本節書摘來自華章出版社《偉大的計算原理》一書中的第2章,第2.1節,作者[美]彼得 j. 丹甯(peter j. denning)克雷格 h. 馬特爾(craig h. martell),更多章節内容可以通路雲栖社群“華章計算機”公衆号檢視。
<b></b>
<b>第2章</b>
<b>great principles</b>
of computing
<b>計 算 領 域</b>
生物學是一種資訊科學。
——david baltimore
除了理論和實驗之外,計算是進行科學研究的第三種方式。
——kenneth wilson
科學與科學應用密不可分,如同一個樹上結出的多枚果實。
——louis pasteur
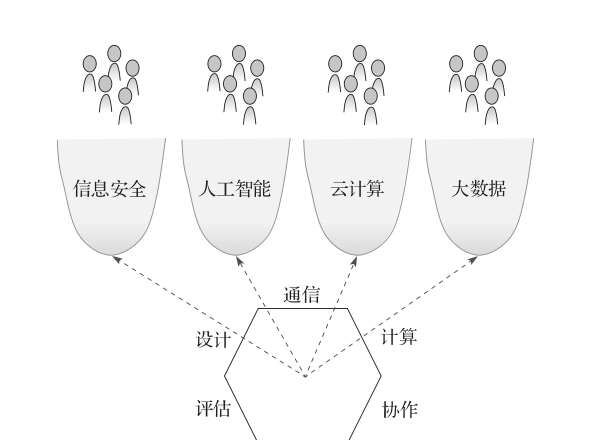
計算活動由人類實施,而不是基本原理。在長期的實踐活動中,人們的計算活動逐漸形成了豐富多樣的計算領域(computing domain)。每一個計算領域主要關注一項技術或其應用。例如,資訊安全領域主要關注資訊安全技術,而隐私領域則主要關注如何應用資訊安全技術來保護個人的隐私資訊。這些領域中的實踐者分享相似的問題、技巧、方法,享受計算的基本原理帶給他們的權利,同時也受到這些原理的限制。本書所闡述的計算的重要原理不可能脫離這些計算領域而獨立存在(rosenbloom 2012)(見圖2.1)。
空氣動力學數字仿真是計算領域的一個執行個體。為了更有效地設計飛機,計算機科學家和航空領域的專家進行了長期的協同工作。自20世紀80年代以來,飛機制造公司開始使用數字仿真技術來設計機翼和機身。傳統方法通過風洞和樣機進行機翼和機身的設計,對于大尺寸複雜飛機的設計已經不具有可行性。通過運作在大規模并行超級計算機上的新型算法,工程師已經可以在不經過風洞試驗的情況下設計出可以安全飛行的飛機。波音777是第一種完全通過數字化設計産生的飛機。航空專家和計算機專家緊密合作,産生了一個新的科學領域——計算流體力學,來計算氣流的複雜運動。他們基于3d網格設計出相應的計算方法來求解機身周圍空氣的流體力學方程。他們探索出一種快速多重網格算法,能夠基于超立方體并行處理器網絡在很短的時間内完成大尺寸機身的設計工作(chan and saad 1986,denning 1987)。他們還設計了動态網格精化方法,來提高氣壓和流速變化劇烈區域的計算精度。其中的有些方法甚至展現出了全新的計算基本原理。基于這些進展,計算方法已經成為流體力學不可缺少的構成成分。
圖2.1 圖中底部所示的6種類型的計算原理都關注于通過管理物質和能量來産生預期的計算行為。而圖中上部的計算領域則是實踐領域。這些實踐領域中的人們通過靈活應用計算的基本原理來求解他們遇到的各種問題(帶箭頭的虛線)。這些實踐領域中的工作為計算也為自身探索出新的基本原理
目前已經發展了豐富多樣的計算領域。acm(association for
computing machinery)總結出其成員所關注的42種計算領域,以及數十種的相關的領域(denning
and frailey 2011)。本章我們簡單介紹一下4種計算領域:資訊安全、人工智能、雲計算、大資料。對每個計算領域,我們重點關注4個方面的因素:
涉及哪些人;
關注什麼問題;
涉及哪些計算基本原理;
如何為計算和所在領域帶來新的基本原理。
這種分析有可能揭示一些新的基本原理,并幫助實踐者了解計算能夠給他們帶來的利益和限制,也有可能幫助探索不同技術之間的聯系,進而為未來的創新埋下伏筆。
在深入這些計算領域之前,我們應該進一步加深對計算領域與計算基本原理兩者之間關系的了解。這種了解能夠幫助我們更好地分析這些領域。
領域和基本原理
有兩種基本政策來表示特定學科的知識體系。一種政策羅列出該學科包含的所有領域,另一種政策則羅列出所有的基本原理。對同一知識空間的不同表示會對實踐活動産生不同的指導意義。在本章中,我們使用“領域”(domain)來表示技術領域,即關注特定技術的領域。
教育者通常使用“知識體系”(bok)一詞來表示對特定學科知識的系統化描述,并且基于知識體系來設計相應的課程體系。acm在1968年給出了關于計算的第一個知識體系,并在1989年、2001年和2013年進行了更新。1989年版本包含了計算的9個核心領域(denning et al. 1989),2001版本包含了14個(acm education board 2001),2013版本則進一步擴充到18個(acm education
board 2013)。之是以将這些子領域稱為核心領域,是因為這些領域都或多或少為其他領域提供了基礎技術支援。
基本原理架構(如本書所給出的計算基本原理架構)與面向應用領域的架構是正交的。一條基本原理可能會出現在多個領域中,而一個領域可能會依賴于多條基本原理。這些被領域所依賴的基本原理,其演化速度遠低于技術的演化速度。
雖然這兩種風格的架構具有很大的差異性,但它們也存在緊密的關聯。為了更形象地感受到這種緊密關聯,我們可以想象這樣一個二維矩陣:每一行代表一個領域,每一列代表一類基本原理,所有的單元格則代表了特定方面的知識空間(見圖2.2)。

圖2.2 關于計算的知識空間可以被表示為一個矩陣:其中,列代表不同類型的基本原理,行代表不同的領域。圖中灰色背景的單元格中給出了資訊安全領域使用到的兩個協作類型的基本原理:密鑰配置設定協定(用于安全地配置設定密鑰);零知識證明(用于在兩個參與者之間安全地交換私密資訊)
基于這種矩陣,我們可以說:面向技術的知識體系是對該矩陣中行的羅列,而面向基本原理的知識體系則是對矩陣列的羅列。這兩種知識體系從不同的角度對相同的知識進行了闡述。
設想一個人試圖羅列出一個技術涉及的所有基本原理。這個人可以從基本原理的6種類别出發分析出該技術領域涉及的所有基本原理,即對應于矩陣中的一行(見圖2.3)。在本章的餘下部分,我們将用這種方式對4個領域涉及的基本原理進行分析。
圖2.3 安全領域涉及的計算基本原理在矩陣中對應于安全領域所在的那一行。如同大多數的計算領域一樣,安全領域涉及的計算基本原理也可以劃分為六種類型
這種基本原理架構也指出了另外一種分析方法:一個人可以羅列出涉及特定基本原理的所有技術(見圖2.4)。
圖2.4 協作技術表現為矩陣中協作所在的那一列。在幾乎所有的計算領域中(包括列出的6種計算領域)都會涉及協作相關的基本原理
資訊安全
資訊安全是計算機科學中一個具有悠久曆史的領域。甚至在任務批處理大行其道的時代,使用者就開始關注存放于計算機中的資料的安全問題。計算機是否存放在一個實體安全的地方?在一個新的任務被裝載前,存儲器是否已被清空?操作者的錯誤或硬體失效是否會導緻資料的丢失?
