基于事實的模型中的每個事實都捕捉了一段資訊。但事實本身不能表達資料背後的結構。也就是說,資料集中沒有包含事實類型的描述,也沒有它們之間關系的任何解釋。本節将介紹圖模式—圖捕獲使用基于事實的模型進行存儲的資料集的結構。我們将讨論圖模式的元素,以及使得一個模式可實施的需要。
讓我們首先将facespace的事實建構成一個圖。
2.2節詳細讨論了facespace事實。每個事實都代表一條使用者資訊或兩個使用者之間的關系。圖2-16描述了一個圖模式,用以表示facespace事實之間的關系,針對使用者、他們的個人資訊和他們之間的關系,它提供了一個有用的可視化。
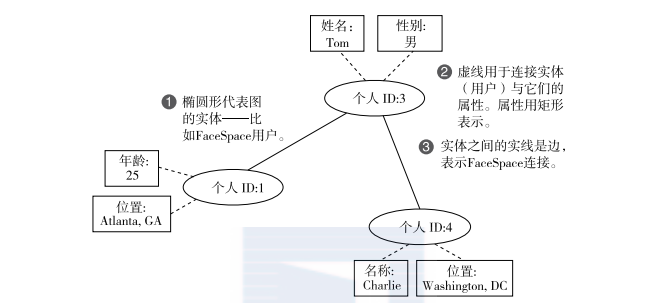
圖2-16 可視化facespace事實之間的關系
該圖強調了圖模式的三個核心元件—節點、邊和屬性:
節點是系統中的實體。在這個例子中,節點是facespace使用者,由使用者id表示。再如,如果facespace允許使用者将自己看作一邊是節點之間的關系。在facespace中,邊的含義是顯而易見的—使用者之間的邊代表了facespace朋友關系。以後你可以在使用者之間添加額外的邊類型,用以辨別同僚、家人或同學。
屬性是關于實體的資訊。在這個例子中,年齡、性别、位置和所有其他個人資訊都是屬性。
節點之間的邊是嚴格的:盡管在圖2-16中,屬性和節點看起來是連接配接的,但這些線不是邊。它們隻是用于輔助說明使用者及其個人資訊之間的關系。我們用實線代表邊、虛線代表屬性連接配接,來表示它們之間的不同。
圖模式對資料集包含的所有資料提供了一個完整的描述。接下來将讨論確定資料集内的所有事實都嚴格遵循該模式的必要性。
這時,資訊被存儲為事實,并且用圖模式描述了資料集包含的事實的類型。你覺得都準備好了,是嗎?不,你還需要确定以什麼格式存儲事實資料。
一種方法是使用半結構化的文本格式,比如json。這種格式可實作簡單性和靈活性,基本上允許将任何資料寫入主資料集,但在這種情況下,對我們的需求來說有點過于靈活了。
為了說明這個問題,假設你選擇使用json來表示tom的年齡:
這對于單個事實的表示是沒有問題的,但沒有辦法確定所有随後的事實都遵循相同的格式。由于人為錯誤,資料集也可能包含這樣的事實:
這些例子都是有效的json,但它們格式不一緻或丢失了資料。尤其是,2.2節強調了每個事實有一個時間戳的重要性,但文本格式不能執行此要求。為了有效地使用資料,你必須為資料集的内容提供保障。
另一種方法是使用一個可實施的模式來嚴格定義事實的結構。可實施的模式預先需要做更多的工作,但是它們保證所有必需的字段都存在,并確定所有值是預期的類型。有了這些保證,開發人員将對他們期待的資料充滿自信—每個事實都有一個時間戳,使用者的名字永遠是一個字元串,等等。關鍵之處在于,當建立一塊資料發生錯誤時,可實施的模式會即刻給出錯誤提示,而不是稍後有人試圖在不同的系統中使用資料時才發現錯誤。錯誤越早暴露為bug,就越容易捕捉和修複。
在第3章中,你将看到如何使用序列化架構來實作一個可實施的模式。序列化架構提供了一種與語言無關的方式來定義模式中的節點、邊和屬性,然後生成代碼(可能以很多不同的語言),用來序列化和反序列化模式中的對象,這樣它們就可以存儲到主資料集并被檢索到。
此時你可能很想知道細節,不要擔心—最好的學習方式是實踐。在2.4節中,我們将在superwebanalytics.com實體中設計基于事實的模型,并在第3章中使用序列化架構來實作它。
![Ajax——模闆引擎[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)