 = %dl</code>。此时,<code>%rbx</code>是输入,会有: <code>%rsp+0x10+5 = %dl = %edx = 0x4024b0+(%rdx & 0xf)</code>
上式等价于:<code>= 0x4024b0+(%cl & 0xf) = 0x4024b0+((%rbx+5) & 0xf)</code>
所有情况见下表。
%rsp+0x10+0
0x4024b0+%rbx+0(0x4024b0 + (第一个输入参数 & 0xf))
%rsp+0x10+1
0x4024b0+%rbx+1(0x4024b0 + (第二个输入参数 & 0xf))
%rsp+0x10+2
0x4024b0+%rbx+2(0x4024b0 + (第三个输入参数 & 0xf))
%rsp+0x10+3
0x4024b0+%rbx+3(0x4024b0 + (第四个输入参数 & 0xf))
%rsp+0x10+4
0x4024b0+%rbx+4(0x4024b0 + (第五个输入参数 & 0xf))
%rsp+0x10+5
0x4024b0+%rbx+5(0x4024b0 + (第六个输入参数 & 0xf))
可以看出<code>%rsp+0x10</code>的赋值是<code>0x4024b0</code>的偏移,偏移量范围为<code>0 ~ 15</code>,也就是嘲讽句的前16个字符,即<code>maduiersnfotvbyl</code>。
我们回到<code>phase_5</code>函数继续分析,利用x/s指令,在<code><+81></code>处我们查看<code>x/s 0x40245e</code>,给出一个单词字符串,<code>"flyers"</code>(译为飞翔者们或者考熟的鸭子飞走了)。也就是说,<code><+86></code>处的入参必须与<code>flyers</code>相同。
根据<code>maduiersnfotvbyl</code>,取得<code>flyers</code>对应<code>0x4024b0</code>的偏移量是<code>9、15、14、5、6、7</code>,但是只能输入<code>6</code>个字符,如果直接输入<code>91514567</code>,超过<code>6</code>个字符会爆炸。
要解决这个问题,可以先把偏移量转换为二进制<code>1001、1111、1110、0101、0110、0111</code>。因为有<code>%rbx & 0xf</code>的位级操作,那么我们只要保证尾4位相同即可。这时可以联想到用来定义字符的ASCII表,那么答案有许多种,我比较懒,就只找尾4位为<code>1111</code>和<code>1110</code>的字符。分别为<code>/</code>和<code>.</code>,从而得到输入<code>9/.567</code>。
查看<code>phase_6</code>的汇编代码:
好家伙,一个电脑屏幕根本装不下全部代码。我们分成几个部分来看。
注意:在循环开始前会有一些变量准备;<code>0x10 = 16D,0x14 = 20D</code>;<code>flag</code>这个变量命名常用来当作循环是否结束的标志。
Part1,读入了6个整数。
根据<code>phase_2</code>的<code><read_six_numbers></code>分析可以知道,这段读入了6个整数,对栈帧<code>%rsp</code>偏移(偏移量为<code>4</code>)即是输入<code>input[i],i取0 ~ 5</code>。如下表所示:
input[0]
input[1]
input[2]
input[3]
input[4]
input[5]
Part2,保证6个输入整数(<code>input[i],i取0 ~ 5</code>)都不相同且范围为1 ~ 6。
loop1确定了<code>input[i]</code>的取值范围为:<code>1 ~ 6</code>。loop2保证6个输入都不相等。
取值范围如何确定的?由<code>+39 ~ +45</code>处得出,<code>input[i] <= 6</code>。同时,因为<code>+45</code>的 <code>jbe</code> 是对无符号数操作,若<code>input[i]</code>取 <code>0</code> ,执行<code>0 - 1 = -1</code>在比较时会出错(溢出),所以不能取<code>0</code>。故只能取<code>1 ~ 6</code>。
Part3,执行算式:<code>input[i] = 7 - input[i]</code>
因此为了方便,我们重新命名:<code>sub_input[i] = 7 - input[i]</code>
Part4,引入链表并改变链表顺序。
首先我们查看<code>0x6032d0</code>,一开始用<code>x/s</code>指令都是乱码,如图所示。
但是注意到<code>node1</code>,说明其很有可能是链表,而不是字符串。
我们用<code>x/24xw</code>指令,按xw格式(十六进制4字节格式)输出24个数据。
如图所示,符合我们的猜测,就是链表,<code>0x6032d0</code>是head指针。
其中,node是节点地址,val是节点值,order是它的序列(一共6个),next是下个节点的地址(能够发现它刚好就是按照序列排列的,最后一个节点的next是<code>0x0即NULL</code>)。
那么,该段循环是怎么改变链表顺序的呢?首先引入栈帧<code>%rsp + 8*i + 0x20,i取0 ~ 5</code>,然后在<code>+130 ~ +137</code>,<code>0x6032d0</code>将随<code>sub_input[i]</code>的改变而改变,最后将改变后的链表逐个赋给栈帧。
即执行执行赋值算式:<code>%rsp + 8*i + 0x20 = $0x6032d0 + (8*(sub_input[i]-1))</code>
这样下来就能够重排链表了。但此处还没有给出改变链表顺序的标准是什么。
同时注意到一个重要的细节问题:改变时0x6032d0的间隔为8D,但我们需要的间隔为0x10 = 16D,如何解决?
