本節書摘來異步社群《mapreduce 2.0源碼分析與程式設計實戰》一書中的第1章,第1.4節,作者: 王曉華 責編: 陳冀康,更多章節内容可以通路雲栖社群“異步社群”公衆号檢視。
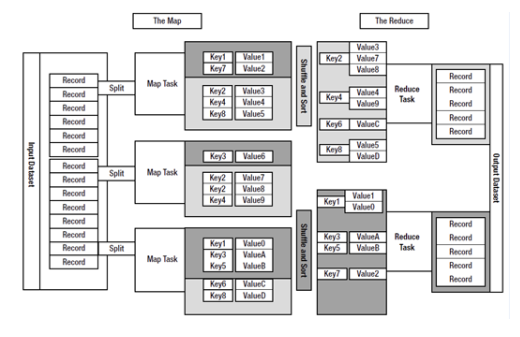
如果将hadoop比作一頭大象的話,那麼mapreduce就是那頭大象的大腦。mapreduce是hadoop核心程式設計模型。在hadoop中,資料處理核心為mapreduce程式設計模型。mapreduce把資料處理和分析分成兩個主要階段,即map階段和reduce階段。map階段主要是對輸入進行整合,通過定義的輸入格式擷取檔案資訊和類型,并且确定讀取方式,最終将讀取的内容以鍵值對的形式儲存。而reduce是用來對結果進行後續處理,通過對map擷取内容中的值進行二次處理和歸并排序進而計算出最終結果。mapreduce的處理過程,如圖1-1所示。
在mapreduce處理過程中,首先對資料進行分塊處理,之後将資料資訊交給map任務去進行讀取,對資料進行分類後寫入,根據不同的鍵産生相應的鍵值對資料。之後進入reduce階段,而reduce的任務是執行定義的reduce方法。具有相同鍵的值從多個資料表中被集合在一起進行分類處理,并将最終結果輸出到相應的磁盤空間中。
小提示: mapreduce是hadoop的核心處理程式,也是奇迹發生的地方。mapreduce是在hadoop簡單應用基礎上産生的一種簡潔并行計算模型,其在系統層面上滿足了存儲空間的擴充性、一緻性及容錯性等要求。程式設計人員編寫的自定義的mapreduce處理程式可以友善地在大規模內建資料庫上執行,進而可以做到對大規模資料的分析應用。
mapreduce使用和借鑒了函數方式程式設計語言的設計思想。其過程的實作是首先 通過指定一個map方法,将傳遞進來的資料通過鍵值對的形式進行映射,進而形成一個 新的鍵值對供後續處理。reduce作為一個限制方法,将具有相同鍵的值作為一個集合合并在一起。
mapreduce作為hadoop的核心處理程式,在誕生之初就為了處理大資料而采用了“分治式”的資料處理模式,将資料分散到各個節點中進行相應的處理。一般情況下,每個節點會就近讀取本地存儲的資料,進行相應的合并和排序後發送給reduce進行下一步處理。這個過程可以依據要求具體編寫,好處是避免了大資料處理架構所要求進行的大規模資料傳輸,進而節省了時間,提高了處理效率。
mapreduce程式是由java語言編寫的,而java語言本身的特點就是可移植性強。“一次編寫,到處運作”是java的特點。是以,mapreduce繼承了這個特點,具有很強的定制性。mapreduce的程式中會有很多的算法和設計模式,都是很直覺和固定的,不會因為所要處理對象和内容的不同具有太多的變化。同時,mapreduce作為通用的hadoop處理核心,需要面對的問題一定是千差萬别的。是以,mapreduce使用面向對象的程式設計模式抽出了這些資料内容的一些公共部分進行總結和程式設計。
和java語言本身又帶有極強的擴充性和應用性一樣,mapreduce也具有較好的程式擴充機制,能夠滿足程式設計人員定義各種各樣所需要的算法和程式。
mapreduce是hadoop的核心内容,也是這頭“大象”的大腦。mapreduce指揮着“大象”的前進方向和步伐,進而能夠對hadoop資料處理提供最大限度地支援。
![Ambari介紹和架構原理[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)