本節書摘來自華章出版社《深入淺出dpdk》一書中的第3章,第3.1節并行計算,作者朱河清,梁存銘,胡雪焜,曹水 等,更多章節内容可以通路雲栖社群“華章計算機”公衆号檢視。
第3章 并 行 計 算
處理器性能提升主要有兩個途徑,一個是提高ipc(每個時鐘周期内可以執行的指令條數),另一個是提高處理器主頻率。每一代微架構的調整可以伴随着對ipc的提高,進而提高處理器性能,隻是幅度有限。而提高處理器主頻率對于性能的提升作用是明顯而直接的。但一味地提高頻率很快會觸及頻率牆,因為處理器的功耗正比于主頻的三次方。
是以,最終要取得性能提升的進一步突破,還是要回到提高ipc這個因素。經過處理器廠商的不懈努力,我們發現可以通過提高指令執行的并行度來提高ipc。而提高并行度主要有兩種方法,一種是提高微架構的指令并行度,另一種是采用多核并發。這一章主要就分享這兩種方法在dpdk中的實踐,并在指令并行方法中上進一步引入資料并發的介紹。
3.1 多核性能和可擴充性
3.1.1 追求性能水準擴充
多核處理器是指在一個處理器中內建兩個或者多個完整的核心(及計算引擎)。如果把處理器性能随着頻率的提升看做是垂直擴充,那多核處理器的出現使性能水準擴充成為可能。原本在單核上順序執行的任務,得以按邏輯劃分成若幹子任務,分别在不同的核上并行執行。在任務粒度上,使指令執行的并行度得到提升。
那随着核數的增加,性能是否能持續提升呢?amdahl定律告訴我們,假設一個任務的工作量不變,多核并行計算理論時延加速上限取決于那些不能并行處理部分的比例。換句話說,多核并行計算下時延不能随着核數增加而趨于無限小。該定律明确告訴我們,利用多核處理器提升固定工作量性能的關鍵在于降低那些不得不串行部分占整個任務執行的比例。更多資訊可以參考[ref3-1]。
對于dpdk的主要應用領域——資料包處理,多數場景并不是完成一個固定工作量的任務,更主要關注機關時間内的吞吐量。gustafson定律對于在固定工作時間下的推導給予我們更多的指導意義。它指出,多核并行計算的吞吐率随核數增加而線性擴充,可并行處理部分占整個任務比重越高,則增長的斜率越大。帶着這個觀點來讀dpdk,很多實作的初衷就豁然開朗。資源局部化、避免跨核共享、減少臨界區碰撞、加快臨界區完成速率(後兩者涉及多核同步控制,将在下一章中介紹)等,都不同程度地降低了不可并行部分和并發幹擾部分的占比。
3.1.2 多核處理器
在資料包處理領域,多核架構的處理器已經廣泛應用。本節以英特爾的至強主流多核處理器為例,介紹dpdk中用到的一些概念,比如實體核、邏輯核、cpu node等。
下面結合圖形詳細介紹了單核、多核以及超線程的概念。
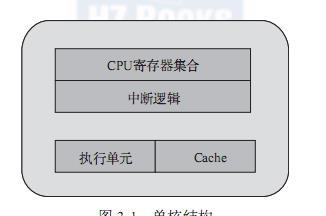
通過單核結構(見圖3-1),我們先認識一下cpu實體核中主要的基本元件。為簡化了解,将主要元件簡化為:cpu寄存器集合、中斷邏輯(local apic)、執行單元和cache。一個完整的實體核需要擁有這樣的整套資源,提供一個指令執行線程。
多處理器結構指的是多顆單獨封裝的cpu通過外部總線連接配接,構成的統一計算平台,如圖3-2所示。每個cpu都需要獨立的電路支援,有自己的cache,而它們之間的通信通過主機闆上的總線。在此架構上,若一個多線程的程式運作在不同cpu的某個核上,跨cpu的線程間協作都要走總線,而共享的資料還會付出因cache一緻性産生的開銷。從記憶體子系統的角度,多處理器結構進一步衍生出了非一緻記憶體通路(numa),這一點在第2章就有介紹。在dpdk中,對于多處理器的numa結構,使用socket node來标示,跨numa的記憶體通路是性能調優時最需要避免的。

