近期,阿裡雲計劃将旗下機器學習平台正式商業化釋出。說到機器學習可能有些人會比較迷惑,但是提到人工智能,人們馬上就聯想到了刷臉支付、人機智能互動、商品智能推薦等場景,機器學習算法就是助力這些人工智能應用的底層算法。
最近幾年,機器學習發展趨勢火熱,主要是我們在深度學習技術上取得了一定的進展,總結起來應該是三大因素:
資料:網際網路上每天生成海量的資料,有圖像、語音、視訊、還有各類傳感器産生的資料,例如各種定位資訊、穿戴裝置;非結構化的文本資料也是重要的組成部分。資料越多,深度學習越容易得到表現好的模型。
大規模分布式高性能計算能力的提升:這些年來,gpu高性能計算、分布式雲計算等計算平台迅猛發展,讓大規模的資料挖掘和資料模組化成為可能,也為深度學習的飛躍創造了物質基礎;阿裡雲的願景之一就是成為和水電煤一樣的基礎設施。
算法上的創新:随着資料和計算能力的提升,算法本身也有了很大的進展,尤其在深度學習方面,譬如從腦神經學上得到的靈感,在激活函數上進行了稀疏性的處理,等等。
基于上述三點,人工智能又迎來了它的第二個春天。人工智能将以更快的速度進入我們的生産和生活中來,成為我們的眼睛,我們的耳朵,幫助我們更快捷地擷取資訊,輔助我們做出決策。阿裡雲機器學習平台産品也是以而産生,加速疊代過程,助力技術的發展。下面我們對照阿裡雲機器學習平台架構圖對其功能進行介紹:
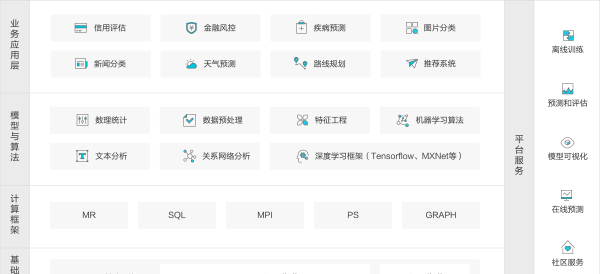
阿裡雲機器學習架構圖
阿裡雲機器學習的平台的基礎設施和計算架構建立在阿裡雲飛天計算平台之上,支援mr、sql、mpi、ps、graph共5種分布式計算架構,對于底層的cpu和gpu計算機群可以靈活地調用。另外,在模型與算法層,阿裡雲機器學習涵蓋了資料預處理、特征工程、機器學習算法、深度學習架構、模型評估和預測等全套資料挖掘流程。

算法流程
在業務應用層,算法開發者可以基于阿裡雲機器學習平台輕松地搭建起例如疾病預測、金融風控、新聞分類等各種場景的應用。
那麼阿裡雲機器學習平台具備哪些關鍵技術特點呢?
<b>2.1人性化的操作界面</b>
機器學習操作界面
阿裡雲機器學習平台讓機器學習不再遠不可及,在平台上沒有繁瑣的公式和複雜的代碼邏輯,使用者看到的是各種分門别類被封裝好的算法元件。在搭架實驗的過程中,隻要拖拽元件就可以快速的拼接成一個workflow。操作體驗類似于搭積木,真正做到讓小白使用者也可以輕松玩轉機器學習。“過去半個月才能搭建的一套資料挖掘實驗,利用阿裡雲機器學習平台3個小時就可能解決”。
同時,平台的每一個實驗步驟都提供可視化的監控頁面,資料挖掘工程師可以實時的掌握模型的訓練情況,可視化的結果評估元件也極高的提升了模型調試效率。 在深度學習黑箱透明化方面,我們也在不斷的研發內建各種可視化的工具,包括開源的tensorboard和自研的工具,為客戶提供更多可參考的資訊,縮短模型優化的過程。
特征評估柱狀圖
<b>2.2豐富的算法元件</b>
阿裡雲機器學習平台部分算法展示
阿裡雲機器學習平台提供100餘種算法元件,涵蓋了分類、回歸、聚類等常用算法場景。另外平台還針對主流的算法應用場景,提供了偏向業務的算法,包含文本分析、關系分析、推薦3種類别。使用者通過阿裡雲機器學習平台提供的算法,幾乎可以解決任何場景的業務問題。特别值得說明的一點是,平台上的算法全部脫胎于阿裡巴巴集團内部的業務實踐,所有算法都經曆過pb級資料和複雜業務場景的錘煉,具備成熟穩定的特點。
算法清單如下(包括所屬類别和具體算法):
<b>資料預處理</b>
權重采樣(weightedsample)
随機采樣(randomsample)
過濾與映射(filterreflect)
分層采樣(stratifiedsample)
join
合并列(appendcolumns)
union
增加序列号(appendid)
稠密轉稀疏 tabletokv
拆分(split)
缺失值填充(fillmissingvalues)
歸一化(normalize)
标準化(standardize)
類型轉換(typeconvert)
<b>特征工程</b>
主成分分析(pca)
特征規範(featurenomalize)
特征離散(featurediscret)
特征異常平滑(featuresoften)
特征尺度變換(featurescaletransform)
随機森林特征重要性評估(randomforestfeatureimportance)
gbdt特征重要性(gbdtfeatureimportance)
線性模型特征重要性(regression_feature_importance)
特征重要性過濾(featurefilter)
