本節書摘來異步社群《python機器學習實踐指南》一書中的第1章,第1.1節,作者: 【美】alexander t. combs,更多章節内容可以通路雲栖社群“異步社群”公衆号檢視。
打造機器學習的應用程式,與标準的工程範例在許多方面都是類似的,不過有一個非常重要的方法有所不同:需要将資料作為原材料來處理。資料項目成功與否,很大程度上依賴于你所獲資料的品質,以及它是如何被處理的。由于資料的使用屬于資料科學的領域,了解資料科學的工作流程對于我們也有所幫助:整個過程要按照圖1-1中的順序,完成六個步驟:擷取,檢查和探索,清理和準備,模組化,評估和最後的部署。
在這個過程中,還經常需要繞回到之前的步驟,例如檢查和準備資料,或者是評估和模組化,但圖1-1所示的内容可以描述該過程較高層次的抽象。
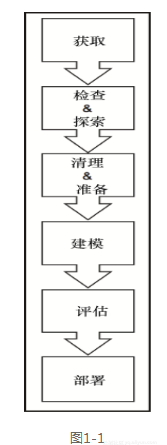
現在讓我們詳細讨論每一個步驟。
機器學習應用中的資料,可以來自不同的資料源,它可能是通過電子郵件發送的csv檔案,也可能是從伺服器中拉取出來的日志,或者它可能需要建構自己的web爬蟲。資料也可能存在不同的格式。在大多數情況下,它是基于文本的資料,但稍後将看到,建構處理圖像甚至視訊檔案的機器學習應用,也是很容易的。不管是什麼格式,一旦鎖定了某種資料,那麼了解該資料中有什麼以及沒有什麼,就變得非常重要了。
一旦獲得了資料,下一步就是檢查和探索它們。在這個階段中,主要的目标是合理地檢查資料,而實作這一點的最好辦法是發現不可能或幾乎不可能的事情。舉個例子,如果資料具有唯一的辨別符,檢查是否真的隻有一個;如果資料是基于價格的,檢查是否總為正數;無論資料是何種類型,檢查最極端的情況。它們是否有意義?一個良好的實踐是在資料上運作一些簡單的統計測試,并将資料可視化。此外,可能還有一些資料是缺失的或不完整的。在本階段注意到這些是很關鍵的,因為需要在稍後的清洗和準備階段中處理它。隻有進入模型的資料品質好了,模型的品質才能有保障,是以将這一步做對是非常關鍵的。
當所有的資料準備就緒,下一步是将它轉化為适合于模型使用的格式。這個階段包括若幹過程,例如過濾、聚集、輸入和轉化。所需的操作類型将很大程度上取決于資料的類型,以及所使用的庫和算法的類型。例如,對于基于自然語言的文本,其所需的轉換和時間序列資料所需的轉換是非常不同的。全書中,我們将會看到一些轉換的的例子。
一旦資料的準備完成後,下一階段就是模組化了。在這個階段中,我們将選擇适當的算法,并在資料上訓練出一個模型。在這個階段,有許多最佳實踐可以遵循,我們将詳細讨論它們,但是基本的步驟包括将資料分割為訓練、測試和驗證的集合。這種資料的分割可能看上去不合邏輯——尤其是在更多的資料通常會産生更好的模型這種情況下——但正如我們将看到的,這樣做可以讓我們獲得更好的回報,了解該模型在現實世界中會表現得如何,并避免模組化的大忌:過拟合。
一旦模型建構完成并開始進行預測,下一步是了解模型做得有多好。這是評估階段試圖回答的問題。有很多的方式來衡量模型的表現,同樣,這在很大程度上依賴于所用資料和模型的類型,不過就整體而言,我們試圖回答這樣的問題:模型的預測和實際值到底有多接近。有一堆聽上去令人混淆的名詞,例如根均方誤差、歐幾裡德距離,以及f1得分,但最終,它們還是實際值與預估值之間的距離量度。
一旦模型的表現令人滿意,那麼下一個步驟就是部署了。根據具體的使用情況,這個階段可能有不同的形式,但常見的場景包括将其作為另一個大型應用程式中的某個功能特性,一個定制的web應用程式,甚至隻是一個簡單的cron作業。
![筆試面試題目:滑動視窗(二)[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)