如圖3-3所示,超線程(hyper-threading)在一個處理器中提供兩個邏輯執行線程,邏輯線程共享流水線、執行單元和緩存。該技術的本質是複用單處理器中的超标量流水線的多路執行單元,降低多路執行單元中因指令依賴造成的執行單元閑置。對于每個邏輯線程,擁有完整獨立的寄存器集合和本地中斷邏輯,從軟體的角度,與單線程實體核并沒有差異。例如,8核心的處理器使用超線程技術之後,可以得到16個邏輯線程。采用超線程,在單核上可以同時進行多線程處理,使整體性能得到一定程度提升。但由于其畢竟是共享執行單元的,對ipc(每周期執行指令數)越高的應用,帶來的幫助越有限。dpdk是一種i/o集中的負載,對于這類負載,ipc相對不是特别高,是以超線程技術會有一定程度的幫助。更多資訊可以參考[ref3-2]。
如果說超線程還是站在一個核内部以資源切分的方式構成多個執行線程,多核體系結構(見圖3-4)則是在一個cpu封裝裡放入了多個對等的實體核,每個實體核可以獨立構成一個執行線程,當然也可以進一步分割成多個執行線程(采用超線程技術)。多核之間的通信使用晶片内部總線來完成,共享更低一級緩存(llc,三級緩存)和記憶體。随着cpu制造技術的提升,每個cpu封裝中放入的實體核數也在不斷提高。
各種架構在總線占用、cache、寄存器以及執行單元的差別大緻可以歸納為表3-1。
一個實體封裝的cpu(通過physical id區分判斷)可以有多個核(通過core id區分判斷)。而每個核可以有多個邏輯cpu(通過processor區分判斷)。一個核通過多個邏輯cpu實作這個核自己的超線程技術。
檢視cpu核心資訊的基本指令如表3-2所示。
處理器核數:processor cores,即俗稱的“cpu核數”,也就是每個實體cpu中core的個數,例如“intel(r) xeon(r) cpu e5-2680 v2 @ 2.80ghz”是10核處理器,它在每個socket上有10個“處理器核”。具有相同core id的cpu是同一個core的超線程。
邏輯處理器核心數:sibling是核心認為的單個實體處理器所有的超線程個數,也就是一個實體封裝中的邏輯核的個數。如果sibling等于實際實體核數的話,就說明沒有啟動超線程;反之,則說明啟用超線程。
系統實體處理器封裝id:socket中文翻譯成“插槽”,也就是所謂的實體處理器封裝個數,即俗稱的“實體cpu數”,管理者可能會稱之為“路”。例如一塊“intel(r) xeon(r) cpu e5-2680 v2 @ 2.80ghz”有兩個“實體處理器封裝”。具有相同physical id的cpu是同一個cpu封裝的線程或核心。
系統邏輯處理器id:邏輯處理器數的英文名是logical processor,即俗稱的“邏輯cpu數”,邏輯核心處理器就是虛拟實體核心處理器的一個超線程技術,例如“intel(r) xeon(r) cpu e5-2680 v2 @ 2.80ghz”支援超線程,一個實體核心能模拟為兩個邏輯處理器,即一塊“intel(r) xeon(r) cpu e5-2680 v2 @ 2.80ghz”有20個“邏輯處理器”。
3.1.3 親和性
當處理器進入多核架構後,自然會面對一個問題,按照什麼政策将任務線程配置設定到各個處理器上執行。衆所周知的是,這個配置設定工作一般由作業系統完成。負載均衡當然是比較理想的政策,按需指定的方式也是很自然的訴求,因為其具有确定性。
簡單地說,cpu親和性(core affinity)就是一個特定的任務要在某個給定的cpu上盡量長時間地運作而不被遷移到其他處理器上的傾向性。這意味着線程可以不在處理器之間頻繁遷移。這種狀态正是我們所希望的,因為線程遷移的頻率小就意味着産生的負載小。
linux核心包含了一種機制,它讓開發人員可以程式設計實作cpu親和性。這意味着應用程式可以顯式地指定線程在哪個(或哪些)處理器上運作。