1960年左右,随着第一代多道程式分時系統的出現,作業系統的設計者就已經對資訊保護問題有了深刻的實踐認知。他們設計出各種方式對主存儲器進行分區,進而保證不同程式的代碼和資料不會混淆在一起。這其中,虛拟存儲器是最複雜的一種機制。他們發明了分層檔案系統,使得使用者可以真正地管理他們的檔案,并設定其他使用者對這些檔案的通路權限。他們發明了密碼系統以避免未經授權的使用者使用計算機。他們構造了多種結構,以避免特洛伊木馬或其他惡意軟體對系統和資料的幹擾和破壞。他們發明了多種通路控制機制,使得機密資訊無法寫入公共檔案中。他們建立了針對計算機操作者的各種操作政策,以保護資料和防範入侵。自1970年以來,人們已經廣泛認識到,保證資訊的安全是作業系統設計者一項責無旁貸的任務(denning 1971,saltzer and schroeder 1975)。
20世紀70年代的arpanet、80年代的internet、90年代的網際網路(world wide web)提供了一種世界範圍的資訊共享網絡,也使得資訊的丢失或偷盜成為一個更加現實的問題。密碼系統在資訊安全和身份驗證中承擔了核心角色(denning 1982)。設計者在實踐中遇到并應對各種問題,比如:資料庫記錄保護、密碼保護、基于生物資訊的使用者驗證、反入侵保護、入侵檢測、病毒/蠕蟲/惡意軟體的防範、多層安全系統、資訊流管理、匿名事務、信任分級準則、資料恢複等。法律實踐專家開始遇到越來越多的針對計算機系統的犯罪行為,并開始喚醒每個人對個人資訊重要性的認識。然而,很少有人認真對待這個問題。為了能夠更快地傳遞新的系統,很多開發者開始降低對資訊安全的重視程度。他們認為,等到資訊安全問題真正出現後再亡羊補牢,也未為遲也。這種觀點注定是錯誤的。大量可被輕易入侵的系統出現在重要的業務活動中,這些系統缺乏對資訊保護的系統性考慮,因而對各種(善意、惡意或無意的)操作采取了寬松容忍的政策。
随着越來越多的金融資料、人事資料、個人隐私資料以及公司資料被存儲在可線上通路的計算機中,對這些資料的惡意入侵行為出現了極大地增加。安全專家已經開始擔憂資訊戰争的可能性(denning 1998)。隐私專家則向公衆奮力疾呼保護個人隐私資料的重要性,這關系到我們每個人的基本自由(garf?inkel 2001)。在1999年,公衆開始普遍擔心“千年蟲”問題有可能導緻網絡的崩潰,這個問題産生的原因是在計算機中一個年份資料被存儲為兩位而不是四位十進制數。自此以後,人們開始關注到資訊網絡的脆弱性問題以及保證資訊安全的重大挑戰。多國專家開始憂慮大規模的資訊攻擊行為有可能導緻世界經濟甚至人類文明的毀滅(schneier 2004,2008,clark 2012)。表2.1給出了資訊安全領域涉及的人、問題以及計算基本原理。
人工智能
讓機器可以執行人類智力活動的想法可以追溯到5個世紀之前。1642年,blaise pascal建造了一台機械式電腦。1823年,charles babbage發明了差分機,用于自動進行算數函數的計算。在19世紀後期,一個名為“mechanical turk”的自動下棋機器人,在受到廣泛關注後最終被發現隻是一個惡作劇(standage 2003)。實際上,很多這些類似的想法都可以被看作人工智能的萌芽(russell and norvig
2010)。
1956年,在claude shannon和nathaniel rochester的幫助下,john mccarthy在德國達特茅斯組織了一次研讨會。這次研讨會标志着人工智能領域的誕生。當時,研究者的一個基本觀點是“原則上,人類智能的機理可以被精确地描述出來,是以,可以用機器來仿真人類智能”。這種觀點是非常合理的,因為很多人類智力活動似乎就是在執行某種算法,而且人的大腦似乎就是一個可以執行算法的電子化網絡。herbert simon預測,到1967年計算機可能成為世界象棋冠軍,可能發現并證明一些重要的數學定理,而且很多心理學理論可以展現在計算機程式中。他的第一個設想比預計時間遲到了30年才得以實作,而剩下的兩個設想目前仍然沒有實作。
圖靈(1950)為現代人工智能留下了很多火種:圖靈測試、機器學習以及通過“成長”形成一台智能機器。圖靈意識到,由于對“智能”一詞人們始終缺少一個足夠明确的定義,以至于無法有效衡量一台機器是否有智能或具有何種程度的智能。他提出的模拟遊戲(即圖靈測試)不再關注一台機器是否有智能,轉而關注一台機器是否表現出智能的行為。他預測,到2000年,機器至少能夠讓70%的人類評審者在5分鐘的時間内無法判斷與之交談的是一台機器還是一個人類。這個設想到目前還沒有實作。
