本節書摘來自華章出版社《短文本資料了解(1)》一書中的第1章,第1.1節,作者[美]孟衛一(weiyi meng)紐約州立大學賓漢姆頓分校於德(clement t.yu)伊利諾伊大學芝加哥分校,更多章節内容可以通路雲栖社群“華章計算機”公衆号檢視
短文本廣泛地存在于網際網路的各個角落,如搜尋查詢、廣告關鍵字、錨文本、标簽、網頁标題、線上問題、微網誌等,都屬于短文本。一般而言,短文本字數少,沒有足夠的資訊量來進行統計推斷,是以機器很難在有限的語境中進行準确的語義了解。此外,由于短文本常常不遵循文法,自然語言處理技術如詞性标注和句法解析等,難以直接應用于短文本分析。正是由于這些特性,使得讓機器正确了解短文本十分困難。然而,短文本了解又是一項對于機器最終實作人工智能至關重要的任務,其在知識挖掘領域有很多潛在應用,如網頁搜尋、線上廣告、智能問答等。那麼,如何才能夠破解其中的挑戰呢?
我們不妨首先跳出機器的範疇,看看人類是如何了解短文本的。對于人類而言,了解這些短文本是十分簡單的。即使是一個10歲左右的兒童,當他們看到短文本(如搜尋查詢)時,都可以正确地了解這些短文本的含義。究其原因,是由于人類具有“思維”,能夠積累知識并做出推斷。例如,給出兩個查詢語句“band for wedding”和“wedding band”,人類可以清楚地判斷前者指的是一項“婚禮樂隊服務”,而後者是“結婚戒指”。而這種知識的積累,是人們通過不斷學習而獲得的。
為了使機器也具有類似的能力,先前的研究往往也會構造出一些知識庫系統,如freebase、yago等為機器“裝備”知識。這些知識庫大多包含大量實體以及與之相關的事實。以搜尋引擎或問答系統為例,基于這些事實,機器可以通過查詢的方式擷取輸入問題的答案。然而,如圖11所示,在機器回答問題前,首先需要解決的是“了解”問題,這也是這一過程中的最大挑戰。
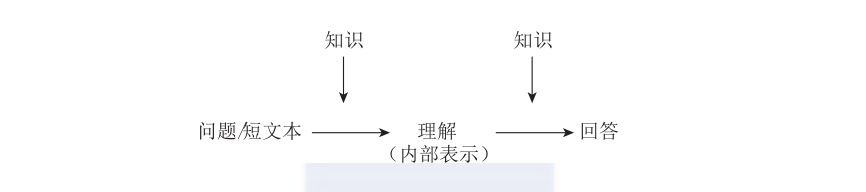
通過深入研究,我們發現了解短文本所需要的知識與回答短文本所需要的知識并不相同。例如,針對短文本“世界上第三大瀑布”,10歲的兒童可以正确了解其含義,但是卻不一定能夠正确回答這個問題。這是因為,了解短文本更需要的是常識性知識(注重廣度),而回答短文本更需要的是專業性知識(注重深度)。是以,傳統的知識庫系統并不能很好地解決短文本了解問題。
為了克服機器了解短文本的障礙,先前基于短文本的應用常通過枚舉和關鍵詞比對的方式避免“了解”這一任務。以自動問答系統為例,可事先建構關于問題和答案比對的清單,這樣線上查詢時隻需對清單中的條目進行比對即可。近年來随着自然語言處理技術的發展,主流的搜尋引擎正逐漸從基于關鍵詞的搜尋向文本了解過渡。例如,給出“apple ipad”這個短文本,機器需要明白“apple”所指為品牌名而不是水果。
為了實作自動化的短文本了解,許多相關工作[54,153,172]證明,這一過程相當依賴額外的知識。這些知識可以幫助機器充分挖掘短文本中詞與詞之間的聯系,如語義相關性。例如,在英文查詢“premiere lincoln”中,“premiere”是一個重要的資訊,表明“lincoln”在這裡指的是movie(電影);同樣,在“watch harry potter”中,正因為“watch” (觀看)的出現,“harry potter”的含義可被判定為movie(電影)或dvd,而不是book(圖書)。但是,這些關于詞彙的知識(例如“watch”的對象通常是movie)并沒有在短文本中明确表示出來,因而需要通過額外的知識源擷取。圖12展示了所有短文本了解方法在知識源屬性和粒度的二維坐标軸中對應的位置。這些方法将在下一節逐一讨論。