1.linux核心對親和性的支援
在linux核心中,所有的線程都有一個相關的資料結構,稱為task_struct。這個結構非常重要,原因有很多;其中與親和性相關度最高的是cpus_allowed位掩碼。這個位掩碼由n位組成,與系統中的n個邏輯處理器一一對應。具有4個實體cpu的系統可以有4位。如果這些cpu都啟用了超線程,那麼這個系統就有一個8位的位掩碼。
如果針對某個線程設定了指定的位,那麼這個線程就可以在相關的cpu上運作。是以,如果一個線程可以在任何cpu上運作,并且能夠根據需要在處理器之間進行遷移,那麼位掩碼就全是1。實際上,在linux中,這就是線程的預設狀态。
linux核心api提供了一些方法,讓使用者可以修改位掩碼或檢視目前的位掩碼:
sched_set_affinity()(用來修改位掩碼)
(sched_get_affinity(用來檢視目前的位掩碼)
注意,cpu_affinity會被傳遞給子線程,是以應該适當地調用sched_set_affinity。
2.為什麼應該使用親和性
将線程與cpu綁定,最直覺的好處就是提高了cpu cache的命中率,進而減少記憶體通路損耗,提高程式的速度。
在多核體系cpu上,提高外設以及程式工作效率最直覺的辦法就是讓各個實體核各自負責專門的事情。每個實體核各自也會有緩存,緩存着執行線程使用的資訊,而線程可能會被核心排程到其他實體核上,這樣l1/l2的cache命中率會降低,當綁定實體核後,程式就會一直在指定核上跑,不會由作業系統排程到其他核上,省卻了來回反複排程的性能消耗,線程之間互不幹擾地完成工作。
在numa架構下,這個操作對系統運作速度的提升有更大的意義,跨numa節點的任務切換,将導緻大量三級cache的丢失。從這個角度來看,numa使用cpu綁定時,每個核心可以更專注地處理一件事情,資源體系被充分使用,減少了同步的損耗。
通常linux核心都可以很好地對線程進行排程,在應該運作的地方運作線程(這就是說,在可用的處理器上運作并獲得很好的整體性能)。核心包含了一些用來檢測cpu之間任務負載遷移的算法,可以啟用線程遷移來降低繁忙的處理器的壓力。
一般情況下,在應用程式中隻需使用預設的排程器行為。然而,您可能會希望修改這些預設行為以實作性能的優化。讓我們來看一下使用親和性的三個原因。
有大量計算要做
基于大量計算的情形通常出現在科學計算和理論計算中,但是通用領域的計算也可能出現這種情況。一個常見的标志是發現自己的應用程式要在多處理器的機器上花費大量的計算時間。
測試複雜的應用程式
測試複雜軟體是我們對核心親和性技術感興趣的另外一個原因。考慮一個需要進行線性可伸縮性測試的應用程式。有些産品聲明可以在使用更多硬體時執行得更好。我們不用購買多台機器(為每種處理器配置都購買一台機器),而是可以:①購買一台多處理器的機器,②不斷增加配置設定的處理器,③測量每秒的事務數,④評估結果的可伸縮性。
如果應用程式随着cpu的增加可以線性地伸縮,那麼每秒事務數和cpu個數之間應該會是線性的關系。這樣模組化可以确定應用程式是否可以有效地使用底層硬體。
如果一個給定的線程遷移到其他地方去了,那麼它就失去了利用cpu緩存的優勢。實際上,如果正在使用的cpu需要為自己緩存一些特殊的資料,那麼所有其他cpu都會使這些資料在自己的緩存中失效。
是以,如果有多個線程都需要相同的資料,那麼将這些線程綁定到一個特定的cpu上是非常有意義的,這樣就確定它們可以通路相同的緩存資料(或者至少可以提高緩存的命中率)。
否則,這些線程可能會在不同的cpu上執行,這樣會頻繁地使其他緩存項失效。
運作時間敏感的、決定性的線程
