1搜尋算法研究與實踐
1.1背景
淘寶的搜尋引擎涉及對上億商品的毫秒級處理響應,而淘寶的使用者不僅數量巨大,其行為特點以及對商品的偏好也具有豐富性和多樣性。是以,要讓搜尋引擎對不同特點的使用者作出針對性的排序,并以此帶動搜尋引導的成交提升,是一個極具挑戰性的問題。傳統的learning to rank(ltr)方法主要是在商品次元進行學習,根據商品的點選、成交資料構造學習樣本,回歸出排序權重。ltr學習的是目前線上已經展示出來商品排序的現象,對已出現的結果集合最好的排序效果,受到了本身排序政策的影響,我們有大量的樣本是不可見的,是以ltr模型從某種意義上說是解釋了過去現象,并不一定真正全局最優的。針對這個問題,有兩類的方法,其中一類嘗試在離線訓練中解決online和offline不一緻的問題,衍生出counterfactural machine learning的領域。另外一類就是線上trial-and-error進行學習,如bandit learning和reinforcement learning。
在之前我們嘗試了用多臂老虎機模型(multi-armed bandit,mab)來根據使用者回報學習排序政策,結合exploration與exploitation,收到了較好的效果。
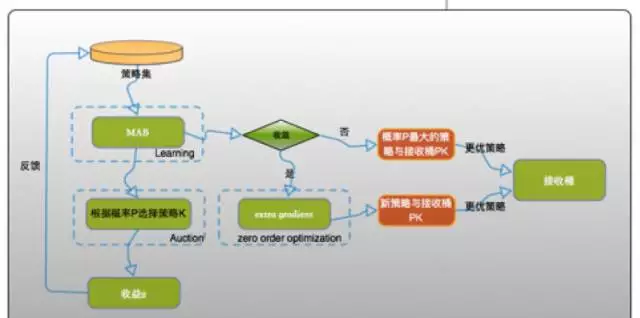
後來更進一步,在原來的基礎上引入狀态的概念,用馬爾可夫決策過程對商品搜尋排序問題進行模組化,并嘗試用深度強化學習的方法來對搜尋引擎的排序政策進行實時調控。
實際上,如果把搜尋引擎看作智能體(agent)、把使用者看做環境(environment),則商品的搜尋問題可以被視為典型的順序決策問題。agent每一次排序政策的選擇可以看成一次試錯(trial-and-error),把使用者的回報,點選成交等作為從環境獲得的獎賞。在這種反複不斷地試錯過程中,agent将逐漸學習到最優的排序政策,最大化累計獎賞。而這種在與環境互動的過程中進行試錯的學習,正是強化學習(reinforcement learning,rl)的根本思想。
本文接下來的内容将對具體的方案進行詳細介紹。
1.2 問題模組化
馬爾可夫決策過程(markov decision process,mdp)是強化學習的最基本理論模型。一般地,mdp可以由一個四元組表示:(1)s為狀态空間(state space);(2)a為動作空間(action space);(3)為獎賞函數;(4)為環境狀态轉移函數(state transition function)
我們的最終目标是用強化學習進行商品搜尋排序政策的學習,在實作的過程中,我們一步一步完成了從簡單問題到複雜問題的過渡,包括:
基于值表(tabular)強化學習方法的商品價格檔t變換控制(離散狀态、離散動作問題);
基于值表(tabular)強化學習方法的商品展示比例控制(離散狀态、離散動作問題);
基于強化學習值函數估計(value function approximation)的商品排序政策調控(連續狀态、離散動作問題);
基于強化學習政策估計(policy approximation)的商品排序政策調控(連續狀态、連續動作問題)。
1.2.1狀态定義
假設使用者在搜尋的過程中傾向于點選他感興趣的商品,并且較少點選他不感興趣的商品。基于這個假設,我們将使用者的曆史點選行為作為抽取狀态特征的資料來源。具體地,在每一個pv請求發生時,我們把使用者在最近一段時間内點選的商品的特征作為目前agent感覺到的狀态。當然,在不同的問題中,狀态的表示方法會有所不同。例如,在值表強化學習方法中,狀态為可枚舉的離散變量;在值函數估計和政策估計方法中,狀态則表示為特征向量。

1.2.2 獎賞函數定義
agent給出商品排序,使用者根據排序的結果進行的浏覽、商品點選或購買等行為都可以看成對agent的排序政策的直接回報。在第四章中,我們将利用獎賞塑形(reward shaping)方法對獎賞函數的表達進行豐富,提高不同排序政策在回報信号上的區分度。
1.3算法設計
由于篇幅有限,我們僅對強化學習在搜尋中的使用給出2個執行個體。
1. tabular方法
我們在排序中要引入價格的因素來影響最終展示的價格,若以gmv為目标,則簡單可以表示為cvr*price,同時我們又想控制價格的作用程度,是以目标稍作修改:,加入一個變量t來控制價格的影響。這個t值的範圍很有限,可以用mab或cmab來找到最優解。
