本節書摘來自華章計算機《人工智能:計算agent基礎》一書中的第2章,第2.2節,作者:(加)david l.poole,alan k.mackworth 更多章節内容可以通路雲栖社群“華章計算機”公衆号檢視。
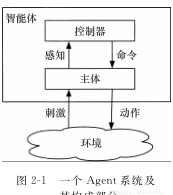
圖2-1展示了agent與環境的一般互動過程,該圖所示整體即是我們所說的agent系統。44
一個agent系統是由agent和其所在環境構成。agent接收環境中的刺激,然後做出相應動作。
一個agent由主體(body)和控制器(controller)兩部分組成。控制器從主體處接收感覺,然後将指令送至主體處。
主體包括傳感器和執行器,傳感器将外部刺激轉化為感覺,執行器能将指令轉換成動作。
刺激包括光、聲音、鍵盤上輸入的單詞、滑鼠移動或者實體沖擊,也包括從網頁或者資料庫中擷取的資訊。
常見的傳感器包括觸摸傳感器、相機、紅外傳感器、聲呐、麥克風、鍵盤、滑鼠或者通過網頁來抽取資訊的xml閱讀器。作為原型傳感器,相機感覺進入它的光束,将其轉換成亮度數值的二維數組,稱為像素。有時會使用多元像素數組來表示不同的顔色或者滿足多鏡頭相機的需求。這些像素數組可被控制器感覺。而更多的時候,感覺對象通常有着更高層的特征,如線、邊或深層次的資訊。通常來說,接收的都是特定資訊,如明亮的橙色圓點的位置,學生關注的演出部分或者人們打出的手勢資訊。
動作一般包括轉向、加速、移動關節、講話、展示資訊或者向某一網址發送郵件的指令。指令又包括低級指令(如将發動機的電壓設定為某個數值)和進階指令(如令一個機器人進行某些運動,例如“停止”,“以1m/s的速度向正東方向運動”或者“到103房間去”)。執行器同傳感器類似,都包含噪聲。例如,停止是需要時間的;機器人在實體規則下運動,是以具備動量,且資訊傳遞需要時間。機器人也許最終隻是以接近1m/s的速度運動,45接近正東方向,且速度和方向都是不斷波動的,甚至運動到某一指定房間的行為可能會由于各種原因而失敗。
控制器是agent的大腦,本章的剩餘部分将主要讨論如何建構一個控制器。
agent的功能
agent應建構為實時性的:應能即時接收傳感器資訊,并即時做出反應。特定時刻的agent動作是其輸入的函數。我們首先考慮時間的概念。
設t為時間點集合,假定t有序,且任意兩個時間點的時序距離均可測定。大體上,我們設定t可以映射到實線上的一些子集。
若任意兩個時間點間僅存在有限個時間點,則稱t是離散的,如每一天或1/100秒有一個時間點,或者有趣事件發生的時刻也可以是時間點。但如果t中任意兩個時間點間都存在另一個時間點,則認為t是稠密的,這表明t中的任意兩個時間點間存在無限多個時間點。離散時間存在如下特征:除了最後時間點,其他任何時間點均存在下一時間點。而稠密時間則無“下一時間點”。我們将時間初始化為離散的,且沒有盡頭。是以每個時間點都存在下一時間點。我們令t+1為時間點t的下一時間點,但這并不代表時間點之間是等間隔的。
假定t有初始時間點,我們這裡稱其為0。
假定p為所有可能感覺對象的集合。一個感覺軌迹或者一個感覺流則為一個從t到p的函數,它描述了每一時間點所觀察到的事物。
假定c是所有指令的集合。 圖2-2 例2-1的感覺軌迹 圖2-3 例2-1的指令軌迹47一個指令軌迹為從t到c的函數,其代表在每個時間點的指令。
【例2-1】 我們來考慮一個家居交易agent,它監控着多種家居用品價格(如它監視着某些特定交易,并記錄衛生紙的漲價情況)及家中相應存量。它必須決定是否購進某物及在何種價格時購進。感覺對象為目前商品價格及家中存量。指令為agent決定購買的各類商品的數量(若不購進則數目為0)。感覺軌迹描述了每個時間點(如每天)的商品價格和庫存數量,如圖2-2所示。指令軌迹描述每個時間點agent購進的商品數量,如圖2-3所示。
實際購入動作依賴于指令,但有可能有所不同。如agent發出一條以某一特定價格購入12卷(1打)衛生紙的指令,但并不意味着agent實際購入了12卷衛生紙,因為可能由于網絡通信問題,倉庫中的衛生紙已賣完,或者在決定買和實際買之間時價格已經46發生變動。
一個agent的感覺軌迹是控制器在過去、現在和将來接收到的所有感覺資訊的序列。指令軌迹則是控制器在過去、現在和将來發出的所有指令資訊的序列。指令可以是曆史感覺的函數。這就産生了轉換的概念,從感覺軌迹映射到指令軌迹的函數。
因為所有的agent都處于時間流中,是以agent不能真正地觀察到全部感覺序列;在任意時刻,它隻能觀察到截至現在的感覺軌迹。在t(t∈t)時刻隻能觀察到t時刻及其之前的資訊流。其指令隻能根據其經驗來決定。