圖靈關于智能的行為觀點在人工智能領域的形成中起到了重要作用。然而,到20世紀70年代,這種觀點受到了尖銳的批判。很多人工智能項目開始以設計“專家系統”為目标,即:構造出與某些領域(如醫學診斷領域)的人類專家具有相同能力的智能系統。hubert dreyfus(1972,1992)則堅持認為,專家的行為絕不是基于規則的機器所能完全模拟的。當時,人們對這種觀點嗤之以鼻,但時間證明了這種觀點的正确性。隻有非常少的專家系統表現出一定的實用價值,但沒有一個專家系統能夠達到人類專家的水準。john searle(1984)則認為傳統機器具有智能是不可能的:一個基于規則的機器可能可以使用中文與人對話,但機器根本不知道這些中文的含義。他不認同“強人工智能”的概念(即機器行為能産生意識),而更偏向于“弱人工智能”(即機器能夠模仿出人類的行為,但這種模仿背後的機制可能與人類大腦的工作機制沒有任何相似之處)。terry winograd和fernando flores(1987)認為人工智能基于某些人類的哲學假設,而這些假設可能根本無法解釋智能的工作機理或根本無法導緻智能的産生。
到20世紀80年代中期,人們逐漸意識到關于人工智能的很多初始設想很難在短時間内實作。提供研究基金的機構開始停止向人工智能領域提供新的資金支援并且要求已有研究項目提供更為确實的研究成果。缺少資金的支援,很多研究者無法展開具體的研究工作,轉而開始認真反思這個領域面臨的問題。人工智能領域的先驅者raj reddy将這一黑暗時期稱為“人工智能的冬天”。
這一時期的反思醞釀了人工智能研究的一個新方向。人們不再關注如何對人類意識活動進行模組化,轉而去尋求構造一些能夠替代人類認知活動的智能系統。自動認知系統的工作原理不需要與人類意識活動的原理相一緻。它們甚至根本不去刻意模仿人類解決問題的過程。這一新方向更強調通過實驗來确認所提出的自動化工作原理是否有用、可靠和安全(russell and norvig 2010,nilsson 2010)。這一新方向最近引起公衆廣泛關注的進展包括:1997年ibm深藍國際象棋程式擊敗國際象棋世界冠軍garry kasparov,2010年google的無人駕駛汽車,2011年ibm的watson計算機在益智問答遊戲節目“危險邊緣”中獲得冠軍(擊敗人類對手)。這些計算機程式中使用到的方法具有極高的效率,但卻沒有刻意模仿人類思考或大腦運作的機制。同時,這些方法僅對解決特定的問題有效,而不具有通用性。
計算機科學、認知科學、醫學及心理學領域的很多研究者仍然在研究人腦的工作機理和意識的産生機理。kurzweil的暢銷書《奇點臨近》(kurzweil 2005)和2013年對外公布的研究項目brain
activity map project表明,這個研究方向仍然具有非常強大的吸引力。
人工智能的重生顯示了巨大的成功,進而産生了一些嶄新的關注點。在與機器的競賽過程中,erik brynjolfsson和andrew mcafee(2012)發現,自動化的浪潮正逐漸取代人類在知識相關領域的工作,正如在上個世紀中機械自動化取代了大量的人類體力勞動。知識自動化的執行個體包括:電話轉接中心、語音菜單系統、線上商品交易、線上銀行、政府服務、出版、新聞傳播、音樂釋出、廣告、監管、反恐等方面。筆者所擔憂的是我們正滑向一個不需要大量人工勞動的社會,而這個社會又無法為大量失業的人類個體提供充足的資源。
表2.2給出了人工智能領域涉及的人、問題以及計算基本原理。
雲計算
雲計算是一個現代的時髦概念,其背後隐藏了關于資訊共享和分布式計算的豐富含義。大量計算裝置的互聯産生了一種規模經濟:在其中,人們不再關注服務和資料存放的實體位置。“雲”這個術語出現在20世紀90年代後期,可能是在相關的技術或市場研讨中,人們使用雲來比喻由計算機構成的網絡。
早在20世紀60年代中期,mit的mac項目已經展現出了類似的想法,即:建構一種能夠向衆多使用者提供計算資源共享的系統。mac是詞組“multiple-access
computer”中單詞的首字母縮寫,有時也代表“man
and computer”。該項目産生了multics系統,一個強大的可以對記憶體、外存、cpu等昂貴的計算資源進行分時複用的多道程式系統(每個使用者使用這些資源的成本得到了極大的降低)。j.