過濾式特征選擇(filterfeatureselect)
視窗變量統計(rfm)
特征編碼(featureencoding)
<b>統計分析</b>
百分位(percentile)
全表統計(fulltablesummary)
皮爾森系數(pearsoncoefficient)
直方圖(多字段)(histogram)
離散值特征分析(enumfeaturesaanalysis)
資料視圖(data_view)
協方差(cov) 切問
經驗機率密度圖(pdf)
箱線圖( boxplot)
散點圖(scatter_diagram)
quantile
相關系數矩陣(corrcoef)
卡方拟合性檢驗(chisquare)
卡方獨立性檢驗(chisquare)
單樣本t檢驗(ttest)
雙樣本t檢驗(ttest)
<b>機器學習</b>
線性支援向量機(linearsvm)
邏輯回歸二分類(binarylogisticregression)
gbdt二分類(gbdtbinaryclassification)
k近鄰(knn)
邏輯回歸多分類(logicregressionmulticlassification)
随機森林(randomforest)
樸素貝葉斯(naivebayes)
k均值聚類(kmeans)
線性回歸(linearregression)
gbdt回歸(gbdtregression)
混淆矩陣(confusionmartix)
多分類評估(multiclassificationevaluation)
二分類評估(binaryclassificationevaluation)
回歸模型評估(regressionmodelevaluation)
聚類模型評估(clusterevaluation)
預測(prediction)
<b>文本分析</b>
tf-idf
plda
word2vec
split word
三元組轉kv
字元串相似度
字元串相似度-topn
停用詞過濾
文本摘要(textsummarization)
關鍵詞提取(keywords_extraction)
句子拆分( splitsentences)
ngram-count
語義向量距離(semanticvectordistance)
doc2vec
<b>網絡分析</b>
k-core
單源最短路徑(sssp)
pagerank
标簽傳播聚類(labelpropagationclustering)
标簽傳播分類(labelpropagationclassification)
modularity
最大聯通子圖(maximalconnectedcomponent)
點聚類系數(nodedensity)
邊聚類系數(edgedensity)
計數三角形(trianglecount)
樹深度(treedepth)
<b>2.3提供業内主流深度學習架構</b>
阿裡雲機器學習平台内置業内主流的深度學習架構:tensorflow、mxnet、caffee。
深度學習架構
對于不同的架構提供一緻性的可視化操作環境,使用者隻需要将業務代碼以及訓練資料上傳到oss,即可通過配置路徑完成深度學習網絡模型的訓練。整個計算架構都針對不同的深度學習架構進行了深入的優化,同時也提供了模型的一鍵部署成api的功能,完美解決了模型與業務銜接的問題。
在深度學習架構底層計算資源方面,平台提供了gpu的多卡靈活排程功能,隻需要在界面填寫需要的gpu資源數量,就可以将計算任務下發到對應的分布式計算機群上,免除運維煩惱。
<b>2.4超大規模計算能力</b>
得益于底層的飛天計算引擎,阿裡雲機器學習平台支援超大規模的分布式計算,每日處理pb級的計算任務請求。除了底層強悍的計算資源保證,在分布式計算架構優化方面,阿裡雲機器學習平台也做足工作。以參數伺服器(ps)為例:
參數伺服器
參數伺服器主要思想是:不僅僅是進行資料并行,同時将模型分片,将大的模型分為多個子集,每個參數伺服器隻存一個子集,全部的參數伺服器聚合在一起拼湊成一個完整的模型。該系統主要的創新點在于失敗重試的功能,在分布式系統上,上百個節點協同工作時,經常會出現一個或幾個節點挂掉的情況,如果沒有失敗重試機制,任務就會有一定的幾率失敗,需要重新送出任務到叢集排程。
失敗重試是将每個節點的狀态備份到相鄰(前後)的節點,當個别節點死掉後,重新開機一個新的節點,同時從原節點相鄰的節點擷取所存儲的狀态,理論上可以實作任務的100%完成。還有一個功能是異步疊代,無需等待全部節點完成任務,當大部分節點完成任務時,就可以直接更新對應的模型,這樣可以不需要等待慢機的結果,進而擺脫慢機的影響,提升效率。
<b>2.5線上預測服務能力</b>
