本節書摘來自華章計算機《資料科學r語言實踐:面向計算推理與問題求解的案例研究法》一書中的第1章,第1.2節,作者:[美] 德博拉·諾蘭(deborah nolan) 鄧肯·坦普·朗(duncan temple lang) 更多章節内容可以通路雲栖社群“華章計算機”公衆号檢視。
###1.2 原始資料
在crawdad(a community resource for archiving wireless data at dartmouth)[2]網站上有兩個可用于開發ips的相關資料集。一個是“離線”的參照資料集,它包含了一組用手持裝置測量的信号強度資料,這些資料是在曼海姆大學某大樓的一層大廳裡按1米間隔共166個點組成的網格上測出的。樓層平面為15m×36m,如圖1-1所示。平面上的灰色圓點标示出具有離線測量值的位置,黑色方塊标示出6個接入點。這些參照位置給出了大樓的信号強度的校準資料集,使用它們可建立一個關于手持裝置位置的預測模型。當該手持裝置的位置未知時,可以用該模型進行位置預測。
除了提供手持裝置的坐标(x,y)之外,還提供裝置的方向資料。信号強度按照45霸隽浚?、45、90等)在8個方向上分别加以記錄。此外,關于資料的說明文檔中指出,對6個接入點的每一種“位置-方向”組合,共記錄了110個信号強度測量值。
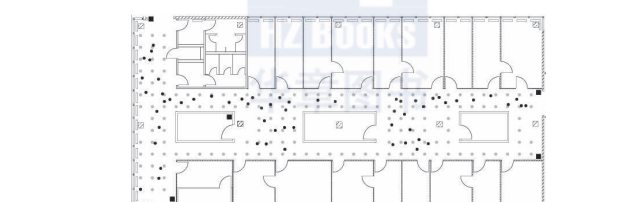
圖1-1 測試環境的樓層平面圖。圖中,用黑色方塊标示6個固定的無線接入點,用灰色圓點标示收集有離線/訓練資料的位置。在用黑色圓點标示的點上,記錄線上資料的測量值,這些點是随機選擇的。灰色圓點之間的空間距離為1m
除了離線資料之外,第二個資料記錄集稱為“線上”資料集,也用于建立預測位置的模型。在這些資料中,随機選擇了60個位置和方向,測量了它們距每個接入點的110個信号值。在圖1-1中,這些測試位置用黑色圓點标示。在離線資料集和線上資料集中,110個信号值中的某一些值并沒有在資料集中記錄下來,反而在實驗單元附近的其他手持裝置(如手機或筆記本電腦)的測量值卻儲存在某些離線資料記錄中。
資料的說明文檔[2]描述了資料檔案的格式。我們自己可以用文本編輯器來檢視檔案。這兩個檔案(離線和線上)具有相同的基本格式,檔案的開頭如下所示:
注意,從第4行到随後顯示的各行在文本中實際上是一行,為了更具可讀性,這一行被格式化為多行。我們加了符号來訓示行的連續。
文檔說明資料的格式如下:
這裡,關于測量單元的描述如表1-1所示。mac(媒體通路控制)變量指的是硬體裝置的mac位址,它是使得一台計算機、一個接入點或者一件裝置的網卡可在網絡中被識别出來的唯一辨別符[5]。按照約定,辨別符的形式寫作mm:mm:mm:ss:ss:ss,這裡mm和ss是兩個十六進制位(0,1,…,9,a,b,c,d,e,f)。開始的3對數字組mm:mm:mm辨別裝置的制造商。後面的3對數字組(ss)辨別具體的裝置,對應其型号和唯一的裝置号。

。
資料中的macofresponse1...macofresponsen表示:一個記錄行由不固定個數的mac位址上的測量值組成。就是說,這些記錄不是等長的,它們形成了一個參差數組,每行的長度依賴于檢測到的信号個數。例如,請看輸入檔案的另外一行(第2000行):
通過上面的資料我們可以看出:該記錄有8個讀數;mac位址出現的次序與上述第一個記錄不同;同一個接入點有兩個讀數(8a接入點);8個位址中有一個屬于adhoc裝置,因為按照表1-1,模式的數字代碼訓示該讀數是屬于adhoc裝置(mode值為1)還是屬于接入點(mode值為3)。再回頭看第一個觀測值記錄,我們會注意到超過6個mac位址具有模式3。這些“額外”的資料來自大樓的另外一層。
現在我們已經對輸入檔案的格式有了一定的認識,下面就可以确定如何将資料讀入到友善進行分析的存儲結構中。首先,我們要考慮如何用r來表達最終的結果資料[8]。有兩種顯而易見的合理選擇。第一種是将輸入檔案中的每一行對應于資料框中的一行。對于這種情況,資料框中的變量分别是時間、mac-id、x、y、z(手持裝置的位置)、方向以及各個mac位址所對應的4個變量(用來表示采集到的信号,包括信号、信道、裝置類型以及mac位址)。由于原始觀測記錄包含不同個數的信号記錄,是以我們的資料框需要有足夠多的列以支援包含最多信号數量的記錄。
第二種方法是先使用相同個數的初始變量來描述手持裝置,即時間、mac位址、位置和方向。然後,使用另外4個變量描述接收到的信号:接收到信号的裝置的mac位址、信号、信道和裝置的類型。這樣,每個接收到的信号對應于資料框中的一行。結果是,輸入檔案中的每一行記錄轉化成資料框的多行記錄,其行數等于輸入檔案行中由“;”分割開的mac位址的個數。例如,在資料框中,上面輸入檔案的第一條記錄變成了11行記錄,第2000條觀測記錄變成了8行記錄。
第一種方法為自然的表達方式,能夠更直接地對應于輸入檔案的格式,也避免了重複時間、位置等資訊,看起來更省存儲空間。但是,它帶來的一個難題是我們必須提前确定需要多少列,更具體地說,從該裝置上可以接收到多少個mac位址。即使删除了adhoc列,仍然要求處理來自同一個mac位址的不同次序的記錄和多個測量值。這樣就很可能需要進行兩遍資料處理,才能夠建立起該資料框:在第一遍确定唯一的mac位址,在第二遍進行資料組織。盡管我們避免了重複存儲一些資訊,如時間戳,但是,對于沒有從任何mac位址記錄到信号的那些觀測結果,需要使用na值來表示。如果有很多這樣的值,則采用第二種方法實際上更省存儲空間。第二種方法也簡化了資料框的建立過程。
使用第二種方法,我們避免了對資料的兩遍處理,隻需一遍就能把檔案讀入資料框。并且,資料框這種資料結構允許我們對mac位址使用group-by操作。是以,我們先使用第二種方法。以後,我們再介紹如何按第一種方法建立資料框。那時,我們不需回到原始檔案,而是用已有的資料框來建立另一個資料框。
在确定如何将資料讀進r時,另一個需要考慮的問題是,“注釋”行是否隻出現在檔案的頭部。我們可以搜尋檔案,找出這些以“#”開始的行。為此,我們需要用readlines()函數将整個文檔讀進r。
這樣,離線檔案中的每一行作為字元串讀進r的字元向量txt之中。我們使用substr()函數定位以“#”開始的行或字元串,并對其個數進行求和:
接下來,我們執行length()函數:
确定出離線檔案共有151 392行。按照文檔說明,我們預期在檔案中有146 080行的觀測記錄(166個位置×8個角度×110個讀數)。兩者之差是5312(151 392-146 080),正好是注釋行的個數。
總之,可以遵循的常用經驗是,要仔細檢查關于檔案格式的假定,而不是依賴于隻檢視檔案開頭的少數幾行說明。
對原始資料的處理
現在,我們确定了資料在r中按照預期目标的表示形式,下面就可以編寫代碼從輸入檔案中抽取資料并處理成這種形式。由于輸入檔案中的資料不是以方形表格形式表示的,是以不能直接使用類似于read.table()的函數。不過,可以利用觀測記錄中的結構來處理文本行。例如,主要的資料元素是以分号分隔開的。下面我們看看如何用分号劃分第4行,該行是檔案中第一個非注釋行。
在上面每個短字元串中,變量的“名字”和與其關聯的值被“=”分隔開。在某些情況下,這個值包含用“,”分隔開的多個值,例如,"pos=0.0,0.0,0.0"由3個未命名的變量組成。
對于這個按照分号進行劃分而産生的向量,可以進一步在“=”字元處劃分出每個元素。再接着對這個結果在“,”字元處進行劃分。處理如下:
最終将得到一個長長的字元向量,第一條資料記錄中所有的變量名字和資料值都作為單獨的“tokens”(标記)存在于該向量中。接着可以把它們整理成合适的形式。不過,我們可以做得更簡單、更通用一些,由于strsplit()中的split參數可以是正規表達式,這樣,在一個函數調用中,可以在任何幾個字元上做劃分。這意味着可以使用如下調用,在“;”“=”或者“,”字元處做劃分:
在我們編寫更多的代碼來讀取這些資料之前,不禁會問:read.table()是否也可使用正規表達式作為分隔符?如果可以,就可以用它來替代readlines()。遺憾的是,因為它讀取正常文本檔案的速度相當慢,是以不能用它替代。
基于strsplit()的結果,我們得到了第一行中的所有資料元素。tokens中前10個元素給出了手持裝置的資訊。
我們可以用如下語句從這些變量中提取資料值。
我們知道這些值對應于如下變量:時間、mac位址、x、y、z以及方向。
下面我們來處理觀測結果中記錄的信号資料。它們是被劃分的向量中餘下的資料值。
我們可以将其看成是一個4列矩陣或一個資料框,所包含的列分别對應于mac位址、信号、頻道、裝置類型。對這些行進行分解,利用分解後的值就可建立起一個矩陣。然後,我們将這些列與記錄的前10個中的某些值綁定到一起。做法如下:
這樣,将生成一個11行10列的矩陣,每一行對應一個mac位址,并且有6列對于所有的mac位址具有相同的值(如位置和方向)。
我們把這些代碼放到一個函數中,這樣,可以對輸入檔案中所有的行都重複執行該操作。即
讓我們将該函數應用于輸入檔案的若幹行:
注意,我們從檔案的第4行開始,因為前3行是注釋。執行結果是一個包含了17個矩陣的清單。用如下指令可以确定在每個點上有多少個信号被檢測到:
至此,我們完成了較困難的部分。當然,我們更想把這些單個的矩陣轉成一個統一的資料框。我們可以使用do.call()函數将這些矩陣堆積到一塊。我們也可能傾向于寫一個循環語句,将第二個矩陣級聯到第一個矩陣,再将第三個矩陣級聯到第二個矩陣,依次類推。但這處理起來非常慢(可以嘗試一下!)。而利用do.call()函數能夠簡單而高效地實作矩陣的堆積。我們在調用do.call()時,隻需指定将要調用的函數名和由各個參量構成的一個清單即可,而我們通常的做法是将這些參量分開傳遞給該函數。這樣,我們隻需簡單地執行如下語句:
現在,我們嘗試對整個資料集執行這個代碼。首先,丢棄以注釋字元“#”起始的行,再将其他的行傳遞給processline()。
當我們運作這個代碼時,會得到如下形式的6條警告消息:
一般來說,我們應對警告消息保持特别警覺。
雖然通過仔細檢視輸出結果,我們可以找到這些警告消息所對應的程式行。但是,如果能在警告消息出現時就立即檢視,則更容易找到這些程式行。我們可以要求r系統在給出警告消息的同時抛出一個出錯消息,這時可浏覽調用棧,檢查計算狀态。為此,可以設定一個選項來處理錯誤,并設定另外一個選項将警告消息變更為出錯消息:
下面,我們用這些新選項再次運作lapply()調用:
當第一個警告消息出現時,系統給出如下消息和調用棧。
我們選擇3,對應于processline()函數。我們可以向這個調用框發出r指令。例如,我們可以檢視ls()函數有什麼變量。再檢查變量x,看到它的值如下:
對于這個值,我們注意到在這個位置上沒有檢測到任何信号。這個觀測值屬于異常情況,需要用processline()函數加以處理。
我們可以修改processline()函數,要麼丢棄這種觀測值,要麼在資料框中增加一行,包含該手持裝置資訊,而對應的mac位址、信号值、頻道和裝置類型都設為na值。當一個觀測值無助于建立定位系統時,我們就丢棄它。我們将該函數修改為,當tokens向量隻有10個元素時,就傳回null。修改後的函數如下:
我們再次運作更新後的processline()函數,看看警告消息是否消失了。
的确不再收到警告消息。我們的資料框offline共有100多萬個資料行:
該資料框由字元值變量組成。下一步是将這些值轉換為适當的資料類型,例如,将信号強度轉換為數值型,并按照需要做進一步的資料清洗。這是下一節的主題。