事实上,间隔为8也没关系。只要部分+8的地址所存数值恰好为+16的地址即可。(不是所有地址都需要这样,另一部分地址执行两次+8就行了)
上述表述等价于三个等式
<code>*(0x6032d0+8) = 0x6032e0</code>、<code>*(0x6032f0+8) = 0x603200</code>、<code>*(0x603310+8)= 0x603320</code>成立。
我们用p/x 指令打印数值看三个等式是否成立。(这个成立是<code>phase_6</code>已经设置好的,但不查看之前完全不知道)
执行part4后,可以得出如下表格:
rec_node0
rec_node1
rec_node2
rec_node3
rec_node4
rec_node5
%rsp + 0x20
%rsp + 0x28
%rsp + 0x30
%rsp + 0x38
%rsp + 0x40
%rsp + 0x48
说明<code>rec_node1 ~ rec_node6</code>将逐个放入栈帧<code>%rsp + 0x20 ~ %rsp + 0x48</code>中。
注意:因为node0 ~ node5已经随sub_input而重新排列了,但我们还不知道是如何排列的。
所以,不妨命名为:rec_node0 ~ rec_node5,表明链表重组,也就是所谓的改变链表顺序。
(rec:recombination)
同时也可以得出<code>sub_input</code>对应<code>rec_node</code>的表格:
sub_input[0]
sub_input[1]
sub_input[2]
sub_input[3]
sub_input[4]
sub_input[5]
0x6032d0
0x6032e0
0x6032f0
0x603300
0x603310
0x603320
part5,重新连接next。
注意:
<code>0x50(%rsp) = 0 = NULL</code>是next连接完才赋值的。
这里利用栈帧<code>%0x28(%rsp) ~ 0x50(%rsp)</code>逐个赋给<code>%0x20(%rsp) ~ 0x48(%rsp)</code>
改变的是rec_node ->next指向的地址,而不是rec_ndoe本身。也就是所谓的重新连接next。
之所以要重连next,也是因为node已经重排为rec_ndoe了。
part6,说明改变链表顺序的标准:按<code>val</code>降序排列。(从大到小)
之所以按<code>val</code>降序排列,是因为必须满足<code>(0x8+0x20+%rsp+k*8) >= (0x20+%rsp+k*8),k取0~5</code>
即<code>node->val >= node->next->val</code>成立,也就是链表中当前节点值大于下一个节点值。
综上part1 ~ part6可以得出答案:(<code>sub_input</code>模7得到<code>input</code>)
val
0x39c
0x2b3
0x1dd
0x1bb
0x14c
0x0a8
rec_node
sub_input
input
inuput为:<code>4 3 2 1 6 5</code>
ps:如果你仔细观察,你会发现,按val降序排列之后,order其实恰好对应着sub_input。
可恶啊!竟然还有个彩蛋关。什么?你说我怎么发现的,当然是“口口相传”啦。
(事实上可以在编译文件上查找<code>ctrl+f</code>到)
用到了二叉树。
查看<code>phase_defused</code>的汇编代码:(可以知道在phase_4中多输入个DrEvil即<code>0 0 DrEvil</code>才能进入彩蛋关)
我们对一些字符串进行访问,可以知道调用<code>sscanf</code>函数前得输入,其格式为<code>"%d %d %s"</code>但输入内容是空的,这说明我们还没输入。我们需要输入,但,是什么时候输入呢?
