本節書摘來自華章出版社《elk stack權威指南(第2版)》一書中的第1章,第1.2節,作者 饒琛琳 更多章節内容可以通路雲栖社群“華章計算機”公衆号檢視。
1.2 hello world
與絕大多數it技術介紹一樣,我們也以一個輸出“hello
world”的形式開始學習logstash。
1.指令行運作
在終端中,像下面這樣運作指令來啟動 logstash 程序:
# bin/logstash
-e 'input{stdin{}}output{stdout{codec=>rubydebug}}'
首先看到終端輸出一段程序啟動過程的提示輸出。提示以"successfully started logstash api endpoint
{:port=>9600}"結束。
然後你會發現終端在等待你的輸入。沒問題,敲入hello world,回車,看看會傳回什麼結果!
{
"message"
=>"hello world",
"@version"
=>"1",
"@timestamp"
=>"2014-08-07t10:30:59.937z",
"host"
=>"raochenlindemacbook-air.local",
}
沒錯!就是這麼簡單。
2.完整示例
指令行運作當然不是什麼特别友善的用法,是以絕大多數情況下,我們都是采用額外定義一個logstash.conf配置檔案的方式來啟動logstash。下面是我們的第一個完整版logstash.conf的示例:
input {
stdin { }
output {
stdout {
codec => rubydebug {}
}
elasticsearch {
rost=>["127.0.0.1"]
因為在5.0版本中,elasticsearch和kibana都是獨立服務。如果你按照上一節的最佳實踐配置好了yum的話,通過如下指令啟動服務即可:
# service
elasticsearch start && service kibana start
然後在終端上這樣運作:
-f logstash.conf
同樣,還是輸入一次hello world。你會看到和上一次一樣的一段ruby對象輸出。但事實上,這個完整示例可不止如此。打開另一個終端,輸入下面一行指令:
# curl
http://127.0.0.1:9200/_search?q=hello
你會看到終端上輸出下面這麼一段内容:
{"took":15,"timed_out":false,"_shards":{"total":27,"successful":27,"failed":0},"hits":{"total":1,"max_score":0.095891505,"hits":[{"_index":"logstash-2015.08.22","_type":"logs","_id":"au90s1engg_p5-w7sb32","_score":0.095891505,"_source":{"message":"hello
world","@version":"1","@timestamp":"2014-08-07t10:30:59.937z","host":"raochenlindemacbook-air.local"}}]}}
這時候你打開浏覽器,通路http://127.0.0.1:5601位址,按照提示完成index pattern配置(正常的話隻需要點選一下create按鈕),即可點選discover頁面看到如圖1-1所示的效果。你在終端上輸入的資料,可以從這個頁面上任意搜尋了。
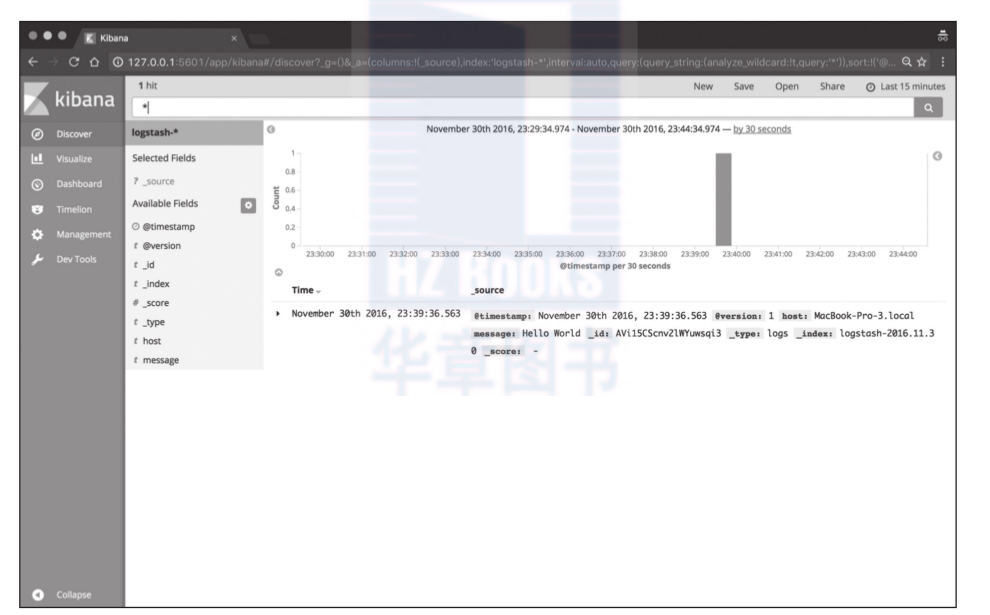
對index pattern配置有疑惑的讀者,可以閱讀本書第三部分關于kibana的章節。
3.解釋
每位系統管理者都肯定寫過很多類似這樣的指令:cat randdata | awk '{print $2}' | sort | uniq -c | tee sortdata。這個管道符|可以算是linux世界最偉大的發明之一(另一個是“一切皆檔案”)。
logstash就像管道符一樣!
輸入(就像指令行的cat)資料,然後處理過濾(就像awk或者uniq之類)資料,最後輸出(就像tee)到其他地方。
當然實際上,logstash是用不同的線程來實作這些的。如果你運作top指令然後按下h鍵,你就可以看到下面這樣的輸出:
pid user pr
ni virt res
shr s %cpu %mem time+ command
21401 root 16
0 1249m 303m 10m s 18.6 0.2 866:25.46 |worker
21467 root 15
0 1249m 303m 10m s 3.7
0.2 129:25.59 >elasticsearch.
21468 root 15
0 1249m 303m 10m s 3.7
0.2 128:53.39 >elasticsearch.
21400 root 15
0 1249m 303m 10m s 2.7
0.2 108:35.80 <file
21403 root 15
0 1249m 303m 10m s 1.3
0.2 49:31.89 >output
21470 root 15
0 1249m 303m 10m s 1.0
0.2 56:24.24 >elasticsearch.
如上例所示,logstash很溫馨地給每類線程都取了名字,輸入的叫<xx,過濾的叫|xx,輸出的叫>xx。
資料線上程之間以事件的形式流傳。不要叫行,因為logstash可以處理多行事件。
logstash會給事件添加一些額外資訊。最重要的就是@timestamp,用來标記事件的發生時間。因為這個字段涉及logstash的内部流轉,是以必須是一個joda對象,如果你嘗試自己給一個字元串字段重命名為@timestamp的話,logstash會直接報錯。是以,請使用logstash-filter-date插件來管理這個特殊字段。
此外,大多數時候,還可以見到另外幾個:
host标記事件發生在哪裡。
type标記事件的唯一類型。
tags标記事件的某方面屬性。這是一個數組,一個事件可以有多個标簽。
你可以随意給事件添加字段或者從事件裡删除字段。事實上事件就是一個ruby對象,或者更簡單地了解為就是一個哈希也行。
每個logstash過濾插件,都會有四個方法叫add_tag、remove_tag、add_field和remove_field,它們在插件過濾比對成功時生效。
推薦閱讀
官網上“the life of an event”文檔:http://logstash.net/docs/1.4.2/life-of-an-event
elastic{on}上《life of a logstash event》演講:https://speakerdeck.com/elastic/life-of-a-logstash-event
![Oracle索引内部結構研究[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)