c. r. licklider是這種思想靈感的提出者。他認為,計算資源應該成為一種基礎設施,任何人都應該可以很友善地接入其中(licklider 1960)。
在1969年底開始運作的計算機網絡arpanet使得“計算成為基礎設施”的宏偉設想得以成真。arpanet的設計目标就是資源共享:接入網絡的任何使用者都可以與網絡中的其他計算節點互聯并使用其上提供的服務。是以,沒有必要去複制一個已經共享的服務(在服務品質能夠得到保障的前提下)。arpanet的設計者很快意識到,共享服務應該通過名稱而不是實體位置來進行通路,是以,開發一種位置無關的尋址系統對于屏蔽網絡通信的底層細節至關重要。vint cerf和bob kahn發明了tcp/ip通信協定(1974),能夠支援網際網路上的任何兩台計算機在僅知曉對方ip位址(一種邏輯位址)而無需知曉實體位址的情況下進行資訊傳遞。1983年,arpanet開始正式使用tcp/ip協定。
1984年,arpanet開始使用域名系統,一種将特定的字元串映射到ip位址的線上資料庫(例如,将字元串“gmu.edu”映射為ip位址“129.174.1.38”)。域名系統帶來了另一個層次上的位置無關性:使用者現在隻需要記住一些具有語音資訊的字元串,就能夠通路對應的網際網路服務。
到20世紀90年代,網際網路(world wide web)的出現使得任何資訊對象都可以在網際網路上進行共享。資訊對象使用url(uniform resource locator,統一資源定位符)進行命名。url的基本格式是“主機名/路徑名”,其中路徑名指出了一個資訊對象在給定主機上的目錄位置。20世紀90年代中期,robert kahn設計了一個網際網路服務handle.net。該服務可以把一個具有唯一性的辨別符映射為一個資訊對象的url。基于此,他還為美國國會圖書館和大多數的出版商設計了doi(digital object
identif?ier,數字對象辨別符)系統(kahn
and wilensky 2006)。doi提供了更高層級的透明性:一旦為一個數字對象賦予一個doi之後,這個doi将永久指向該數字對象,無論該對象存放在何處或何時被建立(denning and kahn
面向終端使用者的分布式計算服務的技術架構在近年來持續發展。multics系統使得一個大型計算機系統可以在其使用者間分享計算資源。20世紀70年代,施樂palo alto研究中心(parc)構造了alto系統,一個由連接配接至以太網的一組圖形工作站形成的網絡(metcalfe and boggs
1983)。施樂将該系統的體系結構命名為“用戶端-伺服器”架構,因為使用者總是通過一個本地的接口(用戶端)來通路網絡上的服務。x-window系統(1984年源于mit)是一個通用的用戶端-伺服器系統:它支援一個新的服務提供者将其硬體和使用者接口接入網絡,而無需設計相應的用戶端-伺服器通信協定。今天,大多數的web服務都使用了用戶端-伺服器架構:服務提供者通過展現在标準web浏覽器上的界面為使用者提供服務。大多數雲中的服務也采用用戶端-伺服器架構,其中url系統對伺服器的實體位置進行了完全的屏蔽。
表2.3給出了雲計算領域涉及的人、問題以及計算基本原理。
大資料
大資料是最近出現的另一個時髦概念,其背後隐藏了關于計算的豐富資訊。大資料關注如何對網際網路上的海量資料進行分析,從中發現有價值的統計規律和相關性等資訊。這種分析可以廣泛應用于各種領域,例如科學、工程、商業、人口普查、執法等。
計算機科學家對資料的存儲、查詢及處理已經進行了長時間的關注,而且很多關注的問題甚至比目前的技術進展還要超前。可惜的是,這些超前的想法由于各種因素的影響被埋沒在曆史的塵埃中,被大衆所遺忘。“大資料”這一術語在很大程度上是新瓶裝舊酒,雖然這一術語确實對很多領域産生了顯著的影響。例如,在商業活動中,商業組織收集海量的客戶相關資料,并利用這些資料去發現市場趨勢、廣告投放對象以及客戶忠誠度等資訊。受到公共資金資助的科研項目也被要求對外公開其資料,以友善公衆和其他科研項目能夠對這些資料進行多方面的利用和分析。警察系統則利用海量的通信資訊和信用卡交易資訊,從中發現犯罪分子。所有這些領域都開始主動尋求資料科學家、資料分析師以及資料系統設計師來幫助他們進行資料分析工作。