我們對cpu親和性感興趣的最後一個原因是實時(對時間敏感的)線程。例如,您可能會希望使用親和性來指定一個8路主機上的某個處理器,而同時允許其他7個處理器處理所有普通的系統排程。這種做法確定長時間運作、對時間敏感的應用程式可以得到運作,同時可以允許其他應用程式獨占其餘的計算資源。下面的應用程式顯示了這是如何工作的。
3.線程獨占
dpdk通過把線程綁定到邏輯核的方法來避免跨核任務中的切換開銷,但對于綁定運作的目前邏輯核,仍然可能會有線程切換的發生,若希望進一步減少其他任務對于某個特定任務的影響,在親和的基礎上更進一步,可以采取把邏輯核從核心排程系統剝離的方法。
linux核心提供了啟動參數isolcpus。對于有4個cpu的伺服器,在啟動的時候加入啟動參數isolcpus=2,3。那麼系統啟動後将不使用cpu3和cpu4。注意,這裡說的不使用不是絕對地不使用,系統啟動後仍然可以通過taskset指令指定哪些程式在這些核心中運作。步驟如下所示。
指令:vim /boot/grub2.cfg
在linux kernel啟動參數裡面加入isolcpus參數,isolcpu=2,3。
指令:cat /proc/cmdline
等待系統重新啟動之後檢視啟動參數boot_image=/boot/vmlinuz-3.17.8-200.fc20.x86_64 root=uuid=3ae47813-79ea-4805-a732-21bedcbdb0b5 ro lang=en_us.utf-8 isolcpus=2,3。
3.1.4 dpdk的多線程
dpdk的線程基于pthread接口建立,屬于搶占式線程模型,受核心排程支配。dpdk通過在多核裝置上建立多個線程,每個線程綁定到單獨的核上,減少線程排程的開銷,以提高性能。
dpdk的線程可以作為控制線程,也可以作為資料線程。在dpdk的一些示例中,控制線程一般綁定到master核上,接受使用者配置,并傳遞配置參數給資料線程等;資料線程分布在不同核上處理資料包。
1.?eal中的lcore
dpdk的lcore指的是eal線程,本質是基于pthread(linux/freebsd)封裝實作。lcore(eal pthread)由remote_launch函數指定的任務建立并管理。在每個eal pthread中,有一個tls(thread local storage)稱為_lcore_id。當使用dpdk的eal‘-c’參數指定coremask時,eal pthread生成相應個數lcore并預設是1:1親和到coremask對應的cpu邏輯核,_lcore_id和cpu id是一緻的。
下面簡單介紹dpdk中lcore的初始化及執行任務的注冊。
(1)初始化
1)rte_eal_cpu_init()函數中,通過讀取/sys/devices/system/cpu/cpux/下的相關資訊,确定目前系統有哪些cpu核,以及每個核屬于哪個cpu socket。
2)eal_parse_args()函數,解析-c參數,确認哪些cpu核是可以使用的,以及設定第一個核為master。
3)為每一個slave核建立線程,并調用eal_thread_set_affinity()綁定cpu。線程的執行體是eal_thread_loop()。eal_thread_loop()的主體是一個while死循環,調用不同子產品注冊到lcore_config[lcore_id].f的回調函數。
(2)注冊
不同的子產品需要調用rte_eal_mp_remote_launch(),将自己的回調處理函數注冊到lcore_config[].f中。以l2fwd為例,注冊的回調處理函數是l2fwd_launch_on_lcore()。
