本節書摘來異步社群《hadoop實戰手冊》一書中的第1章,第1.2節,作者: 【美】jonathan r. owens , jon lentz , brian femiano 譯者: 傅傑 , 趙磊 , 盧學裕 責編: 楊海玲,更多章節内容可以通路雲栖社群“異步社群”公衆号檢視。
hdfs提供了許多shell指令來實作通路檔案系統的功能,這些指令都是建構在hdfs filesystem api之上的。hadoop自帶的shell腳本是通過指令行來執行所有操作的。這個腳本的名稱叫做hadoop,通常安裝在$hadoop_bin目錄下,其中$hadoop_bin是hadoopbin檔案完整的安裝目錄,同時有必要将$hadoop_bin配置到$path環境變量中,這樣所有的指令都可以通過hadoop fs -command這樣的形式來執行。
如果需要擷取檔案系統的所有指令,可以運作hadoop指令傳遞不帶參數的選項fs。
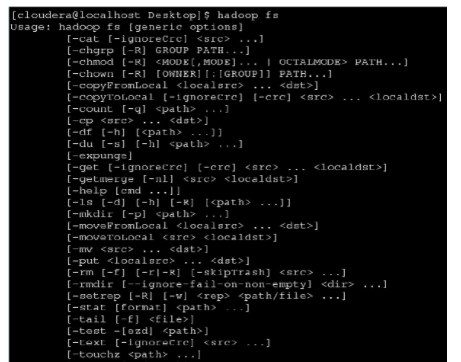
這些按照功能進行命名的指令的名稱與unix shell指令非常相似。使用help選項可以獲得某個具體指令的詳細說明。

在這一節中,我們将使用hadoop shell指令将資料導入hdfs中,以及将資料從hdfs中導出。這些指令更多地用于加載資料,下載下傳處理過的資料,管理檔案系統,以及預覽相關資料。掌握這些指令是高效使用hdfs的前提。
準備工作
操作步驟
完成以下步驟,實作将weblog_entries.txt檔案從本地檔案系統複制到hdfs上的一個指定檔案夾下。
1.在hdfs中建立一個新檔案夾,用于儲存weblog_entries.txt檔案:
2.将weblog_entries.txt檔案從本地檔案系統複制到hdfs剛建立的新檔案夾下:
3.列出hdfs上weblog_entries.txt檔案的資訊:
圖像說明文字在hadoop處理的一些結果資料可能會直接被外部系統使用,可能需要其他系統做更進一步的處理,或者mapreduce處理架構根本就不符合該場景,任何類似的情況下都需要從hdfs上導出資料。下載下傳資料最簡單的辦法就是使用hadoop shell。
4.将hdfs上的weblog_entries.txt檔案複制到本地系統的目前檔案夾下:
複制hdfs的檔案到本地檔案系統時,需要保證本地檔案系統的空間可用以及網絡連接配接的速度。hdfs中的檔案大小在幾個tb到幾十個tb是很常見的。在1gbit網絡環境下,從hdfs中導出10 tb資料到本地檔案系統,最好的情況下也要消耗23個小時,當然這還要保證本地檔案系統的空間是可用的。
下載下傳本書的示例代碼
工作原理
mkdir可以通過hadoop fs -mkdir path1 path2的形式來執行。例如,hadoop fs –mkdir /data/weblogs/12012012 /data/ weblogs/12022012将會在hdfs系統上分别建立兩個檔案夾/data/weblogs/12012012和/data/weblogs/12022012。如果檔案夾建立成功則傳回0,否則傳回-1。
copyfromlocal可以通過hadoop fs –copyfromlocal localfilepath uri的形式來執行,如果uri的位址(指的是hdfs://filesystemname:9000這個串)沒有明确給出,則預設會讀取core-site.xml中的fs.default.name這個屬性。上傳成功傳回0,否則傳回-1。
copytolocal指令可以通過hadoop fs –copytolocal [-ignorecrc] [-crc] urilocal_file_path的形式來執行。如果uri的位址沒有明确的給出,則預設會讀取core-site.xml中的fs.default.name這個屬性。copytolocal會執行crc(cyclic redundancy check)校驗保證已複制的資料的正确性,一個失敗的副本複制可以通過 參數–ignorecrc來強制執行,還可以通過-crc參數在複制檔案的同時也複制crc校驗檔案。
更多參考
put指令與copyfromlocal類似,put更通用一些,可以複制多個檔案到hdfs中,也能接受标準輸入流。
任何使用copytolocal的地方都可以用get替換,兩者的實作一模一樣。
在使用mapreduce處理大資料時,其輸出結果可能是一個或者多個檔案。最終輸出結果的檔案個數是由mapred.reduce.tasks的值決定的。我們可以在jobconf類中通過setnumreducetasks()方法來設定這個屬性,改變送出作業的reduce個數,每個reduce将對應輸出一個檔案。該參數是用戶端參數,非叢集參數,針對不同的作業應該設定不同的值。其預設值為1,意味着所有map(映射函數,以下都用map表示)的輸出結果都将複制到1個reducer上進行處理。除非map輸出的結果資料小于1 gb,否則預設的配置将不合适。reduce個數的設定更像是一門藝術而不是科學。在官方的文檔中對其設定推薦的兩個公式如下:
或者
假設你的叢集有10個節點來運作task tracker,每個節點最多可以啟動5個reduce槽位(通過設定tasktracker.reduce.tasks.maximum這個值來決定每個節點所能啟動的最大reduce槽位數)對應的這個公式應該是0.95×10×4=47.5。因為reduce個數的設定必須是整數,是以需要進行四舍五入。
0.95可以保證在map結束後可以立即啟動所有的reduce進行map結果的複制,隻需要一波就可以完成作業。1.75使得運作比較快的reducer能夠再執行第二波reduce,保證兩波reduce就能完成作業,使作業整體的負載均衡保持得比較好。
reduce輸出的資料存儲在hdfs中,可以通過檔案夾的名稱來引用。若檔案夾作為一個作業的輸入,那麼該檔案夾下的所有檔案都會被處理。上文介紹的get和copytolocal隻能對檔案進行複制,無法對整個檔案夾進行複制2。當然hadoop提供了getmerge指令,可以将檔案系統中的多個檔案合并成一個單獨的檔案下載下傳到本地檔案系統。
通過以下pig腳本來示範下getmerge指令的功能:
pig腳本可以通過下面的指令行來執行:
該腳本逐行讀取hdfs上的weblog_entries.txt檔案,并且按照md5的值進行分組。parallel是pig腳本用來設定reduce個數的方法。由于啟動了4個reduce任務,是以會在輸出的目錄/data/weblogs/weblogs_md5_groups.bcp中生成4個檔案。
注意,weblogs_md5_groups.bcp實際上是一個檔案夾,顯示該檔案夾的清單資訊可以看到:
在/data/weblogs/weblogs_md5_groups.bcp中包含4個檔案,即part-r-00000、part-r-00001、part-r-00002和part-r-00003。
getmerge指令可以用來将4個檔案合并成一個檔案,并且複制到本地的檔案系統中,具體指令如下:
操作完我們可以看到本地檔案清單如下:
延伸閱讀
u關于hdfs資料的讀寫,我們将在第2章中重點介紹如何直接利用檔案系統的api進行讀寫。
通過以下的兩個連結可以對比出檔案系統shell指令與java api的不同: