本節書摘來自華章計算機《資料科學r語言實踐:面向計算推理與問題求解的案例研究法》一書中的第2章,第2.5節,作者:[美] 德博拉·諾蘭(deborah nolan) 鄧肯·坦普·朗(duncan temple lang) 更多章節内容可以通路雲栖社群“華章計算機”公衆号檢視。
我們需要為參加過多次櫻花賽的參賽選手進行記錄比對。由于每位選手的比賽結果沒有唯一的辨別,是以我們需要從每位參賽選手的資訊中構造唯一辨別。理想情況下,我們将使用記錄的全部資訊,即選手的姓名、居住地、年齡、跑步時間和比賽年份。然而,如果這些資訊從某一個年份到下一個年份被記錄的不一緻,可能會減少比對的條數。另一方面,即使使用全部的資訊,我們可能也會錯誤地比對來自兩個不同運動員的記錄。任何設計的方法都不可能完全準确,本節的目的是探讨幾種可能的方法,然後确定其中我們認為合理的一個。
現在考慮下列問題:
14年裡總共有多少參賽選手?
這些參賽選手中有多少不重複的姓名?
有多少姓名出現兩次、三次、四次,等等,最常見的姓名是什麼?
一年之内多次出現的姓名的出現頻率是多少?
回答以上這些問題可以使我們體會到比對問題的量級大小。此外,我們可以考慮如何通過清洗name和home的值來提高比對率。例如,記得前面我們解析文本表格時,在字段末尾附加了一些空格,現在可能是消除它們的好時機。在前面我們也注意到大小寫的不一緻問題,可以證明比對記錄的不确定性。伴随我們開始進一步仔細檢查記錄,其他有關清洗字元串的問題也會随之湧現。在回答這些問題之前,我們先來清洗姓名。
任何出現在一個姓名前面或後面的空格都可以被舍棄。此外,如果出現多個空格,例如,在名字和姓氏之間有多個空格,我們可以把它們轉換成一個。gsub()函數可以實作這些操作。下面我們建立一個幫助函數,trimblanks()來完成該工作:
第一次替代消除所有開始的空格,第二次替代消除所有末尾的空格,第三次用一個空格替代多個連續的空格。注意我們使用元字元“[:blank:]”,這樣可以找到所有形式的空格,包括制表符。清洗姓名如下:
現在可以開始回答關于姓名唯一性的問題了。我們通過檢查概要統計和記錄集合來完成該工作。
14次比賽中共有多少參賽選手呢?用length()函數進行查找:
回顧在前面的部分,我們舍棄了那些比賽用時少于30分鐘和年齡低于16歲的記錄。
那麼有多少不重複的姓名呢?
有多少姓名出現一次、兩次等?我們可以通過調用兩次table()函數來進行判定,也就是
這個表格說明什麼呢?我們可以看到14次比賽中有超過7000個姓名出現了兩次。有一個姓名出現了30次,而我們知道這個姓名至少對應3個人,因為僅僅有14次的比賽結果。
哪個姓名出現了30次呢?我們可以用如下代碼進行查找:
下面來檢查關于30個michael smith的其他資訊。我們從資料框中提取它們:
其居住地包括:
由于額外的空格,這裡出現幾個不同的annapolis md版本。顯然我們也需要清洗home字段。
進一步考慮,我們可能會問:可以通過更多的清洗潛在地提高比對的效率嗎?我們已知列标題有大小寫不一緻的情況,毫無疑問,姓名也存在同樣的問題。我們可以檢查大小寫,但也可以簡單地将所有字元變為小寫字母:
再次檢查最常見的姓名:
通過這次額外清洗又多找到了3個michael smith。
此外,可以删除标點符号,例如某人中間名縮寫的後面及任意零散的逗号,我們通過調用一次gsub()函數進行處理:
既然有如此多重複的姓名,下面我們計算一個姓名在相同年份中出現的次數。可以建立一個年份-姓名的組合表格:
然後調用max()函數來查找有最大計數值的表格單元,即
這又是michael smith嗎?還需要通過一些處理找到與這個最大計數值關聯的名字。這個存儲在tabnameyr裡的表格為table類,我們看到它是一個具有3個屬性的數值向量:dim、dimnames和class。調用class()、mode()和attributes()函數,可以幫助我們得到以上資訊,即
這個資料結構有多重含義。首先,一些矩陣函數可以在table類上進行處理,例如,我們可以調用dim()和colnames()函數進行查找:
注意我們發現了另一條混亂的資料!為了找出是哪個單元中的計數值為5,我們可以使用which()函數,但是要找到行和列的位置,需要在調用中包含arr.ind參數。也就是
最後,對姓名進行定位如下:
它是michael brown,不是michael smith!