要确定输入是何时输入的,我们可以先在<code>*0x4015f5</code>处,即输入处打断点,然后run bomb文件,最后访问<code>0x603870</code>的内容。
此时有<code>0x603870 <input_strings+240>: "0 0 "</code>,这说明输入是在<code>phase_4</code>处进行的。其输入格式为<code>"%d %d %s"</code>,同时有<code>*(0x402622) == DrEvil</code>,之后要进行字符比对且相同才进入secret_phase。那么我们大胆猜测,应该在<code>phase_4</code>处输入<code>0 0 DrEvil</code>才能进入彩蛋关。
开始正式分析,首先查看<code>secret_phase</code>的汇编代码:(说明调用fun7之后,返回值必须为2)
查看<code>fun7</code>的汇编代码:
这是一棵二叉树,思路如图所示:
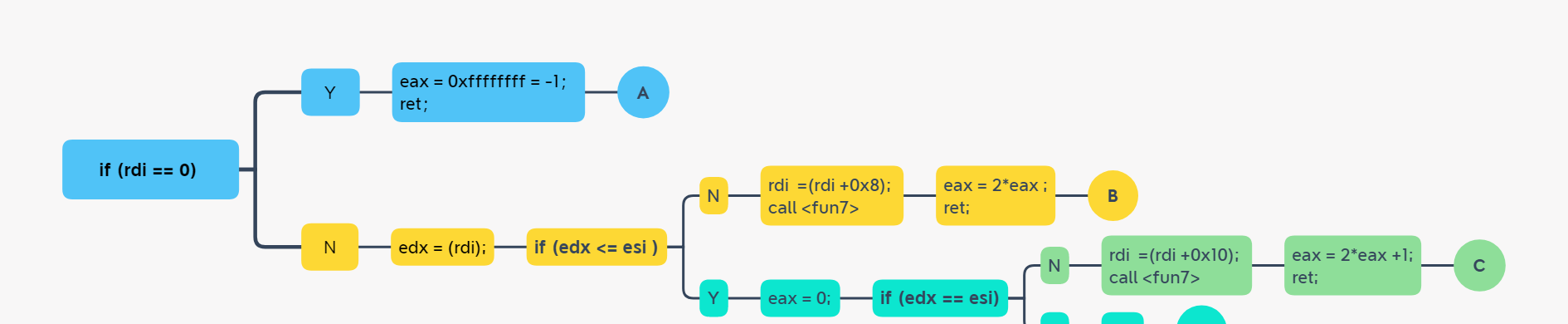
方法一:实现eax = 2。(ps:递归调用顺序与返回顺序相反)
下面描述调用过程:(ps:esi是input,每次调用完都会更新rid指向的地址)
B:第一次调用fun7,<code>(rdi) = (0x6030f0) = 0x24</code>。同时输入要不满足<code>(rdi) <= esi</code>,也就说输入小于0x24,才能走路径B。
此次调用结束时更新rdi指向的地址,即:<code>rdi+0x8 = 0x603110</code>。
C:第二次调用fun7,<code>(rdi) = (0x603110) = 0x8</code>。同时输入要满足<code>(rdi) <= esi</code>且不满足<code>edx == esi</code>,也就说输入大于0x8且不等于0x8,才能走路径C。
此次调用结束时更新rdi指向的地址,即:<code>rdi+0x10 = 0x603150</code>。
D:第三次调用fun7,<code>(rdi) = (0x603150) = 0x16</code>。同时输入要满足<code>(rdi) <= esi</code>且满足<code>edx == esi</code>,也就说输入等于0x16即20D,才能走路径D。
三次调用结束,得出input为<code>20</code>。
方法二:实现eax = 2。
key:我们取<code>20</code>这个答案。
无聊地查看一下二叉树内容:(此处对解题不是很有必要)
整理后的图状展示:
But you know, Alan, sometimes it's the very people who no one imagines anything of who do the things no one can imagine. ---The Imitation Game
从9.27到10.11,总算完结了。期间有几天是没有写的。总共是8天,最后两关都用了2天。当然不是一整天,5、6个小时应该是有的。完全靠自己写的是phase_4,奈何没啥基础。前几个都在适应gdb是怎么调试的,后几个难度比较大,phase_5是没联系到ASCII,后两个是链表、二叉树都不熟悉。也参考了不少其它大佬的解答。
自己的汇编阅读能力是提升了不少,后面看都是比较自然,但是联系到数据结构就比较不了解,还是得继续提高姿势水平。
如有谬误,敬请指正。
![在DOS下运行不了ipconfig命令[图]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)