rte_eal_mp_remote_launch(l2fwd_launch_one_lcore, null, call_master);
dpdk每個核上的線程最終會調用eal_thread_loop()--->l2fwd_launch_on_lcore(),調用到自己實作的處理函數。
最後,總結整個lcore啟動過程和執行任務分發,可以歸納為如圖3-5所示。
2.?lcore的親和性
預設情況下,lcore是與邏輯核一一親和綁定的。帶來性能提升的同時,也犧牲了一定的靈活性和能效。在現網中,往往有流量潮汐現象的發生,在網絡流量空閑時,沒有必要使用與流量繁忙時相同的核數。按需配置設定和靈活的擴充伸縮能力,代表了一種很有說服力的能效需求。于是,eal pthread和邏輯核之間進而允許打破1:1的綁定關系,使得_lcore_id本身和cpu id可以不嚴格一緻。eal定義了長選項“--lcores”來指定lcore的cpu親和性。對一個特定的lcore id或者lcore id組,這個長選項允許為eal pthread設定cpu集。
格式如下:
--lcores=’@cpu_set,...]’
其中,‘lcore_set’和‘cpu_set’可以是一個數字、範圍或者一個組。數字值是“digit([0-9]+)”;範圍是“-”;group是“([,,...])”。如果不指定‘@cpu_set’的值,那麼預設就使用‘lcore_set’的值。這個選項與corelist的選項‘-l’是相容的。
這個選項以及對應的一組api(rte_thread_set/get_affinity())為lcore提供了親和的靈活性。lcore可以親和到一個cpu或者一個cpu集合,使得在運作時調整具體某個cpu承載lcore成為可能。
而另一個方面,多個lcore也可能親和到同一個核。這裡要注意的是,同一個核上多個可搶占式的任務排程涉及非搶占式的庫時,會有一定限制。這裡以非搶占式無鎖rte_ring為例:
1)單生産者/單消費者模式,不受影響,可正常使用。
2)多生産者/多消費者模式且pthread排程政策都是sched_other時,可以使用,性能會有所影響。
3)多生産者/多消費者模式且pthread排程政策有sched_fifo或者sched_rr時,建議不使用,會産生死鎖。
3.?對使用者pthread的支援
除了使用dpdk提供的邏輯核之外,使用者也可以将dpdk的執行上下文運作在任何使用者自己建立的pthread中。在普通使用者自定義的pthread中,lcore id的值總是lcore_id_any,以此确定這個thread是一個有效的普通使用者所建立的pthread。使用者建立的pthread可以支援絕大多數dpdk庫,沒有任何影響。但少數dpdk庫可能無法完全支援使用者自建立的pthread,如timer和mempool。以mempool為例,在使用者自建立的pthread中,将不會啟用每個核的緩存隊列(mempool cache),這個會對最佳性能造成一定影響。更多影響可以參見開發者手冊的多線程章節。
4.?有效地管理計算資源
我們知道,如果網絡吞吐很大,超過一個核的處理能力,可以加入更多的核來均衡流量提高整體計算能力。但是,如果網絡吞吐比較小,不能耗盡哪怕是一個核的計算能力,如何能夠釋放計算資源給其他任務呢?
通過前面的介紹,我們了解到了dpdk的線程其實就是普通的pthread。使用cgroup能把cpu的配額靈活地配置在不同的線程上。cgroup是control group的縮寫,是linux核心提供的一種可以限制、記錄、隔離程序組所使用的實體資源(如:cpu、記憶體、i/o等)的機制。dpdk可以借助cgroup實作計算資源配額對于線程的靈活配置,可以有效改善i/o核的閑置使用率。