本節書摘來自華章出版社《spark大資料分析:核心概念、技術及實踐》一書中的第3章,第3.2節,作者[美] 穆罕默德·古勒(mohammed guller),更多章節内容可以通路雲栖社群“華章計算機”公衆号檢視。
3.2 總體架構
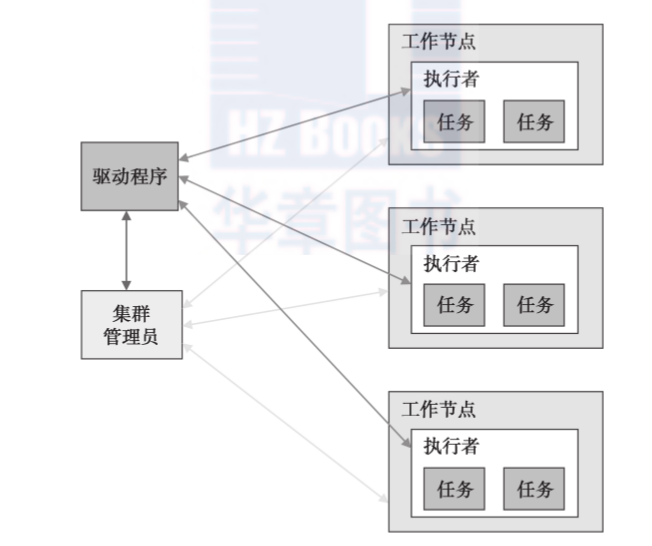
一個spark應用包括5個重要部分:驅動程式、叢集管理者、worker、執行者、任務(見圖3-1)。
3.2.1 worker
worker為spark應用提供cpu、記憶體和存儲資源。worker把spark應用當成分布式程序在叢集節點上執行。
3.2.2 叢集管理者
spark使用叢集管理者來獲得執行作業所需要的叢集資源。顧名思義,叢集管理者管理叢集中worker節點的計算資源。它能跨應用從底層排程叢集資源。它可以讓多個應用分享叢集資源并且運作在同一個worker節點上。
spark目前支援三種叢集管理者:單獨模式、mesos模式、yarn模式。mesos模式和yarn模式都允許在同一個worker節點上同時運作spark應用和hadoop應用。第10章将詳細介紹叢集管理者。
3.2.3 驅動程式
驅動程式是一個把spark當成庫使用的應用。它提供資料處理的代碼,spark将在worker節點上執行這些代碼。一個驅動程式可以在spark叢集上啟動一個或多個作業。
3.2.4 執行者
執行者是一個jvm程序,對于一個應用由spark在每一個worker上建立。它可以多線程的方式并發執行應用代碼。它也可以把資料緩存在記憶體或硬碟中。
執行者的生命周期和建立它的應用一樣。一旦spark應用結束,那麼為它建立的執行者也将壽終正寝。
3.2.5 任務
任務是spark發送給執行者的最小工作單元。它運作在worker節點上執行者的一個線程中。每一個任務都執行一些計算,然後将結果傳回給驅動程式,或者分區以用于shuffle操作。
spark為每一個資料分區建立一個任務。一個執行者可以并發執行一個或多個任務。任務數量由分區的數量決定。更多的分區意味着将有更多的任務并行處理資料。
![pyspark學習(一)—pyspark的安裝與基礎文法一 Pysaprk的安裝二:pyspark的簡單文法END[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)