你每次打開用戶端(如 yahoo news 或者 yahoo sports),你想優先獲得什麼樣的文本資訊?雖然每個人的喜好不同,但你想知道的永遠有關文本中的人物,組織和位置資訊。自動搜尋此類資訊的系統被稱為「實體名稱識别和連結系統(named entity recognition and linking systems)」。它是文本分析中最重要的系統,許多應用都會使用到它,例如搜尋引擎、推薦系統、問答系統和情緒分析系統。
實體名稱識别和連結系統使用統計模型,通過大量經過标記的文本進行訓練。這種方法面臨的主要挑戰是在不同語言、長文本、缺乏标記的資料中準确探測實體,同時不需要耗費過多的系統資源(記憶體和處理器資源)。
在雅虎長期研究和不斷應用這些解決方案之後,我們很高興為開源社群貢獻我們的這一工具:fast entity linker,我們的無監督、準确、可擴充多語言實體名稱識别和連結系統,同時也包含英語、西班牙語和中文資料包。
為了增加可用性,我們的系統将文本實體連結至維基百科。例如,當語句中出現「雅虎是一家總部位于加州 sunnyvale 的公司,ceo 是 marissa mayer」時,這一系統會點出以下實體:
在算法上,我們使用了實體嵌入,click-log 資料和高效聚類等方法來實作高精度。該系統通過使用壓縮資料結構和主動散列函數以實作低記憶體占用和快速執行。
「實體嵌入(entity embeddings)」是基于向量的表示,它捕獲上下文中引用實體的方式。我們使用維基百科文章訓練實體嵌入,并在文章中使用超連結格式來建立規範實體。使用下圖中的神經網絡架構來模組化實體的上下文和表征,其中實體向量經過訓練不僅會預測其周圍實體,而且可以預測包含詞序列的全局上下文。這種方式分為兩層,一層實體上下文模型,另一層表征上下文模型。我們使用和用于訓練段落向量的相同技術(quoc 和 mikolov,2014)來連接配接這兩個層。
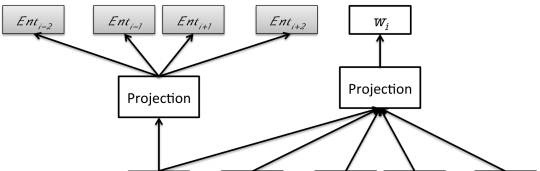
同時訓練字嵌入和實體嵌入的架構。「ent」表示實體,「w」表示它們的上下文單詞
搜尋 click-log 資料提供了非常有用的信号來消除局部歧義或實體歧義。例如,搜尋「fox」的人傾向于點選「fox news」而不是「20th century fox」,我們可以使用這些資料來識别文檔中的「fox」。為了消除實體歧義,并確定文檔具有一緻的實體集合,我們的系統支援三個實體消歧算法:
forward backward algorithm (austin et al. 91)
exemplar clustering (frey and dueck 『07)
label propagation (talukdar and crammer 『09)
目前,隻有前向後向算法(forward backward algorithm)在我們的開源版本中是可用的,其他兩個算法将很快可用!

當常用候選項是實體歧義的錯誤選項時,這些算法非常有助于精确地連結實體。在下面的例子中,這些算法利用周圍語境能準确地将 manchester city、swansea city、 liverpool、chelsea 和 arsenal 等詞組連接配接到它們各自的足球俱樂部。模糊提及能用紅色突出指明多個實體,例如 chelsea 可以指紐約或倫敦的 chelsea 區,或一家著名的足球俱樂部。明确的實體命名以綠色突出顯示,在上例中引用的模糊和無歧義示例的實體連結候選項進行檢索過程中,正确的候選項就以綠色突出顯示。
目前,快速實體連結器(fast entity linker)是僅有的三個可用于多語言實體命名識别和連結系統(其他是 dbpedia spotlight 和 babelfy)之一。除了獨立的實體連結器,這一軟體還包括了可用于建立和壓縮來自維基百科的不同語言中的詞/實體嵌入和資料包等工具。其中,包含了所有英語維基百科資訊的資料包隻有 2gb!
這個系統的技術基礎在下面兩篇科學論文中被詳細論述:
roi blanco, giuseppe ottaviano, and edgar meij:「fast and space-efficient entity linking in queries.」in proceedings wdsm 2015.
aasish pappu, roi blanco, yashar mehdad, amanda stent, and kapil thadani:「lightweight multilingual entity extraction and linking.」in proceedings wsdm 2017.
開源工具包中有許多可用的應用程式,其中之一是将情緒歸于文本中檢測到的實體,而不是整個文本本身。例如考慮以下來自 metacritic 使用者對電影《但丁密碼》的實際評論:「雖然湯姆·漢克斯的表演很好,制片商也創造了一個神秘而生動的電影,但是劇情還是很難了解。雖然這部電影情節婉轉有趣,但我對哥倫比亞影業的期待不止如此」。是以雖然最後的評論是中立的,但是它同樣傳遞了對于湯姆·漢克斯積極情緒和對哥倫比亞電影公司的消極情緒。
許多現有的情緒分析工具将與文本相關聯的情感值整理作為一個整體處理,這使得系統很難跟蹤使用者對任何單獨實體的情緒。使用我們的工具包,開發者們可以讓系統自動提取給定文本中的「正面」和「負面」資訊,進而更清楚地了解使用者對各個單獨實體的情緒。