相对上一个脚本,该脚本修改了如下内容:
<b>1 url的传入方式,只需将url保存到一个文本文件里,由程序自己读入并解析</b>
<b>2 增加了oracle 指标数据统计和分析,比较两周(我自己的需要)的数据变化趋势</b>
#!/usr/bin/python
# -*- coding: UTF-8 -*-
#created by yangql
#date @2011-12-13
#function 获取AWR报表中的oracle数据库指标,分析并得出数据趋势
import sys
import urllib
import HTMLParser
import string
####转换unicode 类型的字符串到 float 型的数值
def utof(s1):
s2=s1.strip()
s3=s2.encode('utf-8')
s4=s3.split(',')
length=len(s4)
if length 1 :
t1= string.atof(s4[0])
return t1
elif length == 2:
t1=string.atof(s4[1])+string.atof(s4[0])*1000
elif length == 3:
t1=string.atof(s4[2])+string.atoi(s4[1])*1000+string.atoi(s4[0])*1000000
else:
return 0
###构造解析html的类并且获取整个HTML中除去标签的文本数据
urltext = []
class CustomParser(HTMLParser.HTMLParser):
selected=('table', 'h1', 'font', 'ul', 'li', 'tr', 'td', 'a')
def reset(self):
HTMLParser.HTMLParser.reset(self)
self._level_stack = []
def handle_starttag(self, tag, attrs):
if tag in CustomParser.selected:
self._level_stack.append(tag)
def handle_endtag(self, tag):
if self._level_stack \
and tag in CustomParser.selected \
and tag == self._level_stack[-1]:
self._level_stack.pop()
def handle_data(self, data):
if "/".join(self._level_stack) in ('table/tr/td','table/tr/td/h1/font','table/tr/td/ul/li') and data !='\n':
#print data
urltext.append(data)
####调用解析html 的类,并且将获取的文本数据传递给urltext 数组
def gethtml(url):
content = unicode(urllib.urlopen(url,params).read(), 'UTF-8')
parser = CustomParser()
parser.feed(content)
parser.close()
####获取指定的指标的值,
def calculcate(urltext):
print '-----------------------------------------'
global Logical
global Physical_reads
global Physical_writes
global Executes
global Transactions
k=0
for item in urltext:
k=k+1
if k50 :
continue
elif item =='Logical reads:' :
Logical.append(utof(urltext[k]))
print 'Logical reads: ' ,urltext[k].strip()
elif item == 'Physical reads:' :
Physical_reads.append(utof(urltext[k]))
print 'Physical reads: ',urltext[k].strip()
elif item == 'Physical writes:' :
Physical_writes.append(utof(urltext[k]))
print 'Physical writes: ' ,urltext[k].strip()
elif item =='Executes:':
Executes.append(utof(urltext[k]))
print 'Executes: ' ,urltext[k].strip()
elif item == 'Transactions:' :
Transactions.append(utof(urltext[k]))
print 'Transactions: ',urltext[k].strip()
elif k>86:
break
def result(url):
global urltext
print ' '
gethtml(url)
calculcate(urltext)
urltext = []
def get_avg(List):
print ' '
sum1=0
sum2=0
avg1=0
avg2=0
trend=0
count=len(List)
for i in range(0,count):
if icount/2:
sum1 =sum1+List[i]
elif i>=count/2:
sum2 +=List[i]
avg1=sum1/count*2
avg2=float(sum2)/(count/2)
trend=(avg1-avg2)/avg2*100
print '第一周的均值 ',' 第二周的均值 ',' 趋 势(%)'
print "%-20.2f" %avg1 ,"%-15.2f" %avg2 ,"%-4.2f" %trend,'%'
if __name__ == '__main__':
if len(sys.argv)>1:
params=urllib.urlencode({'ip':sys.argv[1],'action':2})
else:
params=None
Logical=[]
Physical_reads=[]
Physical_writes=[]
Executes=[]
Transactions=[]
count=0
f = file('/root/python/1.txt')
while True:
url = f.readline()
if len(url) == 0:
break
elif len(url.strip())== 0:
else:
result(url)
count=count+1
f.close()
print '共有',count,'组数据'
print '-------------------Logical------------------ '
get_avg(Logical)
print '----------------Physical_reads-------------- '
get_avg(Physical_reads)
print '----------------Physical_writes------------- '
get_avg(Physical_writes)
print '-------------------Executes----------------- '
get_avg(Executes)
print '-----------------Transactions---------------'
get_avg(Transactions)
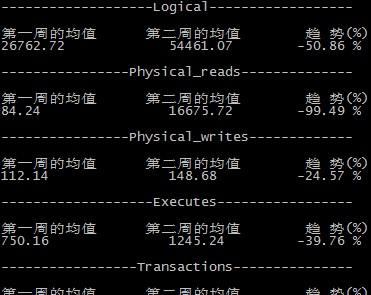
效果截图: