本節書摘來自華章計算機《spark與hadoop大資料分析》一書中的第1章,第1.2節,作者:文卡特·安卡姆(venkat ankam) 更多章節内容可以通路雲栖社群“華章計算機”公衆号檢視。
資料科學的工作展現在以下這兩個方面:
從資料中提取其深層次的規律性
建立資料産品
要從資料中提取其深層次的規律性,意味着要使用統計算法提煉出有價值的資訊。資料産品則是一種軟體系統,其核心功能取決于對資料的統計分析和機器學習的應用。google adwords或facebook裡的“你可能認識的人”就是資料産品的兩個例子。
1.2.1 從資料分析到資料科學的根本性轉變
從資料分析到資料科學的根本轉變的根源,是對更準确的預測和建立更好的資料産品需求的不斷增長。
讓我們來看一個示例,其中解釋了資料分析和資料科學之間的差異。
問題:某大型電信公司有多個呼叫中心,負責收集呼叫者資訊并将其存儲在資料庫和檔案系統中。該公司已經對呼叫中心資料實施資料分析,提供了以下分析結果:
服務的可用性
平均應答速度、平均通話時間、平均等待時間和平均呼叫時間
呼叫的放棄率
首次呼叫解析率和每次通話的費用
座席占用情況
現在,該電信公司希望減少客戶流失,改善客戶體驗,提高服務品質,并通過以接近實時的方式了解客戶的情況,進行交叉銷售和向上銷售。
解決方案:分析客戶的聲音。客戶的聲音比任何其他資訊都有更深刻的含義。我們可以使用cmu sphinx等工具将所有呼叫轉換為文本,并在hadoop平台上進行擴充。我們可以進行文本分析以從資料中擷取分析結果,獲得高精确度的呼叫–文本轉換,建立适合該公司的模型(語言和聲學),并根據業務發生變化的頻度,随時重新訓練模型。此外,可以利用機器學習和自然語言處理(natural language processing,nlp)技術建立用于文本分析的模型,提供以下名額,合并到資料分析的名額裡:
客戶流失的主要原因
客戶情感分析
客戶和問題的劃分
客戶的 360 度視角
請注意,這個用例的業務需求産生了從資料分析到實作機器學習和nlp算法的資料科學的根本轉變。為了實施這個解決方案,需要使用新的工具和技術,還需要一個新的角色:資料科學家。
資料科學家具備多種技能—統計、軟體程式設計和業務專業知識。資料科學家能夠建立資料産品,并從資料中提煉出價值。讓我們來看看資料科學家與其他角色有什麼不同。這會有助于我們了解在資料科學和資料分析項目中有哪些角色,以及他們要承擔哪些工作。
資料科學家與軟體工程師
資料科學家和軟體工程師角色之間的差別如下:
軟體工程師根據業務需求,開發通用的應用軟體
資料科學家不開發應用軟體,但他們開發軟體來幫助解決問題
通常,軟體工程師使用java、c++和c#等程式設計語言
資料科學家往往更重視像python和r這樣的腳本語言
資料科學家與資料分析師
資料科學家和資料分析師角色之間的差別如下:
資料分析師使用sql和腳本語言進行描述性及診斷性分析,進而建立報告和儀表闆。
資料科學家使用統計技術和機器學習算法來進行預測性及規範性分析,進而找到答案。他們通常會使用諸如python、r、spss、sas、mllib和graphx之類的工具。
資料科學家與業務分析師
資料科學家和業務分析師角色之間的差別如下:
兩者都關注業務,是以他們可能會提出類似的問題
資料科學家具備找到答案所需的技術技能
1.2.2 典型資料科學項目的生命周期
讓我們學習如何了解和執行典型的資料科學項目。
從圖1-4中所示的典型資料科學項目的生命周期可以看出,資料科學項目的生命周期是疊代的,而如圖1-3所示的資料分析項目的生命周期卻不是疊代的。在對項目結果進行改善的情況下,定義問題和結果以及溝通這兩個階段沒有包含在疊代中。然而,整個項目的生命周期是疊代式的,它需要在生産實施後不斷地改進。
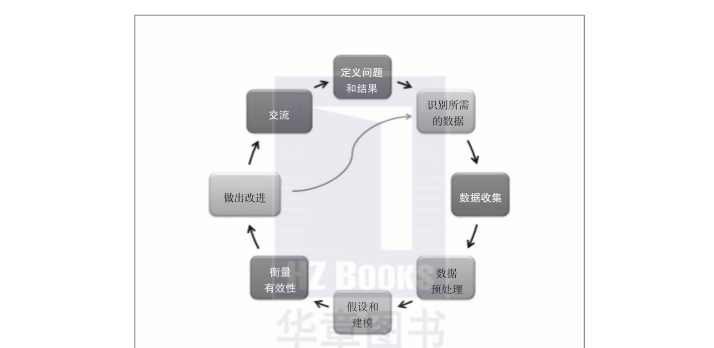
圖1-4 資料科學項目的生命周期
在資料預處理階段,定義問題和結果的步驟與資料分析項目類似,如圖1-3所示。是以,讓我們來讨論資料科學項目所需的新步驟。
假設和模組化
對于具體問題,要考慮所有能夠和預期結果相比對的可行解決方案。這通常涉及關于這個問題的根本原因的假設。這樣,關于業務狀況的問題就會浮現出來,例如為什麼客戶會取消服務,為什麼支援電話會顯著增加,以及為什麼客戶會放棄購物車。
如果我們對資料有更深入的了解,根據某個假設就可以确定合适的模型。這就關系到了解資料的屬性及其互相關系,并通過定義用于測試、訓練和生産的資料集來建構模組化所需的環境。我們可以利用機器學習算法(如邏輯回歸、k均值聚類、決策樹或樸素貝葉斯等)來建構合适的模型。
衡量有效性
模型的執行是通過針對資料集運作确定的模型來進行的。通過利用正确的輸出對結果進行核對可以衡量模型的有效性。我們可以使用測試資料驗證結果,并建立像均方差(mean squared error,mse)之類衡量有效性的名額。
做出改進
從衡量結果可以看到需要改進的程度有多大。要考慮你會做出哪些改變。你可以問自己以下問題:
圍繞問題的根本原因所做出的那些假設是否正确?
提取更多的資料集是否會産生更好的結果?
是否有其他解決方案能産生更好的結果?
一旦你實施了改進措施,就要對它們再次進行測試,并将它們與以前的衡量結果進行比較,以進一步改進解決方案。
交流結果
針對結果的交流是資料科學項目生命周期中的重要一步。資料科學家描述資料中的發現的方式是把這些發現和業務問題關聯起來。報表和儀表闆是交流結果的常用工具。
1.2.3 hadoop和spark 承擔的角色
apache hadoop為你提供了分布式存儲和資源管理功能,而spark為你提供了資料科學應用程式所需的記憶體級性能。對于資料科學項目來說,hadoop和spark有以下的優點:
廣泛的應用和第三方元件包
一個便于使用的機器學習算法庫
spark 能夠和深度學習庫(如 h2o和tensorflow)內建
可以利用 scala、python和r的shell進行互動式分析
統一的特性—可以把sql、機器學習和流式傳輸一起使用
![9.spark Core 進階2--Cashe[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)