轉換過程是有因果聯系的,如果對于所有時刻t,在t時間的指令都僅由t和其之前的感覺資訊決定。因果限制是必需的,因為agent處于時間流中,是以t時刻的指令不可能依靠t之後的感覺資訊。
控制器完成因果轉換的具體實作。
agent在時間t的曆史包括其在t時刻和之前的感覺流和在t時刻和之前的指令流。
是以,一個因果轉換可看做是從agent在t時刻的曆史到其在t時刻發出的指令的函數。這可被認為是agent的最規範描述。
【例2-2】 繼續例2-1的情況,一個因果轉換可認為,對于任意時刻,agent需要購買多少日用品取決于曆史價格、曆史庫存量(包括時下價格和現有庫存)及過往購買曆史。
因果轉換的示例如下:當庫存量低于5打且價格低于過去20天的平均價格的90%時則購買4打;若庫存量低于1打時購進1打;其他情況下不購進。
盡管因果轉換是使用者曆史的函數,但其不能直接實作,因為agent不能直接獲得它們的全部曆史資訊,它隻能獲得目前的感覺資訊和它仍能記住的資訊。
一個agent在時間t時的信念狀态是其所能記住的所有以前時間的資訊的總和。agent隻能擷取其存在信念狀态中的曆史。是以信念狀态蘊含了其現在和将來指令所能用到的所有曆史資訊。在任何時間,agent都能通路其信念狀态和感覺資訊。
信念狀态可以包含任何資訊,僅受制于其存儲器大小和處理能力限制。這是信念的一個非常普通的定義;有時我們會使用信念的一個更特别的定義,如agent的信念是關于世界上哪些為真,或是關于環境的動态改變,或是關于其在未來會做什麼。
一些信念狀态的執行個體如下所示:
有固定順序指令隊列的agent的信念狀态可能是一個程式計數器,記錄着該序列的目前位置。48
信念狀态可能包含有用的特定事實,例如,傳送機器人在何處放下包裹去找鑰匙,或者它找鑰匙時已經去過的地方,記住任何目前無法立即觀察卻相對穩定的資訊對agent是有用的。
信念狀态可以編碼成一個模型或者整個世界狀态的部分模型。agent可以保留其對于目前世界狀态的最佳猜測,也可以是可能世界狀态的一個機率分布,詳情内容見5.6節和第6章。
信念狀态可以是世界的動态表示、感覺的意義,agent可以使用其感覺來判斷世界中什麼是正确的。
信念狀态可以編碼為agent的願望、它需實作的目标、它關于世界的信念、它的意圖或者為了實作目标而準備實施的步驟。當agent行動和觀察世界時,這些能被維持,例如,移除已經達成的目标或當發現更适合的步驟時改變意圖。
控制器必須儲存agent的信念狀态并決定每個時刻發出何種指令。當它做這些時,它應該獲得的資訊需包括自身信念狀态和目前感覺。
離散時間下的信念狀态轉換函數可表示為
remember:s×p→s
其中,s是信念狀态集,p是可能認知的集合;st+1=remember(st,pt)表示狀态st+1是在信念狀态st之後觀察到pt得出的信念狀态。
指令函數可表示為
do:s×p→c
其中,s是信念狀态集,p是可能認知的集合,c是可能指令的集合;ct=do(st,pt)表示目前的信念狀态為st,觀察到pt時控制器需要發出的指令ct。
信念狀态轉換函數和指令函數一起描述了agent的因果轉換過程。可以發現,因果轉換是agent曆史的函數,agent不必通路曆史,但指令函數是agent信念狀态和認知的函數,這兩個是agent必須要通路的。
【例2-3】 為了實作例2-2中的因果轉換,控制器必須跟蹤過去20天内的價格。通過使用均值(ave)的跟蹤數值,可以更新均值
ave∶=ave+(new-old)/20
其中,new是最新時刻的價格,old指記住的最早時刻的價格,它在使用後立即會被丢棄。其中最初20天的資料将會做一些特殊處理。49
為了使控制器更加簡單,其不需記憶過去20天的曆史來擷取平均值,而改為僅存儲平均值,并使用平均值來替代最早價格。信念狀态便僅包含一個資料(ave)。更新平均值的狀态轉換函數為
ave∶=ave+(new-ave)/20
這個控制器很容易實作,對于在過去20個時間機關之前發生的變化不敏感。這種保留平均估計值的方法是強化學習中的時間差分法的基礎。
如果僅存在有限的可能信念狀态,控制器可被稱為有限狀态控制器或者有限狀态機。因素化表達是指信念狀态、感覺和指令均由特征來定義。如果存在有限特征,且每個特征僅存在有限種可能的取值,那控制器就是一個因素化有限狀态機。更全面的控制器可以采用無限數量的特征或特征取值來建構。一個有可數狀态的控制器可以計算任何圖靈機可計算的問題。