本節書摘來自華章出版社《編譯與反編譯技術實戰 》一書中的第3章,第3.1節,龐建民 主編 ,劉曉楠 陶紅偉 嶽 峰 戴超 編著,更多章節内容可以通路雲栖社群“華章計算機”公衆号檢視。
詞法分析是編譯過程的第一步,也是編譯過程必不可少的步驟。編譯過程中執行詞法分析的程式稱為詞法分析器。構造詞法分析器有兩種方法:一種是用手工方式,即根據識别語言的狀态轉換圖,使用某種進階語言直接編寫詞法分析器;另一種是利用自動生成工具(如lex)自動生成詞法分析器。本章分别介紹如何手動和自動構造詞法分析器。
本節首先介紹詞法分析器的功能及其輸出的單詞符号的表示方式,然後介紹其輸入和處理。
詞法分析器又叫作掃描器,其功能是從左往右逐個字元地對源程式進行掃描,然後按照源程式的構詞規則識别出一個個單詞符号,把作為字元串的源程式等價地轉化成單詞符号串的中間程式。單詞符号是程式設計語言中基本的文法單元,通常分為5種:
1)關鍵字(又稱基本字或保留字):程式設計語言中定義的具有固定意義的英文單詞,通常不能用作其他用途,比如c語言中的while、if、for等都是關鍵字。
2)辨別符:用來表示名字的字元串,如變量名、數組名、函數名等。
3)常數:包括各種類型的常數,如整型常數386、實型常數0.618、布爾型常數true等。
4)運算符:又分為算術運算符,如+、-、*、/等;關系運算符,如=、>=、>等;邏輯運算符,如 or、not、and等。
5)界符:如“,”“;”“(”“)”“:”等。
在上面所給出的5種單詞符号中,關鍵字、運算符和界符是程式設計語言提前定義好的,是以它們的數量是固定的,通常隻有幾十個或者上百個。而辨別符和常數是程式設計人員根據程式設計需要按照程式設計語言的規定構造出來的,是以數量即便不是無窮,也是非常大的。
詞法分析器輸出的單詞符号通常用二進制式(單詞種别,單詞符号的屬性值)表示。其中:
1)單詞種别。單詞種别表示單詞種類,常用整數編碼,這種整數編碼又稱為種别碼。至于一種程式設計語言的單詞如何分類、怎樣編碼,主要取決于技術上的友善。一般來說,基本字可“一字一種”,也可将其全體視為一種;運算符可“一符一種”,也可按運算符的共性分為幾種;界符一般采用“一符一種”分法;辨別符通常統歸為一種;常數可統歸為一種,也可按整型、實型、布爾型等分為幾種。
2)單詞符号的屬性值。單詞符号的屬性值是反映單詞特征或者特性的值,是編譯中其他階段所需要的資訊。如果一個種别隻含有一個單詞符号,那麼其種别編碼就完全代表了自身的值,是以相應的屬性值就不需要再單獨給出。如果一個種别含有多個單詞符号,那麼除了給出種别編碼之外還應給出單詞符号自身的屬性值,以便把同一種類的單詞差別開來。例如,對于辨別符,可以用它在符号表的入口指針作為它自身的值;而常數也可用它在常數表的入口指針或者其二進制值作為它自身的值。
詞法分析器的結構如圖3-1所示。
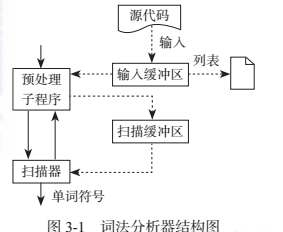
詞法分析器首先将源程式文本輸入到一個緩沖區中,該緩沖區稱為輸入緩沖區,單詞符号的識别可以直接在輸入緩沖區中進行。但通常情況下為了識别單詞的友善,需要對輸入的源程式字元串進行預處理。對于許多程式語言來說,空格、制表符、換行符等編輯性字元隻有出現在符号常量中時才有意義;注釋幾乎可以出現在程式中的任何地方。但編輯性字元和注釋的存在一般隻是為了改善程式的易讀性和易了解性,不影響程式本身的文法結構和實際意義,通常在詞法分析階段可以通過預處理将它們删除。是以可以設計一個預處理子程式來完成上述工作,每當詞法分析器調用預處理子程式時,其便處理一串固定長度的源程式字元串,并将處理結果放在詞法分析器指定的緩沖區中,稱為掃描緩沖區。接下來單詞符号的識别就可以直接在該掃描緩沖區中進行,而不必考慮其他雜務。
掃描器對掃描緩沖區進行掃描時通常使用兩個指針,即開始指針和搜尋指針,其中,開始指針指向目前正在識别的單詞的起始位置,搜尋指針用于向前搜尋以尋找該單詞的終點位置,兩個指針之間的符号串就是目前已經識别出來的那部分單詞。剛開始時,兩個指針都指向下一個要識别的單詞符号的開始位置,然後,搜尋指針向前掃描,直到發現一個單詞符号為止,一旦發現一個單詞,搜尋指針指向該單詞的右部,在處理完這個單詞以後,兩個指針同時指向下一個要識别的單詞符号的起始位置。
為了解決程式設計語言中某些單詞符号可能存在公共字首的問題,在進行詞法分析時需采用所謂超前搜尋技術,也即詞法分析器在讀取單詞時,為了判斷是否已讀入整個單詞的全部字元,常采取向前多讀取字元并通過讀取的字元來判别的方式。
![seq2seq模型 + Attention機制[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)