計算機科學家在其中的貢獻主要展現在兩個方面。一方面是關于更高效地資料分析方法,另一方面則是能夠支援海量資料處理的系統或技術架構。例如,richard karp(1993)基于組合方法實作了對基因資料片段進行融合進而形成基因組圖譜的高效算法。tony chan和yousef saad(1986)的研究工作表明,hypercube(一種早期出現的并行計算架構)對于多重網格算法(一類重要的數字計算方法)具有最優的效果,而多重網格算法能夠對大規模資料空間的數學模型進行求解。jeffrey dean和sanjay ghemawat(2008)設計了mapreduce算法,能夠支援數千個處理器通過并行的方式對海量資料進行處理。
在商業領域中,如何對大規模資料集進行處理和分析一直以來都是一個重要的問題。商業組織會收集關于客戶、庫存、産品制造、财務等方面的各種資料,這些資料對于一個大型的國際化商業組織的正常運轉具有非常重要的作用。20世紀30年代,一個電子計算機還未出現的年代,ibm靠出售類似卡片分類器和檢索器的簡單裝置從資料處理市場獲得了巨大的财富。20世紀50年代,ibm開始向電子資料處理領域發展,轉型成為一家計算機公司。1956年,ibm對外釋出了第一個硬碟存儲系統ramac 305,受到了廣泛關注。ibm聲稱,任何商業組織都可以将其堆滿倉庫的檔案資料轉移到一個小小的硬碟中,進而能夠對資料進行極為高效的處理。随着資料存儲需求的不斷增長,設計者開始關注如何對資料進行有效的組織進而實作對資料的快速通路和簡易維護。當時,兩個主流且存在競争關系的方法分别是綜合資料系統(integrated data system,ids)(bachman 1973)和關系資料庫系統(relational database system,rds)(codd 1970,1990)。綜合資料系統具有簡單、快速、實用等特點,能夠在管理大量資料檔案的同時隐藏檔案在硬碟上的實體結構和位置。關系資料庫系統則基于數學化的集合理論,它具有一個非常清晰的概念模型,但在經過了多年的發展後才實作了與綜合資料系統相當的處理效率。從20世紀70年代開始,研究領域形成了一個關于大規模資料庫(very large databases)的研究團體,并每年召開一次學術會議(vldb)對相關議題進行讨論。
從20世紀50年代開始,計算領域的研究者進入了文檔管理領域:幫助文檔管理者組織資料以實作更加快速的文檔檢索。圖書館是這些資訊檢索系統的第一代使用者。研究者開發了模糊查詢系統。例如,使用者可以發出“請查找關于資訊檢索的文檔”,而傳回的文檔中不一定包含“資訊檢索”這個字元串。今天,網際網路就是一個巨大的無結構的存儲系統。在網際網路上進行關鍵詞檢索非常快速但卻不夠準确,是以,有效的網際網路資訊檢索仍然是一個困難的問題(dreyfus 2001)。
gartner group将現代的“大資料”定義為4v:資料體量巨大(volume)、資料的産生速度快(velocity)、資料的表現格式豐富(variety)、資料對決策活動具有重要的支援作用(veracity is important to decisions)。從2014年開始,資料科學的課程或關于資料科學的研究中心在大學和其他研究機構中如雨後春筍般出現。多個領域都涉及其中,例如,來自運籌學和統計學領域的分析師、來自計算機科學和資訊系統領域的架構設計師以及來自模組化和仿真領域的可視化工程師。這些實踐和研究活動也确立了“資料科學”領域的主要研究問題:尋找對大規模資料集進行處理和分析的科學理論基礎。
表2.4給出了大資料領域涉及的人、問題以及計算基本原理。
總結
本書采用的關于計算重要原理的架構提供了一種有效的方式去分析特定技術所涉及的基本原理。這種架構也可以用來分析特定計算應用領域背後所基于的計算基本原理,在這些領域中,具有不同技術或工程背景的人之間互相配合來解決該應用領域中存在的問題。