<b>1. 前言</b>
<b></b>
自2012年deep learning的代表模型alexnet在imagenet大賽中力壓亞軍,以超過10個百分點的絕對優勢奪得頭籌之後,依托于模組化技術的進步、硬體計算能力的提升、優化技術的進步以及海量資料的累積,deep learning在語音、圖像以及文本等多個領域不斷推進,相較于傳統作法取得了顯著的效果提升。
工業界和學術界也先後推出了用于deep learning模組化用途的開源工具和架構,包括caffe、theano、torch、mxnet、tensorflow、chainer、cntk等等。其中mxnet、tensorflow以及cntk均對于訓練過程提供了多機分布式支援,在相當大程度上解放了dl模組化同學的生産力。
但是,dl領域的模組化技術突飛猛進,模型複雜度也不斷增加。從模型的深度來看,以圖像識别領域為例,12年的經典模型alexnet由5個卷積層,3個全連接配接層構成(圖1),在當時看來已經算是比較深的複雜模型,而到了15年,
微軟亞洲研究院則推出了由151個卷積層構成的極深網絡resnet(圖2);從模型的尺寸來看,在機器翻譯領域,即便是僅僅由單層雙向encoder,單層decoder構成的nmt模型(圖3),在阿裡巴巴的一個内部訓練場景下,模型尺寸也達到了3gb左右的規模。
從模型的計算量來看,上面提到的機器翻譯模型在單塊m40 nvidia gpu上,完成一次完整訓練,也需要耗時近三周。deep learning通過設計複雜模型,依托于海量資料的表征能力,進而擷取相較于經典shallow模型更優的模型表現的模組化政策對于底層訓練工具提出了更高的要求。現有的開源工具,往往會在性能上、顯存支援上、生态系統的完善性上存在不同層面的不足,在使用效率上對于普通的算法模組化使用者并不夠友好。阿裡雲推出的pai(platform of artificial intelligence)産品則緻力于通過系統與算法協同優化的方式,來有效解決deep learning訓練工具的使用效率問題,目前pai內建了tensorflow、caffe、mxnet這三款流行的deep learning架構,并針對這幾款架構做了定制化的性能優化支援,以求更好的解決使用者模組化的效率問題。
這些優化目前都已經應用在阿裡巴巴内部的諸多業務場景裡,包括黃圖識别、ocr識别、機器翻譯、智能問答等,這些業務場景下的某些模組化場景會涉及到幾十億條規模的訓練樣本,數gb的模型尺寸,均可以在我們的優化政策下很好地得到支援和滿足。經過内部大規模資料及模型場景的檢測之後,我們也期望将這些能力輸出,更好地賦能給阿裡外部的ai從業人員。
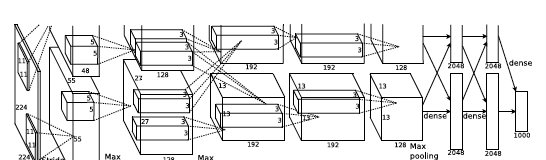
圖1. alexnet模型示例

圖2. 36層的resnet模型示例
圖3. nmt模型架構示例
接下來,本文會扼要介紹一下在pai裡實作的大規模深度學習的優化政策。
<b>2. </b><b>大規模深度學習優化政策在</b><b>pai</b><b>中實踐應用</b><b></b>
大規模深度學習作為一個交叉領域,涉及到分布式計算、作業系統、計算機體系結構、數值優化、機器學習模組化、編譯器技術等多個領域。按照優化的側重點,可以将優化政策劃分為如下幾種:
i. 計算優化
ii. 顯存優化
iii. 通信優化
iv. 性能預估模型
v 軟硬體協同優化
pai平台目前主要集中在顯存優化、通信優化、性能預估模型、軟硬體協同優化這四個優化方向。
1). 顯存優化
記憶體優化主要關心的是gpu顯存優化的議題,在deep learning訓練場景,其計算任務的特點(大量的滿足simd特性的矩陣浮點運算執行序列,控制邏輯通常比較簡單)決定了通常我們會選擇gpu來作為計算裝置,而gpu作為典型的高通量異構計算裝置,其硬體設計限制決定了其顯存資源往往是比較稀缺的,目前在pai平台上提供的中檔m40顯示卡的顯存隻有12gb,而複雜度較高的模型則很容易達到m40顯存的臨界值,比如151層的resnet、阿裡巴巴内部用于中文ocr識别的一款序列模型以及機器翻譯模型。從模組化同學的角度來看,顯存并不應該是他們關心的話題,pai在顯存優化上做了一系列工作,期望能夠解放模組化同學的負擔,讓模組化同學在模型尺寸上獲得更廣闊的模組化探索空間。在記憶體優化方面,
