本系列文章主要阐述大数据计算平台相关框架的搭建,包括如下内容:
基础环境安装
zookeeper集群的搭建
kafka集群的搭建
hadoop/hbase集群的搭建
spark集群的搭建
flink集群的搭建
elasticsearch集群的搭建
alluxio集群的搭建
1.kafak简介
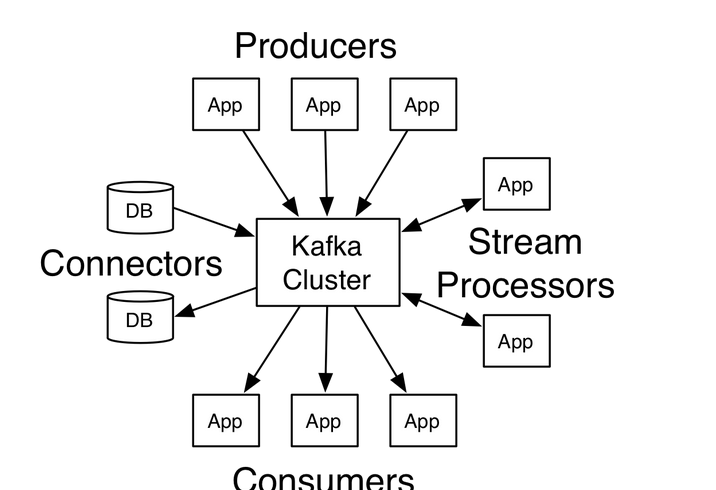
Kafka是一个分布式、分区的、多副本的、多订阅者的消息队列,以高吞吐量著称,主要用于实时数据的传输和处理,总体架构如下
2.kafka安装
下载
地址:http://kafka.apache.org/downloads,选择kafka_2.11-0.10.2.1.tgz版本

解压安装
本文环境列表
直接在服务器10.20.112.59上解压
1
2
3
<code>cd ~</code>
<code>tar -zxvf kafka_2.11-0.10.2.1.tgz.gz</code>
<code>mv kafka_2.11-0.10.2.1 kafka</code>
配置更改
编辑kafka server配置文件
vi /wls/oracle/kafka/config/server.properties
主要是如下几项:
kafka集群
修改server.properties
不同集群broker.id 和host.name 不一样,根据实际情况配置。
修改默认配置文件中的
broker.id(每台服务器均不同)
port(如果是伪集群,则端口号需要改变)
host.name
advertised.host.name
zookeeper.connect(所有集群的ip均需要说明)
log.dirs
以服务器SZB-L0045546,则其server.properties需更改的配置如下:
而集群另外4台服务器中的broker.id、host.name,advertised.host.name和SZB-L0045546的保持不同即可。同时集群中的服务器需要为kafka日志建立相关目录
启动和验证
依次启动集群中的kafka,执行脚本如下:
创建topic
显示创建的topic
向TEST中写入消息
从topic TEST中消费数据