我們用強化學習的視角來對這個問題進行抽象,把使用者前2次點選的商品價格檔位(0~7,從低到高)作為狀态。這個狀态表示的是使用者之前點選商品的價格偏好,如果兩次都點選1檔商品,說明使用者偏好低價商品,很有可能接下來使用者隻對低價商品感興趣,如果這個狀态轉移分布是穩定的(stationary),那麼一個統計模型可以就可以描述這種規律。而實際上,使用者的行為是受我們排序模型的影響的,使用者點選1檔商品也可能是因為目前的排序政策隻給使用者展示了1檔商品,并不一定是使用者的本質需求。在接下來使用者的搜尋過程中,我們可以有的選擇1是隻出1檔商品讓使用者的需求快速收斂,選擇2是投放一些附近檔位的商品供使用者選擇,如果使用者選擇了其他檔位的商品,進行了狀态的轉移,就可能找到一個更好的路徑,最終的收益和我們所有的過程中的投放政策都相關。從每個時間點上看,政策可能不是最優的,但全局上可能是最優的。
具體地,當使用者進行了搜尋後,根據使用者的狀态s,和q表(下圖)進行一個epsilon-greedy的投放,選擇一個動作a(上文中的價格指數t),執行這個a的排序結果展示給使用者,并記錄下這次的狀态s與動作a,以及使用者對這次搜尋結果的回報r,從使用者的點選與否的回報,再對q表進行更新。
根據q-learning公式進行權重更新。
接下來,由于使用者點選了某商品,他的狀态發生了轉移,就找到對應的狀态繼續進行epsilon-greedy的投放。再繼續進行學習,直到收斂。
2. ddpg方法
例如一個線性排序模型,
x是m維的特征向量,我們學習每個使用者狀态的最優參數w,即
這種假設需要使用政策估計的方法。政策估計(policy approximation)方法是解決連續狀态/動作空間問題的有效方法之一。其主要思想是用參數化的函數對政策進行表達,通過優化參數來完成政策的學習。通常,這種參數化的政策函數被稱為actor。假設我們一共調控()個次元的排序權重,對于任意狀态,actor對應的輸出為
其中,為actor的參數,對于任意(),是關于狀态的一個函數,代表第維的排序權重分,其形式可根據實際情況而定,我們的方案采用深度神經網絡作為actor函數。這種方式在不同的狀态之間可以通過神經網絡來共享一些參數權重。
強化學習的目标是最大化任意狀态上的長期累積獎賞,根據政策梯度定理, actor函數的參數的更新公式可以寫為
其中,為actor神經網絡在狀态上關于的梯度,為狀态動作對(state-action pair)的長期累積獎賞。因為和都是連續的數值,我們采用深度神經網絡作為估計器對進行學習,具體的學習算法可參考深度q學習算法dqn [1]。
1.4 獎賞塑型
我們最初采用的獎賞函數僅基于使用者在每一個pv中的點選、成交行為回報來建構。然而,在淘寶主搜這種大規模應用的場景中,我們較難在短時間内觀察到不同的排序政策在點選和成交這樣的宏觀名額上的差别。是以,長期累積獎賞關于不同學習參數的梯度并無明顯差別,導緻學習算法收斂緩慢。是以,我們有必要在獎賞函數中引入更多的資訊,增大不同動作的區分度。
在進行強化學習方案的同時,我們用pointwise ltr進行了一些對比實驗,發現pointwise ltr這種直接在商品特征上進行學習的方式在求取政策梯度的時候,能夠将不同排序政策更為顯著地區分開。參照這個思路,我們将商品的一些屬性特征加入到獎賞函數的定義中,通過獎賞塑形(reward shaping)的方法[2, 3]豐富其包含的資訊量。
獎賞塑形的思想是在原有的獎賞函數中引入一些先驗的知識,加速強化學習算法的收斂。簡單地,我們可以将“在狀态上選擇動作,并轉移到狀态”的獎賞值定義為
其中,為原始定義的獎賞函數,為包含先驗知識的函數,也被稱為勢函數(potential function)。我們可以把勢函數了解學習過程中的子目标(local objective)。根據上面的讨論,我們把每個狀态對應pv的商品資訊納入reward的定義中,将勢函數定義為
其中,為狀态對應pv中商品的個數,表示的第個商品,為agent在狀态執行的動作,表示排序政策為時商品的點選(或成交)的似然(likelihood)。是以,也就表示在狀态上執行動作時,pv中所有商品能夠被點選(或購買)的似然機率之和。
1.5 實驗效果
在雙11期間,我們在無線搜尋排序的21和22号桶對強化學習方案進行了測試。下圖展示了我們的算法在學習的過程中的誤差(rneu)變化情況,截取的時間範圍為11月10日18:00到11月11日8:00。
