本節書摘來華章計算機《hadoop與大資料挖掘》一書中的第2章 ,第2.5節,張良均 樊 哲 位文超 劉名軍 許國傑 周 龍 焦正升 著 更多章節内容可以通路雲栖社群“華章計算機”公衆号檢視。
2.5.1 k-means算法原理
k-means算法是硬聚類算法,是典型的基于原型的目标函數聚類方法的代表。它是将資料點到原型的某種距離作為優化的目标函數,利用函數求極值的方法得到疊代運算的調整規則(如圖2-45所示)。k-means算法以歐氏距離作為相似度測度,求對應某一初始聚類中心向量v最優分類,使得評價名額最小。算法采用誤差平方和準則函數作為聚類準則函數。
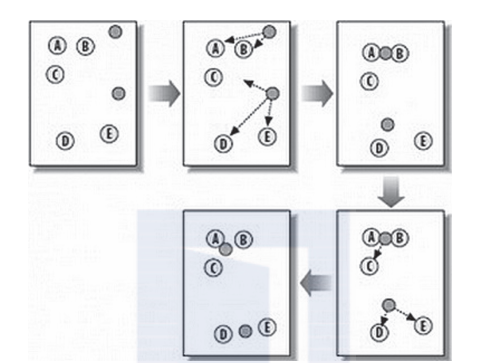
具體的算法步驟如下:
1)随機在圖中取k(這裡k=2)個種子點。
2)然後對圖中的所有點求到這k個種子點的距離,假如點pi離種子點si最近,那麼pi屬于si點群。圖2-45中,我們可以看到a、b屬于上面的種子點,c、d、e屬于下面中部的種子點。
3)接下來,我們要移動種子點到屬于它的“點群”的中心。見圖2-45中的第3步。
4)然後重複第2)和第3)步,直到種子點沒有移動。我們可以看到圖2-45中的第4步上面的種子點聚合了a、b、c,下面的種子點聚合了d、e。
圖2-46所示為k-means算法的流程圖。

該流程圖描述其實和算法步驟類似,不過,這裡需要考慮下面幾個問題:
1)選擇k個聚類中心用什麼方法?
提示:可以随機選擇或直接取前k條記錄。
2)計算距離的方法有哪些?
提示:歐氏距離、餘弦距離等。
3)滿足終止條件是什麼?
提示:使用前後兩次的聚類中心誤差(需考慮門檻值小于多少即可);使用全局誤差小于門檻值(門檻值選擇多少?)。
請讀者考慮上面的幾個問題,并完成下面的動手實踐(k-means算法實作)。