本節書摘來自華章社群《spark核心技術與進階應用》一書中的第1章,第1.1節什麼是spark,作者于俊 向海 代其鋒 馬海平,更多章節内容可以通路雲栖社群“華章社群”公衆号檢視
1.1 什麼是spark
說起大資料,很多人會想起doug cutting以自己兒子玩具小象命名的開源項目hadoop。hadoop解決了大多數批處理工作負載問題,成為了大資料時代企業的首選技術。但随着大資料時代不可逆的演進,人們發現,由于一些限制,hadoop對一些工作負載并不是最優選擇,比如:
缺少對疊代的支援;
中間資料需輸出到硬碟存儲,産生了較高的延遲。
探其究竟,mapreduce設計上的限制比較适合處理離線資料,在實時查詢和疊代計算上存在較大的不足,而随着具體業務的發展,業界對實時查詢和疊代計算有更多的需求。
2009年,美國加州大學伯克利分校實驗室小夥伴們基于amplab的叢集計算平台,立足記憶體計算,從多疊代批量處理出發,兼顧資料倉庫、流處理、機器學習和圖計算等多種計算範式,正式将spark作為研究項目,并于2010年進行了開源。
什麼是spark?spark作為apache頂級的開源項目,是一個快速、通用的大規模資料處理引擎,和hadoop的mapreduce計算架構類似,但是相對于mapreduce,spark憑借其可伸縮、基于記憶體計算等特點,以及可以直接讀寫hadoop上任何格式資料的優勢,進行批處理時更加高效,并有更低的延遲。相對于“one stack to rule them all”的目标,實際上,spark已經成為輕量級大資料快速處理的統一平台,各種不同的應用,如實時流處理、機器學習、互動式查詢等,都可以通過spark建立在不同的存儲和運作系統上,下面我們來具體認識一下spark。
1.1.1 概述
随着網際網路的高速發展,以大資料為核心的計算架構不斷出現,從支援離線的mapreduce席卷全球,到支援線上處理的storm異軍突起,支援疊代計算的spark攻城拔寨,支援高性能資料挖掘的mpi深耕細作。各種架構誕生于不同的實驗室或者公司,各有所長,各自解決了某一類問題,而在一些網際網路公司中,百家争鳴,各種架構同時被使用,比如作者所在公司的大資料團隊,模型訓練和資料處理采用mapreduce架構(包括基于hive建構的資料倉庫查詢的底層實作),實時性要求較高的線上業務采取storm,日志處理以及個性化推薦采取spark,這些架構都部署在統一的資料平台上,共享叢集存儲資源和計算資源,形成統一的輕量級彈性計算平台。
1.1.2 spark大資料處理架構
相較于國内外較多的大資料處理架構,spark以其低延時的出色表現,正在成為繼hadoop的mapreduce之後,新的、最具影響的大資料架構之一,圖1-1所示為以spark為核心的整個生态圈,最底層為分布式存儲系統hdfs、amazon s3、hypertable,或者其他格式的存儲系統(如hbase);資源管理采用mesos、yarn等叢集資源管理模式,或者spark自帶的獨立運作模式,以及本地運作模式。在spark大資料處理架構中,spark為上層多種應用提供服務。例如,spark sql提供sql查詢服務,性能比hive快3~50倍;mllib提供機器學習服務;graphx提供圖計算服務;spark streaming将流式計算分解成一系列短小的批處理計算,并且提供高可靠和吞吐量服務。值得說明的是,無論是spark sql、spark streaming、graphx還是mllib,都可以使用spark核心api處理問題,它們的方法幾乎是通用的,處理的資料也可以共享,不僅減少了學習成本,而且其資料無縫內建大大提高了靈活性。
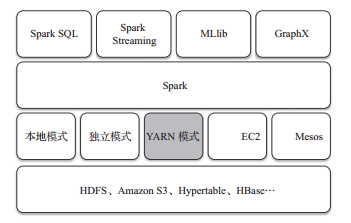
基于hadoop的資料總管yarn實際上是一個彈性計算平台,作為統一的計算資源管理架構,不僅僅服務于mapreduce計算架構,而且已經實作了多種計算架構進行統一管理。這種共享叢集資源的模式帶來了很多好處。
