本節書摘來自華章社群《python資料挖掘:概念、方法與實踐》一書中的第1章,第1.1節什麼是資料挖掘,作者[美] 梅甘·斯誇爾(megan squire),更多章節内容可以通路雲栖社群“華章社群”公衆号檢視
1.1 什麼是資料挖掘
前文解釋了資料挖掘的目标是找出資料中的模式,但是細看之下,這一過分簡單的解釋就站不住腳。畢竟,尋找模式難道不也是經典統計學、商業分析、機器學習甚至更新的資料科學或者大資料的目标嗎?資料挖掘和其他這些領域有什麼差别呢?當我們實際上是忙于挖掘模式時,為什麼将其稱作“資料挖掘”?我們不是已經有資料了嗎?
從一開始,“資料挖掘”這一術語就明顯有許多問題。這個術語最初是統計學家們對盲目調查的輕蔑叫法,在這種調查中,資料分析人員在沒有首先形成合适假設的情況下,就着手尋找模式。但是,這一術語在20世紀90年代成為主流,當時的流行媒體風傳一種激動人心的研究,将成熟的資料庫管理系統領域與來自機器學習和人工智能的最佳算法結合起來。“挖掘”這一單詞的加入預示着這是現代的“淘金熱”,執著、無畏的“礦工”們将發現(且可能從中得益)之前隐藏的珍寶。“資料本身可能是珍稀商品”這一思路很快吸引了商業上和技術刊物的注意,使他們無視先驅們努力宣傳的、更為全面的術語—資料庫中的知識發現(kdd)。
但是,“資料挖掘”這一術語沿用了下來,最終,該領域的一些定義試圖改變其解釋,認為它指的隻是更漫長、更全面的知識發現過程中的一步。今天“資料挖掘”和kdd被視為非常相似、緊密相關的術語。
那麼,其他相關術語如機器學習、預測性分析、大資料和資料科學又是怎麼回事?這些術語和資料挖掘或者kdd是不是一回事?下面我們比較這些術語:
機器學習是計算機科學中的一個非常特殊的子領域,其焦點是開發能從資料中學習以作出預測的算法。許多資料挖掘解決方案使用了來自機器學習的技術,但是并不是所有資料挖掘都試圖從資料中作出預測或者學習。有時候,我們隻是想要找到資料中的一個模式。實際上,在本書中,我們所研究的資料挖掘解決方案中隻有少數使用了機器學習技術,而更多的方案中并沒有使用。
預測性分析有時簡稱為分析,是各個領域中試圖從資料中作出預測的計算解決方案的統稱。我們可以思考商業分析、媒體分析等不同術語。有些(但并不是全部)預測性分析解決方案會使用機器學習技術進行預測,但是同樣,在資料挖掘中,我們并不總是對預測感興趣。
大資料這一術語指的是處理非常大量資料的問題和解決方案,與我們是要搜尋資料中的模式還是簡單地存儲這些資料無關。對比大資料和資料挖掘這兩個術語,許多資料挖掘問題在資料集很大時更為有趣,是以為處理大資料所開發的解決方案遲早可用于解決資料挖掘問題。但是這兩個術語隻是互為補充,不能互換使用。
資料科學是最接近于kdd過程的術語,資料挖掘是它們的一個步驟。因為資料科學目前是極受歡迎的流行語,它的含義将随着這一領域的成熟而繼續發展和變化。
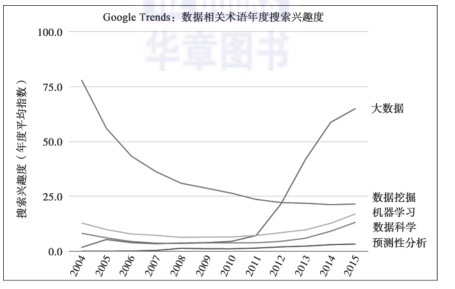
我們可以檢視google trends,了解上述術語在一段時期内的搜尋熱度。google trends工具展示了一段時期内人們搜尋各種關鍵詞的頻度。在圖1-1中,新出現的術語“大資料”目前是炙手可熱的流行語,“資料挖掘”居于第二位,然後是“機器學習”、“資料科學”和“預測性分析”。(我試圖加入搜尋詞“資料庫中的知識發現”,但是結果太接近于0,無法看到趨勢線。)y軸以0~100的指數顯示了特定搜尋詞的流行度。此外,我們還将google trends給出的2014~2015年每周指數組合為月平均值。
![筆試面試題目:滑動視窗(二)[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)