本節書摘來自華章出版社《算法基礎:打開算法之門》一書中的第3章,第3.6節,作者 [美]托馬斯 h 科爾曼(thomas h cormen),更多章節内容可以通路雲栖社群“華章計算機”公衆号檢視
在本章和上一章中,我們已經看到了關于查找的4個算法和關于排序的4個算法。我們将它們的特性總結在以下兩個表中。因為第2章的3個查找算法僅僅是關于同一個題目的變形,我們将betterlinearsearch或sentinellinearsearch作為線性查找的代表均可。
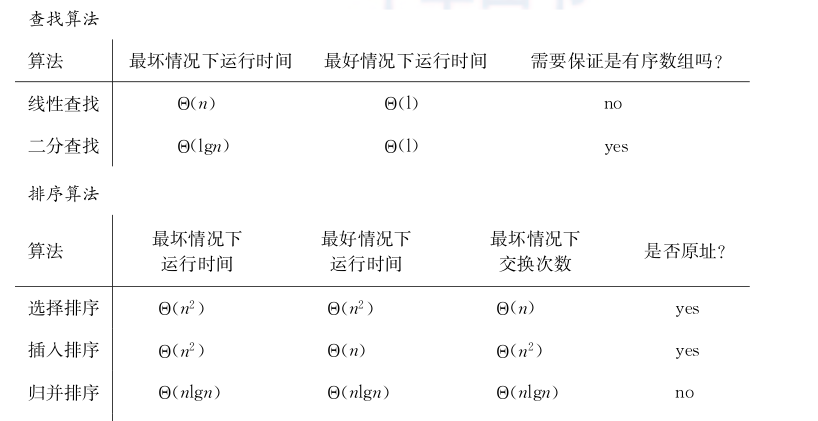
這兩個表中沒有顯示平均情況下的運作時間,因為除了典型的快速排序外,其他算法的平均情況下的運作時間均與最壞情況下的運作時間一緻。我們已經學習了,當數組元素按順序随機産生時,快速排序平均情況下的運作時間僅僅是Θ(nlgn)。這些排序算法在實際中進行對比的結果如何呢?我用c++将這些算法編寫為程式,并且采取每4位元組為一整數的數組存儲,分别在兩個不同的機器上運作了程式:一個機器是我的macbook pro(在這個機器上,我寫了這本書),處理器為24 ghz intel core 2 duo,記憶體為4 gb,系統為mac os 1068;另一個機器是一個dell筆記本電腦(我的網絡伺服器),處理器為32 ghz intel pentium 4,記憶體為1 gb,系統為linux version 262214。我使用g++和optimization level-o3來編譯代碼。我在規模可達到50000的數組上運作算法,且每個數組初始時均為逆序。針對每個規模的數組,我對每個算法運作20次,并計算出平均運作時間。
通過初始時将每個數組設為逆序,我抽取了插入排序和快速排序在最壞情況下的近似運作時間。是以,我運作了兩個版本的快速排序:“普通”快速排序,它總是将子數組a[p…r]的最後一個元素a[r]被劃分得到的位置元素作為主元,而随機快速排序總是在劃分之前,将a[p…r]中随機選擇的元素和a[r]進行調換。(此時我沒有運作取3個數的中位數作為主元的方法。)“普通”快速排序這一版本因為沒有采取随機化也被稱為确定的快速排序。它所執行的一系列操作在給定待排序的輸入數組時均已經是預先确定的。
當滿足n≥64時,在這兩個計算機上,随機快速排序均是冠軍。以下是針對不同輸入規模,其他算法相對于随機快速排序算法的運作時間的比率。

随機快速排序算法看起來很好,但是我們能夠超越它。回憶一下,當所有數組中的元素均不需移動太遠距離時,插入排序的運作效果很好。58一旦遞歸算法中子問題的規模降低到某個大小k時,每個元素的移動距離均不會超過k-1。是以當子問題規模變小時,我們并不需繼續遞歸調用随機快速排序,反之可适當地更改排序子數組的算法而非運作整個數組的算法,例如在子數組上,我們運作插入排序會發生什麼呢?确實,使用這樣一種雜交方法,我們能夠得到一個比随機快速排序更快速的排序算法。我發現在macbook pro上,子數組規模為22是最佳的交叉點,而在dell pc上,子數組規模為17時是最佳的交叉點。以下是針對同一問題規模,在兩個計算機上運作雜交算法相對于随機快速排序算法的運作時間的比率:
對于排序算法,是否有可能超越Θ(nlgn)的運作時間呢?這取決于具體情況。我們将在第4章看到如果隻可以通過比較元素來确定數組中元素的位置,且執行其他操作均需以排序比較的結果為基礎,那麼答案是不能,我們不可能超越Θ(nlgn)的運作時間。但是如果知道關于這些元素的一些特性,我們就可以得到更短的運作時間。