在pai平台上,我們提供了豐富的算法實作,由cpu和gpu組成的計算叢集也提供了超強的分布式計算能力,同時我們還提供模型線上預測服務,讓資料與算法和計算能力的結合,可以直接輸出強大的人工智能服務,友善地應用于各行各業。資料驅動下得到的模型,可以一鍵部署到雲端作為一個api的應用服務。可以想見在不久的将來,雲市場上會出現大量的pai平台支撐的資料智能服務,助力萬衆創新的商業化和産業化,直接創造社會價值。
<b>3.1阿裡巴巴集團内部案例</b>
下面介紹在阿裡内部的三個應用場景。
<b>應用一:推薦系統</b>
第一個應用是推薦系統,主要是參數伺服器在推薦系統内的應用。當在淘寶購物時,經查詢顯示的商品一般都是非常個性化的推薦,它是基于商品的資訊和使用者的個人資訊以及行為資訊三者的特征提取。這個過程中形成的特征一般都是很大,在沒有參數伺服器時,采用的是mpi實作方法,mpi中所有的模型都存在于一個節點上,受限于自身實體記憶體上限,它隻能處理2000萬個特征;通過使用參數伺服器,我們可以把更大模型(比如說百億個特征的模型),分散到數十個乃至于上百個參數伺服器上,打破了規模的瓶頸,實作了模型性能上的提升。
<b>應用二:芝麻信用分</b>
第二個應用是芝麻信用分。芝麻信用分是通過個人的資料來評估你個人信用。做芝麻信用分時,我們将個人資訊分成了五大緯度:身份特質、履約能力、信用曆史、朋友圈狀況和個人行為進行評估信用等級。
在去年,我們利用dnn深度學習模型,嘗試做芝麻信用分評分模型。輸入是使用者原始的特征,基于專家知識将上千維的特征分為五部分,每部分對應評分的次元。我們通過一個本地結構化的深度學習網絡,來捕捉相應方面的評分。由于業務對解釋性的需求,我們改變了模型的結構,在最上面的隐層,一共有五個神經原,每個神經原的輸出都對應着它五個次元上面值的變化;再往下一層,是改變次元分數的因子層;用這種本地結構化的方式,維持模型的可解釋性。
<b>應用三:光學文字識别</b>
最後一個應用是圖象上面的光學文字的識别(ocr)。我們主要做強模闆類、證件類的文字識别,以及自然場景下文字的識别。強模闆服務(身份證識别)在數加平台上也提供了相應的入口,目前可以達到身份證單字準确率99.6%以上、整體的準确率93%。在識别中用到的是cnn模型,但其實整個流程特别長,不是深度學習一個模組化就能解決的問題,包括版面分析、文字行的檢測、切割等等技術。在cnn訓練中,我們采用了多機多卡分布式算法産品,之前利用一千萬個圖像訓練cnn模型,大約需要耗時70個小時,疊代速度非常緩慢;采用分布式8卡産品之後,不到十個小時就可以完成模型訓練。目前ocr的服務已經成為了一個受歡迎的阿裡雲市場上的api,尤其是證件類的識别,準确率高,種類齊全,成為了一種可以在商業場景中廣泛使用的資料服務。
<b>3.2外部業務案例</b>
在對外服務方面,阿裡雲機器學習平台已經在金融、地産、教育、醫療、天氣等行業發揮作用——其中比較典型的案例是明源雲在地産行業的應用,明源旗下的雲采購平台利用阿裡雲機器學習平台搭建了一套銷售crm系統,這套系統包含資料的預處理、特征工程、機器學習、評估、預測以及排程。阿裡雲機器學習平台幫助明源精确的定位潛在使用者,提高其銷售份額接近百分之百。去年11月,阿裡雲在cbs大會上,發表了《nonlinear machine learning approach by cloud computing to short-term precipitation forecasting》的報告, 結合廣東省氣象局提供的大規模氣象觀測資料,我們使用阿裡雲機器學習平台對臨近預報(0-3小時内)的降雨量進行模組化預測。無論資料清洗、特征工程,還是非線性機器學習算法訓練以及結果評估,均是由大規模可視化機器學習平台pai來完成開發。最大優勢在于使用者無需掌握過多的底層算法知識,也無需要編寫任何代碼,隻需在pai中拖拽已有的元件即可完成一鍵式的程式運作,以本次廣東省氣象降水預測為例,模組化流程如下圖所示:
利用pai模組化的效果已經優于業界常用的方法,一定程度上再次論證了機器學習在氣象領域,尤其是臨近降雨上的優勢。未來,我們會繼續嘗試引入更多的氣象相關資料到阿裡雲上,比如衛星雲圖,雷達回波等資料,在時間次元上,也會引入更長曆史的資料,充分發揮大資料的作用。同時,在方法創新上,我們會引入更多的模型研究工作,比如多站點的lstm模組化,時間次元上的高斯過程模組化等等。為了鼓勵公衆在天氣預報上的創新,不論是資料,算法,還是應用,阿裡雲未來會籌建氣象app store,友善大家線上貢獻,釋出以及搜尋感興趣的應用。
阿裡雲機器學習平台作為人工智能的載體和源發動力,正在逐漸颠覆各行各業的生産模式。