可以看到,從11月10日18:00啟動開始,每個桶上的rneu開始逐漸下降。到當天20:00之後,下降趨勢變得比較緩和,說明學習算法在逐漸往最優政策進行逼近。但過了11月11日0點之後,每個桶對應的rneu名額都出現了陡然上升的情況,這是因為0點前後使用者的行為發生了急劇變化,導緻線上資料分布在0點以後與0點之前産生較大差别。相應地,學習算法擷取到新的reward信号之後,也會做出适應性地調整。
2 推薦算法研究與實踐
2.1背景介紹
雙11主會場是一個很複雜的推薦場景。從推薦的業務形式上看,雙11主會場分為三層:分别是樓層、坑位以及具體素材圖的推薦。2016年的雙11主會場在整體的組織形式上與去年的雙11主會場類似,但具體業務的構成及組織有較大的不同。
首先,可推薦的樓層多于十層,我們需從中挑選數層進行展示,并有可能根據時間段和業務的需求進行調整。是以,展現形式的多變對模型的日志特征學習造成了一定的幹擾。其次,坑位的構成分為三種會場入口:第一行是行業會場,第二行對應店鋪會場,第三行對應是标簽會場。最後,在樓層以及坑位都确定之後,我們需要每個的坑位入口上選擇具體的素材。2016年雙11主會場的素材有兩種不同的展現形式,分别是雙素材圖以及單素材圖。雙素材圖模式能提升使用者的點選欲望,增強視覺感官沖擊力,但也會對使用者的真實點選行為資料造成一定程度的幹擾或噪聲,甚至對排序的模型産生比較大的偏置。
由于2016年雙11首圖寶貝素材總量在百萬張且坑位數上百,我們會根據樓層的次序對參與打分的候選集進行配額,根據樓層的實時點選率配置設定樓層的打分量。在各類業務以及填坑邏輯及調控流量的限制下,推薦結果并不一定能按照原有的打分高低進行展示。是以,我們需要考慮打分寶貝數與工程實作上的平衡關系。由于主會場的qps高達數萬,一味地增大打分量是不可取的。為了解決這一問題,我們在初選的match召回方式上做了大量的努力,如提升使用者的多重興趣覆寫、增大有效的候選寶貝。
根據在2015雙11的一些經驗并結合2016年雙11前期的系統壓測情況,在2016年雙11主會場我們采用了素材模型驅動的模式。從個性化推薦算法的角度來說,我們在2016年雙11主會場嘗試了多種新穎的排序模型,并做了嚴格的效果對比。具體的排序模型涉及lr、ftrl、gbdt+ftrl融合模型以及wide&deep模型,同時為了克服data drift的波動在日常的首圖場景還嘗試了adaptive-online-learning的算法,以及嘗試了強化學習的思路。在後面的章節,會從算法層面逐一闡釋。
2.2算法模型
2.2.1 gbdt+ftrl模型
采用非線性模型學習intermediate feature,作為id feature和cross feature的補充,最終輸入到線性model來做ctr預估,最早是由facebook提出的,思路大緻如下:采用raw features(一般是統計類特征)訓練出gbdt模型,獲得的所有樹的所有葉子節點就是它能夠generate出來的特征空間,當每個樣本點經過gbdt模型的每一個樹時,會落到一個葉子節點,即産生了一個中間特征,所有這些中間特征會配合其他id類特征以及人肉交叉的特征一起輸入到lr模型來做ctr預估。顯然,gbdt模型很擅長發掘有區分度的特征,而從根到葉子節點的每一條路徑展現了特征組合。對比手工的離散化和特征交叉,模型顯然更擅長挖掘出複雜模式,獲得更好的效果。我們通過gbdt來做特征挖掘,并最終與ftrl模型融合的方案如下圖:
輸入到gbdt的特征非常關鍵,這些特征決定了最終産出的中間特征是否有效。我們有一套靈活的特征生成流程,可以友善做各種次元的特征提取以及交叉統計。gbdt+ftrl中主要用到的特征包含兩部分:第一部分是使用者/寶貝id與對方泛化次元交叉統計的特征,包含各種基礎行為的次數以及ctr等。
第二部分是來自于match階段的一些連續類特征。推薦的match階段負責粗選出一部分跟使用者相關的content,該過程中會有多個模型分出現,例如做trigger selection的model分, content的最終match score等,這些分數來自于不同離線model,最終作為feature在online rank model中,能獲得非常好的ensemble效果。
2.2.2 wide & deep learning模型