資源使用率高。多種架構共享資源的模式有效解決了由于應用程式數量的不均衡性導緻的高峰時段任務比較擁擠,空閑時段任務比較空閑的問題;同時均衡了記憶體和cpu等資源的利用。
實作了資料共享。随着資料量的增加,資料移動成本越來越高,網絡帶寬、磁盤空間、磁盤io都會成為瓶頸,在分散資料的情況下,會造成任務執行的成本提高,獲得結果的周期變長,而資料共享模式可以讓多種架構共享資料和硬體資源,大幅度減少資料分散帶來的成本。
有效降低運維和管理成本。相比較一種計算架構需要一批維護人員,而運維人員較多又會帶來的管理成本的上升;共享模式隻需要少數的運維人員和管理人員即可完成多個架構的統一運維管理,便于運維優化和運維管理政策統一執行。
總之,spark憑借其良好的伸縮性、快速的線上處理速度、具有hadoop基因等一系列優勢,迅速成為大資料處理領域的佼佼者。apache spark已經成為整合以下大資料應用的标準平台:
互動式查詢,包括sql;
實時流處理;
複雜的分析,包括機器學習、圖計算;
批處理。
1.1.3 spark的特點
作為新一代輕量級大資料快速處理平台,spark具有以下特點:
快速。spark有先進的dag執行引擎,支援循環資料流和記憶體計算;spark程式在記憶體中的運作速度是hadoop mapreduce運作速度的100倍,在磁盤上的運作速度是hadoop mapreduce運作速度的10倍,如圖1-2所示。
易用。spark支援使用java、scala、python語言快速編寫應用,提供超過80個進階運算符,使得編寫并行應用程式變得容易。
通用。spark可以與sql、streaming以及複雜的分析良好結合。基于spark,有一系列進階工具,包括spark sql、mllib(機器學習庫)、graphx和spark streaming,支援在一個應用中同時使用這些架構,如圖1-3所示。

spark可以指定hadoop,yarn的版本來編譯出合适的發行版本,spark也能夠很容易地運作在ec2、mesos上,或以standalone模式運作,并從hdfs、hbase、cassandra和其他hadoop資料源讀取資料。
1.1.4 spark應用場景
spark使用了記憶體分布式資料集,除了能夠提供互動式查詢外,還優化了疊代工作負載,在spark sql、spark streaming、mllib、graphx都有自己的子項目。在網際網路領域,spark在快速查詢、實時日志采集處理、業務推薦、定制廣告、使用者圖計算等方面都有相應的應用。國内的一些大公司,比如阿裡巴巴、騰訊、intel、網易、科大訊飛、百分點科技等都有實際業務運作在spark平台上。下面簡要說明spark在各個領域中的用途。
快速查詢系統,基于日志資料的快速查詢系統業務建構于spark之上,利用其快速查詢以及記憶體表等優勢,能夠承擔大部分日志資料的即時查詢工作;在性能方面,普遍比hive快2~10倍,如果使用記憶體表的功能,性能将會比hive快百倍。
實時日志采集處理,通過spark streaming實時進行業務日志采集,快速疊代處理,并進行綜合分析,能夠滿足線上系統分析要求。
業務推薦系統,使用spark将業務推薦系統的小時和天級别的模型訓練轉變為分鐘級别的模型訓練,有效優化相關排名、個性化推薦以及熱點點選分析等。
定制廣告系統,在定制廣告業務方面需要大資料做應用分析、效果分析、定向優化等,借助spark快速疊代的優勢,實作了在“資料實時采集、算法實時訓練、系統實時預測”的全流程實時并行高維算法,支援上億的請求量處理;模拟廣告投放計算效率高、延遲小,同mapreduce相比延遲至少降低一個數量級。
使用者圖計算。利用graphx解決了許多生産問題,包括以下計算場景:基于度分布的中樞節點發現、基于最大連通圖的社群發現、基于三角形計數的關系衡量、基于随機遊走的使用者屬性傳播等。