現在我們有了一個清洗過的選手姓名的版本,下面将它添加到我們的資料框中:
我們使用這種格式的姓名去建立唯一的選手辨別。
因為我們有選手的年齡和比賽的年份,是以也可以獲得選手近似的出生年份。比賽是在每年4月的第一個星期日舉行,是以這兩者之間的內插補點是對年齡的一個近似。那些生日在4月開始七天内的參賽選手,有可能對他們年齡的記錄在兩個比賽年份中是不一緻的。可以預知記錄的哪些部分會出現這種問題嗎?我們在資料框中建立一個新的變量yob:
另外,我們發現在居住地名裡也有空格和大小寫的問題。這裡将對它們的處理留作練習,要求清洗home值,并将清洗過的home版本添加到cbmensub為homeclean。
下面讓我們更加仔細地檢視在資料框中的這些新的、清洗過的關于michael brown的變量。代碼如下:
針對以上各種不同的michael brown行可以得到怎樣的觀察結果呢?
出生于1953年的3條michael brown記錄好像是同一個人,因為他們的居住地都是“north east md”。除此之外,他3場比賽的用時相差不到7分鐘。
出生于1958年的4條michael brown記錄參加比賽的時間分别是2008年、2009年、2010年和2012年。最近一條記錄的居住地登記的是reston va,而其他的3個居住地顯示為ashburn va。那麼會有1、2、3或者4個不同的michael brown嗎?2010年的該選手是4次比賽中跑得最慢的,差了約11分鐘,其他3次更接近一些。網際網路搜尋顯示,reston和ashburn相距不到22千米。可以猜想這4條記錄屬于同一個人,他可能在2010年4月到2012年4月間從reston搬到了ashburn,但對此我們并不能完全确定。
另外3條記錄中michael brown都出生于1966年。除了在2006年的記錄中州名md沒有提供外,3條記錄的居住地都是chevy chase。當我們檢查2006年其他的參賽選手時,發現他們中也沒有人列出州名。3條michael brown記錄中比賽時間之間也存在11分鐘之差,其中在中間年份2010年跑得最快。是以這些記錄很可能屬于同一個人,但是我們發現2006年記錄中的居住地和其他年份的不同。
接下來,還有4條michael brown的記錄是出生于1984年,參加比賽的時間分别是2008年、2010年、2011年和2012年。其中,2010年記錄中的選手似乎和其他三條記錄中的選手不是同一個人,因為他的居住地是new york,ny,且他的跑步時間也比其他三條紀錄慢了25~40分鐘。其他三條記錄的居住地同為arlington,va,他們的跑步時間也從2008年的84分鐘提升到2012年的71分鐘。是以認為這三條記錄同屬于一個人似乎是合理的,因為一個人随着年齡的增長,他訓練和跑步的速度也會更快。而對此我們同樣不能完全确定。
最後,我們注意到2012年注冊的5條michael brown記錄具有不同的出生年份(1953、1958、1966、1984和1988)和5個不同的居住地,是以這是5位不同的參賽選手。
我們總結各種不同的觀察結果,并第一次嘗試為個體選手建立辨別符,然後可能将清洗後的姓名和推導出的出生年份粘合在一起。代碼如下:
我們忽略居住地和跑步時間所提供的資訊,是以建立了限制最少的辨別符。
由于我們的目标是研究一個運動員跑步時間随着年齡增長的變化,下面讓我們重點關注那些id至少出現8次的選手。為了完成這個目标,我們首先判定每個id在cbmensub中出現的次數,代碼如下:
然後選擇那些id至少出現8次的記錄:
我們選擇屬于這些辨別符的記錄建構子集menres:
最後,組織資料框使相同id的記錄相連,這樣就使諸如手工檢查記錄等操作變得更加容易:
另一種資料組織方式是将races8中每一個id的元素存儲為一個清單。該清單中,每個元素是一個資料框且僅包含具有相同id的記錄結果。通過如下代碼建立清單:
其中哪種資料結構更好呢?這将取決于我們想如何處理資料。接下來,我們将展示如何使用兩種方法來完成一項任務,以便在這兩種資料結構之間進行比較。在下一節中,我們會發現使用資料框中的清單進行處理是最容易的,因為我們常常需要将含有多個參數的函數應用于每個參賽選手的記錄。
建立清單後還剩下多少個id呢?
這和代碼length(men8l)的功能是一樣的。如果兩年間的比賽成績變化太大,我們可能就會放棄記錄的比對。那麼多大的起伏變化會讓我們認為是錯誤地連接配接了兩個不同的選手呢?當然,我們不想通過消除跑步時間變化很大的個體而使結果産生偏見。下面讓我們檢視一些在相鄰兩年内跑步時間之差超過20分鐘的記錄。使用如下方法找出那些滿足該限制的記錄:
或者使用
有多少時間差超過20分鐘的選手?
前兩位運動員經過稍微重新格式化的顯示結果如下:
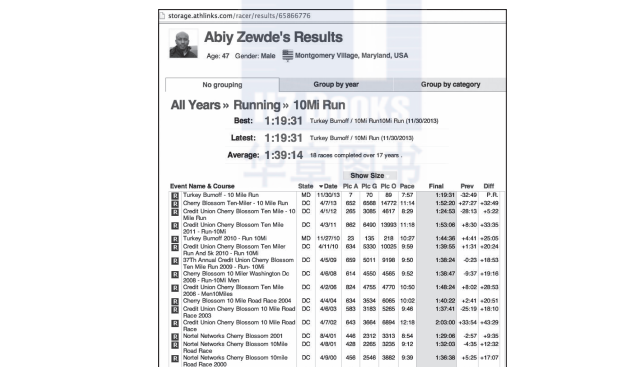
想用同一個居住地來進一步限制我們的比對項嗎?這樣可以消除諸如abiy zewde記錄中的不同,盡管我們相當确定這些記錄是屬于同一個人的。我們可以識别不當比對,并手動檢查潛在的錯誤比對結果。因為2006年的記錄中沒有州名,是以我們需要從那些記錄項的末尾去除州名的縮寫。可以用一個空字元串替換出現在字元串末尾的一個空格及後面跟着的兩個字母。例如:
這可能會導緻太過自由的比對,例如,比對springfield il和springfield ma。在此我們将它留作練習,确定如何将比對限制到那些具有相同居住地的記錄中,并評估是否應該在比對過程中添加額外的限制條件。
這裡,我們考慮一個不太嚴格的比對,僅僅比對那些具有相同居住州的記錄。為此,我們建立一個新的變量來儲存州名的兩個縮寫字母。因為資料結構比較簡單,我們傳回去處理cbmensub,并保持一緻性。從每個居住地的字元串中提取最後2個字母。如果存在,它就是州名。我們知道在2006年的記錄中沒有出現州名,是以将其設定為na。對于來自美國以外的運動員,提取國家或者省份的最後兩個字母,但這些不應該顯著地影響我們的比對。
首先确定在每個home值中有多少個字母,代碼如下:
然後使用如下代碼提取最後兩個字母,并将它們添加回資料框裡:
并且将2006年的值設定為na:
接下來,我們重新建立一個新的id以使其包含state,代碼如下:
然後,我們再次選擇那些至少出現8次的id。代碼如下:
在下一節中,我們将單獨使用清單結構來進行處理。
這次添加完選手的id後,進一步減少了完成8次比賽的選手數量,即
現在有306名運動員具有相同的姓名、出生年份和州名,并且都完成了14次比賽中的8次。迄今為止我們一直在已獲得的比對集合上進行處理,在下一節,我們将研究參賽選手的成績如何随着年齡增長而變化