innodb buffer pool有几个目的:
缓存数据--众所周知,这个占了buffer pool的大半空间
缓存目录--数据字典
insert buffer
排序的内部结构--比如自适应hash的结构或者一些行锁
idxfrac这个值越低越好,举个例子,表里只有一个唯一索引的数据如下:
可见idxfrac可见这个值越低越好。
从这里可以看到数据和索引占了buffer pool的大部分空间。也可以看出来这里有几种重要的页类型:
INDEX: B-Tree index
IBUF_INDEX: Insert buffer index
UNKNOWN: not allocated / unknown state
TRX_SYSTEM: transaction system data
一个典型的buffer pool使用监控
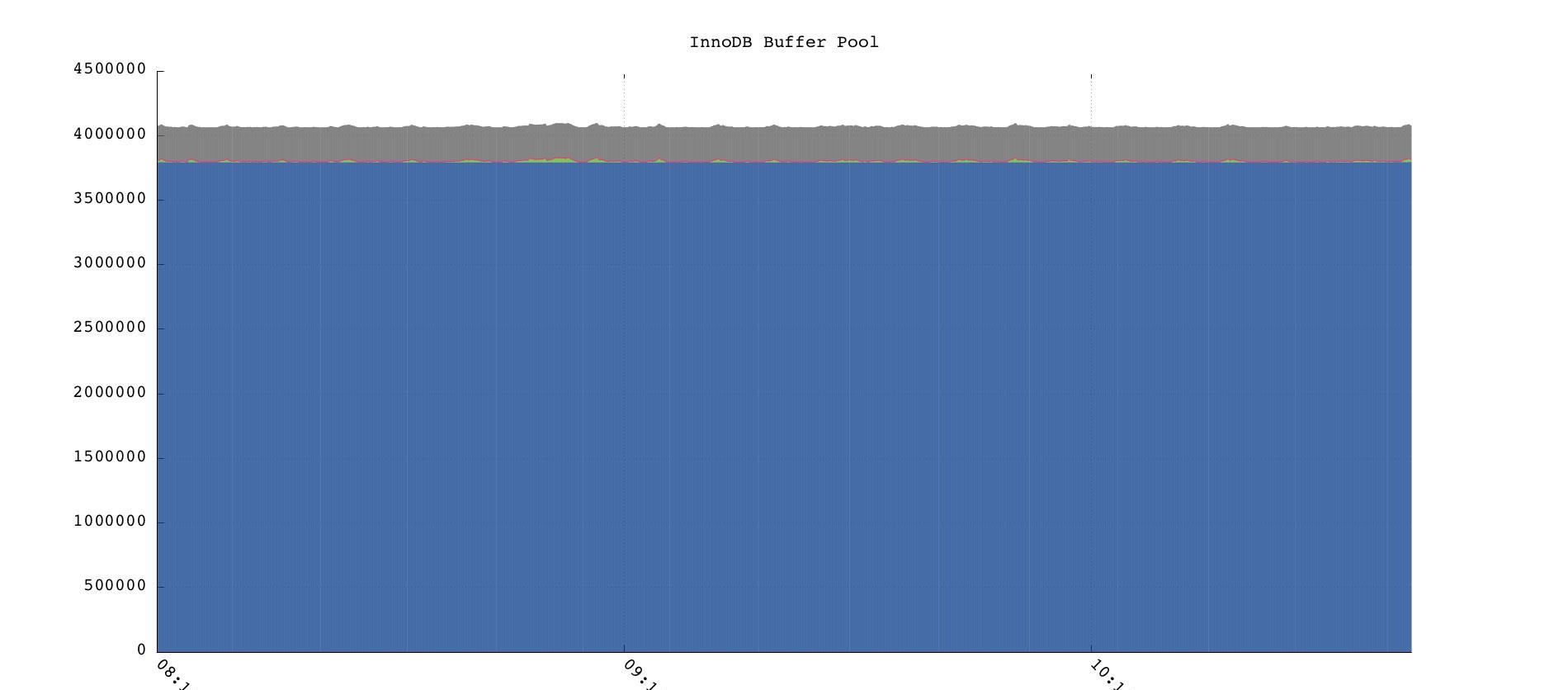
从这里图里我们可以看到buffer pool几乎是被填满的,另外预留了10%的空间用来做其他用途。
一般怎么设置buffer pool大小呢?
在InnoDB上面执行select语句:
对于聚簇索引来说,大多数情况通过SELECT COUNT(*) 加载到buffer pool中了。
对于二级索引来说,要执行一些简单的语句来抓取全部数据,比如select from tbname where 索引的第一列。或者select from tbname force index(二级索引) where colname <>0.
另外,MySQL5.7支持动态修改buffer pool:
在MySQL (5.6+), Percona Server (5.5.10+) or MariaDB (10.0+)可以通过以下配置把buffer pool里面的数据dump出来,并在启动的时候加载到内存中:
<a href="https://michael.bouvy.net/blog/en/2015/01/18/understanding-mysql-innodb-buffer-pool-size/">https://michael.bouvy.net/blog/en/2015/01/18/understanding-mysql-innodb-buffer-pool-size/</a>
<a href="http://www.speedemy.com/mysql/17-key-mysql-config-file-settings/innodb_buffer_pool_size/">http://www.speedemy.com/mysql/17-key-mysql-config-file-settings/innodb_buffer_pool_size/</a>
![数据迁移方法数据迁移原则数据迁移之双写方案数据迁移之级联同步方案[图]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)