本節書摘來自華章出版社《antlr 4權威指南 》一書中的第2章,第2.4節,[美] 特恩斯·帕爾(terence parr) 著張 博 譯,更多章節内容可以通路雲栖社群“華章計算機”公衆号檢視。
為了編寫一個語言類應用程式,我們必須對每個輸入的詞組或者子詞組執行一些适當的操作。進行這項工作最簡單的方式是操作文法分析器自動生成的文法分析樹。這種方式的優點在于,我們能夠重回我們所熟悉的java領域。這樣,在語言類應用程式進一步的建構過程中,我們就不需要再學習複雜的antlr文法了。
首先,我們來認識一下antlr在識别和建立文法分析樹的過程中使用的資料結構和類名。熟悉這些資料結構将為我們未來的讨論奠定基礎。
前已述及,詞法分析器處理字元序列并将生成的詞法符号提供給文法分析器,文法分析器随即根據這些資訊來檢查文法的正确性并建造出一棵文法分析樹。這個過程對應的antlr類是charstream、lexer、token、parser,以及parsetree。連接配接詞法分析器和文法分析器的“管道”就是tokenstream。圖2-2展示了這些類型的對象在記憶體中的互動方式。
antlr盡可能多地使用共享資料結構來節約記憶體。如圖2-2所示,文法分析樹中的葉子節點(詞法符号)僅僅是盛放詞法符号流中的詞法符号的容器。每個詞法符号都記錄了自己在字元序列中的開始位置和結束位置,而非儲存子字元串的拷貝。其中,不存在空白字元對應的詞法符号(索引為2和4的字元)的原因是,我們假定我們的詞法分析器會丢棄空白字元。
圖2-2中也顯示出,parsetree的子類rulenode和terminalnode,二者分别是子樹的根節點和葉子節點。rulenode有一些令人熟悉的方法,例如getchild()和getparent(),但是,對于一個特定的文法,rulenode并不是确定不變的。為了更好地支援對特定節點的元素的通路,antlr會為每條規則生成一個rulenode的子類。如圖2-3所示,在我們的指派語句的例子中,子樹根節點的類型實際上是statcontext、assigncontext以及exprcontext。
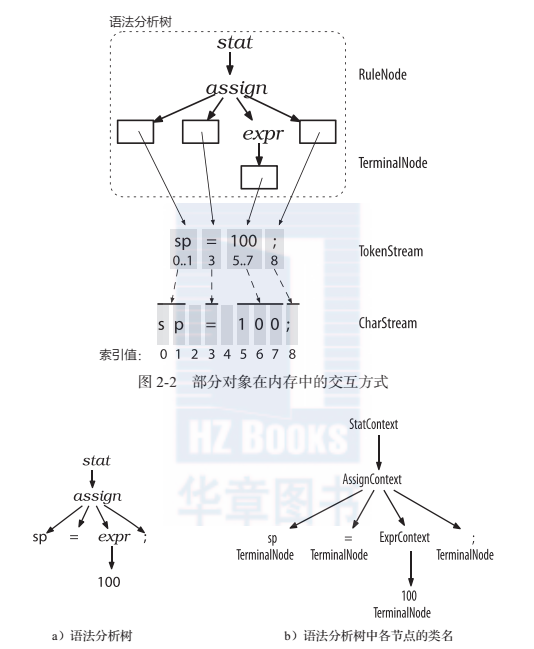
因為這些根節點包含了使用規則識别詞組過程中的全部資訊,它們被稱為上下文(context)對象。每個上下文對象都知道自己識别出的詞組中,開始和結束位置處的詞法符号,同時提供通路該詞組全部元素的途徑。例如,assigncontext類提供了方法id()和方法expr()來通路辨別符節點和代表表達式的子樹。
給定這些類型的具體實作,我們可以手工寫出對文法分析樹進行深度優先周遊的代碼。這樣,在通路其中的節點時,我們可以進行一切所需的操作。這個過程中的典型操作是諸如計算結果、更新資料結構或者産生輸出一類的事情。實際上,我們可以利用antlr自動生成并周遊樹的機制,而不需要每次都重複編寫周遊樹的代碼。
![seq2seq模型 + Attention機制[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)