借鑒google今年在深度學習領域的論文《wide & deep learning for recommender systems》中所提到的wide & deep learning架構(以下簡稱為wdl),并将其結合基于搜尋事業部自研的機器學習平台的線上學習技術,我們研發了一套适用于推薦業務的wdl模型算法。下文将會對這一技術進行詳述。
wdl模型的原理架構如上圖所示:它将深度神經網絡(dnn)網絡和邏輯回歸(logistic regression)模型并置在同一個網絡中,并且将離散型特征(categorical feature)和連續型特征(continuous feature)有機地結合在一起。wdl模型主要由wide側和deep側組成。wide側通過特征交叉來學習特征間的共現,而deep側通過将具有泛化能力的離散型特征進行特征嵌入(embedding),和連續型特征一起作為深度神經網絡的輸入(可以認為是一種特殊的深度神經網絡,在網絡的最後一層加入了大量的0/1節點),從理論上來說,我們可以把deep側看作傳統矩陣分解(matrix factorization)的一種泛化實作,值得注意的是特征嵌入的函數是和網絡中其他參數通過梯度反向傳播共同學習得到。模型的預測值采用如下公式進行計算:
其中,wide側和deep側合并在一起計算後驗機率p(y=1|x);在誤差反向傳播(backpropagation)的計算過程中時,我們對兩個方向同時進行計算。
2.2.3 adaptive-online-learning(自适應線上學習)
傳統的線上學習模型沒有一種機制很好的判斷模型應該采用的多長時間的日志進行訓練,目前業界的線上學習模型也都是通過經驗值的方式來進行資料截斷,自适應學習(adaptive learning)的最大優勢就在于能夠通過自我學習的方法适應業務的多變性。其實作原理在于保留下來每一個時刻開始到現在的資料學習到的模型,然後根據有效的評測名額,計算出各個模型的權重資訊,并同時捕捉到資料分布快速變化波動的情況下的使用者實時興趣的細微差别,進而融合出一個最優的模型結果。
2.2.4 reinforcement learning(強化學習)
相比對每個推薦場景單獨進行個性化推薦的政策,基于強化學習架構(reinforcement learning)的推薦系統根據全鍊路的資料進行整合,同時響應多個異構場景的推薦請求。下圖中我們對手機淘寶(天貓)用戶端的資料/流量通路進行抽象:每個圓圈代表一個獨立的手淘場景,e代表使用者在該場景随時離開,箭頭代表流量可能地流動方向。
基于以上的資料通路圖,我們可以很自然地将全鍊路多場景的推薦任務了解為一個連續的決策問題:作為一個智能決策者(agent),推薦系統需要持續不斷地決定應該為使用者推薦怎樣的内容(比如,商品、店鋪、品牌以及活動)。強化學習正是一種對智能決策者進行模組化的最佳方式:通過對智能決策者短期狀态的變化進行遞歸式模組化,最終引導其漸進式地優化長期目标。
手淘上的推薦場景相當豐富,最具代表性的是一個頁面以清單的形式同時推薦多個商品的場景。為了便于讀者了解,我們首先介紹單個商品的推薦場景,之後再過渡到多商品的推薦場景。在單商品的推薦場景,a對應的是單個商品。我們的目标是學習在狀态s下采取動作a所能獲得的累積獎勵(的期望值)。我們用q(s,a)來表示這一期望值。在這種情況下,我們隻需要選擇一種函數映射關系(如線性函數或神經網絡)将s和a所代表的向量映射到标量上對目标函數q(s,a)進行拟合。
我們把這一定義延伸到典型的多商品推薦場景。由于文章長度有限,我們下面介紹一種最簡單的思路,即假設使用者是否會點選單商品的決策是獨立的。也就是說,假設使用者如果喜歡商品a,使用者不會因為在同一推薦清單中見到了他更喜歡的商品b而放棄點選商品a。在這一假設下,我們對展示每個商品所獲得的累積獎勵的計算也是獨立的。通過一系列的推導,我們可以得到一個對狀态s下商品i能得到的分數f(s,i)的遞歸定義。
通過等式(7),我們可以疊代計算對無偏估計值進行求解。實際情況中使用者必然會因為推薦商品的組合問題産生更複雜的行為,這樣一來必然導緻累積獎勵獨立計算的假設不成立。但以此為本,我們可以推導出基于更複雜假設下的計算累積獎勵估計量的遞歸公式。
<a href="https://mp.weixin.qq.com/s/0l5agkqlfhd-pnjx96werw">原文連結</a>