本節書摘來自華章計算機《高性能科學與工程計算》一書中的第1章,第1.6節,作者:(德)georg hager gerhard wellein 更多章節内容可以通路雲栖社群“華章計算機”公衆号檢視。
從cray 1超級計算機開始,直到基于risc的高度并行計算機出現之前,向量機一直占據着科學計算的主要領域。在寫這本書時,隻有兩家公司還在制造和銷售向量機。但因為對記憶體帶寬和運作時間有高度需求,向量機還是有着一個充滿商機的市場。
根據設計,對于合适的可向量化的代碼,向量處理器相較于标準的微處理器可以達到一個較好的實際性能。這種設計遵循單指令多資料(simd)的範例,即一條簡單的機器指令被自動地應用于很多類型相同的參數。許多現代的基于cache的微處理器以擴充sisd指令集的形式采用這些技術(細節參考2.3.3節)。而且向量機在執行單元和存儲子系統上有大量的并行操作。
1.6.1 設計原理
現代向量處理器與risc設計非常像,都是寄存器—寄存器型的機器:機器指令運作在向量寄存器上,每個向量寄存器存儲長度在64~256(雙精度)之間的一些參數。向量寄存器的寬度稱為向量長度lv。對于每一種算術運算,像加法、乘法、除法等都分别有一條流水線,每一條流水線在每個指令周期都可以得到一定數目的結果。對于乘法和加法流水線來說,得到2~16個結果,這也稱作多軌流水線(multitrack pipeline)(參考圖1-21)。其他像平方根和除法操作比較複雜,流水線的輸出要低很多。但是即使隻有單一流水線的向量處理器也可以達到基于cache的超标量微處理器相同的峰值性能。為了向向量寄存器提供資料,有一個或者多個直接跟主存相連的讀取、存儲、讀取與存儲相結合的流水線。盡管最近像nec sx-9的設計引進了容量小的片上存儲,但傳統的向量cpu沒有緩存層次的概念。
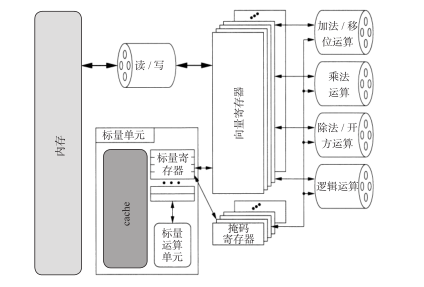
為了在向量cpu上獲得合理的性能,必須采用simd類型的指令。我們來看一個簡單的例子,有兩個數組a(1 : n?) = b(1 : n?) + c(1 : n?)。在一個基于cache的微處理器上,這個運算最終的實作是在a、b和c上的一個循環(可能會軟流水),對于每一次計算,必須要執行兩次讀取操作、一個加操作和一個存儲操作,并且還必須有整型和分支邏輯來實作循環。如果數組的長度比寄存器長度短,則向量cpu可以對于整個數組使用一條指令:

https://yqfile.alicdn.com/47b331d6e0973eee7806b13070e0146e8062b084.png" >
在這裡,v1、v2、v3表示向量寄存器。追蹤分散在不同的流水線上的向量索引的工作是自動完成的。如果數組的長度比向量的長度大,循環就必須以向量長度為機關分塊執行:
這個工作由編譯器自動完成。
像向量加這樣的操作并不需要等到向量寄存器将所有參數都準備就緒才開始運算,而是可以在最初的一些參數就緒之後就可以開始執行。這個特征稱為連結(chaining),這也是不同管道(例如乘法、加法)能夠同時操作的必要條件。
很明顯,在risc出現前向量結構明顯地降低了指令發射速率的要求,那個時候多發射超标量處理器還沒有足夠快的指令cache。更重要的是,讀取/存儲操作的速率需要和cpu核頻率比對,是以為運算流水線提供資料就更不是問題了。由于現代記憶體晶片在一次緩存操作後需要幾個時鐘周期的恢複時間(也稱為bank忙碌時間),是以可以通過有大量的bank結構的記憶體布局來實作兩者速率的比對。為了減小兩者之間的差距,現代向量機提供數以千計的記憶體bank,這也導緻了這種結構對于通用計算來說相當昂貴。總之,向量處理器是通過高度并行的流水線以及高帶寬的記憶體通路來獲得它的性能。
編寫程式以使編譯器産生有效simd向量指令稱為向量化。有時候需要代碼重構或者在源代碼中插入指令指針來幫助編譯器确認simd并行。每一個向量處理器都有一個單獨的标量單元,用來執行那些不能向量化的代碼(接下來的章節中讨論)并完成任務管理工作。向量處理器中的标量單元要比标準的risc或基于x86設計中的标量單元差很多,是以為了獲得高性能,向量化就顯得格外重要。如果代碼不能被向量化,則使用向量機不會帶來任何好處。
1.6.2 最高性能估計
向量處理器的峰值性能可以通過加法和乘法流水線的track數目以及時鐘頻率得到。比如,一個2ghz的向量處理器以及具有4個track的流水線,峰值性能是:
求平方根、除法和其他操作由于有着較差的吞吐量,對計算峰值性能沒有較大的貢獻,是以在這裡不予考慮。關于記憶體帶寬,有4個track的ld/st(參見圖1-21)流水線可以得到的讀寫帶寬為:
這恰好是nec sx-8處理器的标準規格。和基于cache的标準微處理器相比,向量處理器的記憶體接口的頻率通常和核相同,能夠為峰值性能提供更高的帶寬。注意到上面這些計算都是建立在一個假設上:向量處理單元一定會被用到——如果代碼是不可向量化的,因為要受标量單元的限制,是以不管峰值性能或者峰值存儲帶寬都不能達到。
通常對于一個擁有簡單記憶體通路類型的循環,其性能可以預測。第3章将會對平衡分析給予詳細介紹,例如對結構和循環代碼的特點進行性能預測。對于向量處理器,由于不存在cache,是以預測一般會比較簡單。以代碼清單1-1為例,3次讀取操作,1次存儲操作和兩個浮點操作(加法和乘法)。由于隻有單一的ld/st管道,讀取和存儲操作,甚至對不同數組的讀取操作都不能夠重疊。但它們可以重疊算術管道并連結到算術管道。在圖1-22中,長平行四邊形代表在向量寄存器上的一個操作,标志着管道操作的執行(與圖1-5中的時間線很像)。首先必須向一個向量寄存器中從數組c讀取資料,ld/st管道開始于用數組d中的資料填充向量寄存器,乘法管道就可以開始在c和d上執行算數運算。隻要來自b的資料可用,加法管道就可以計算出最終結果,繼而ld/st管道将結果存儲到記憶體。
整個過程的性能瓶頸很顯然是ld/st流水線。如果給予合适的代碼,硬體能夠在相同時間内執行4倍的乘法和加法指令(圖1-22中淺灰色菱形),是以代碼清單1-1的性能隻能達到峰值性能的25%,在上面描述的向量處理器上性能為4 gflop/s,這與圖1-4中的sx-8 n很大時的曲線完全吻合。需要注意的是,由于向量系統上有很大的記憶體延遲,是以這個限制隻對相對大的n值可以達到。另外,除了不可向量化的代碼,短循環是第二大影響這些結構的性能因素。
1.6.3 程式設計
向量化的必要條件是在循環的疊代之間不存在真資料相關。軟流水(見1.2.3節)也同樣不能出現真資料相關,例如允許向前引用(forward reference)但是向後引用(backward reference)會影響向量化。更精确地講,真相關的位移間隔必須大于某一門檻值(至少是向量的長度,有時更大),這樣前面向量操作的結果才會是可用的。
因為與“單條指令”的程式設計規範沖突,内部循環中的分支也會影響向量化。但是我們有一些方法來支援向量化循環中的分支:
掩位寄存器(mask register,本質上是向量長度的布爾寄存器)用來實作循環疊代的選擇性執行。我們來看下面一個例子:
首先,使用邏輯流水線根據分支條件産生一個每位為布爾類型的向量。接下來這個向量被用來從if或者else分支中選擇結果(見圖1-23)。當然,如果有開銷大的操作,那麼所有的循環分支都被執行顯然是一種浪費,但是向量化的利大于弊。
https://yqfile.alicdn.com/6c112693736061b283fe53ae6d04fa280bc6c6d8.png" >
對于單個分支(沒有else部分),特别在包括像除和平方根這些操作的情況下,gather/scatter是一種向量化的有效方法。在下面的例子中,如果分支預測大部分情況為假時,像圖1-23中那樣使用掩位寄存器會浪費很多計算資源:
與掩位寄存器不同(參見圖1-24),所有必要的元素首先被收集到向量寄存器中(gather),然後執行向量操作,最後執行的結果被存儲回去(scatter)。
編譯器會自動執行向量化操作(可能是源代碼直接支援向量化)或者代碼被重寫使得可以顯式地使用臨時數組來儲存所需的向量資料。還有另一種替代方案,使用清單向量,它是一個整型的向量數組,儲存着條件為真的索引,通過間接通路,這些索引可以用來重構原始循環。
由于cache行的概念,基于cache處理器對gather/scatter操作開銷非常大,而向量處理器能更經濟地執行(即使跨度為1的訪存模式更有效)。
關于向量結構的程式設計和優化可以從生産商處獲得更多參考文檔[v110,v111]。