通過引入task-specific的顯存配置設定器以及自動化模型分片架構支援,在很大程度上緩解了模組化任務在顯存消耗方面的限制。其中自動化模型分片架構會根據具體的模型網絡特點,預估出其顯存消耗量,然後對模型進行自動化切片,實作模型并行的支援,在完成自動化模型分片的同時,我們的架構還會考慮到模型分片帶來的通信開銷,通過啟發式的方法在大模型的承載能力和計算效率之間獲得較優的trade-off。
2). 通信優化
大規模深度學習,或者說大規模機器學習領域裡一個永恒的話題就是如何通過多機分布式對訓練任務進行加速。而機器學習訓練任務的多遍疊代式通信的特點,使得經典的map-reduce式的并行資料處理方式并不适合這個場景。對于以單步小批量樣本作為訓練機關步的深度學習訓練任務,這個問題就更突出了。
依據amdahl’s law[19],一個計算任務性能改善的程度取決于可以被改進的部分在整個任務執行時間中所占比例的大小。而深度學習訓練任務的多機分布式往往會引入額外的通信開銷,使得系統内可被提速的比例縮小,相應地束縛了分布式所能帶來的性能加速的收益
。
在pai裡,我們通過pipeline communication、late-multiply、hybrid-parallelism以及heuristic-based model average等多種優化政策對分布式訓練過程中的通信開銷進行了不同程度的優化,并在公開及in-house模型上取得了比較顯著的收斂加速比提升。
在pipeline communication(圖4)裡,通過将待通信資料(模型及梯度)切分成一個個小的資料塊并在多個計算結點之間充分流動起來,可以突破單機網卡的通信帶寬極限,将一定尺度内将通信開銷控制在常量時間複雜度。
圖4. pipeline
communication
在late-multiply裡,針對全連接配接層計算量小,模型尺寸大的特點,我們對于多機之間的梯度彙總邏輯進行了優化,将“多個worker計算本地梯度,在所有結點之間完成資訊互動”(圖5)的分布式邏輯調整為“多個worker将全連接配接層的上下兩層layer的後向傳播梯度及激活值在所有計算結點之間完成資訊互動”(圖6),當全連接配接層所包含的隐層神經元很多時,會帶來比較顯著的性能提升。
圖5. without late-multiply
圖6. with
late-multiply
在hybrid-parallelism裡,針對不同模型網絡的特點,我們引入了資料并行與模型并行的混合政策,針對計算占比高的部分應用資料并行,針對模型通信量大的部分應用模型并行,在多機計算加速與減少通信開銷之間獲得了較好的平衡點。通過圖7,可以看到将這個優化政策應用在tensorflow裡alexnet模型的具體展現。
圖7. alexnet with
hybrid-parallelism
3). 性能預估模型
對于模組化人員來說,他們關心的往往是以最具成本效益的方式完成他們的模組化訓練任務,而不是用多少張卡,以什麼樣的分布式執行政策來完成他們的訓練任務。而目前deep learning訓練工具以及訓練任務的複雜性,使得模組化人員往往不得不透過leaky abstraction的管道,去關心為了完成他們的一個模組化實驗,應該使用多少張gpu卡,多少個 cpu核、什麼樣的通信媒體以及選擇哪種分布式執行政策,才能有效地完成自己的訓練任務。
基于性能預估模型,我們期望能夠将模組化人員從具體的訓練任務執行細節中解放出來。具體來說,給定模組化使用者的一個模型結構,以及所期望花費的費用和時間,pai平台會采用模型+啟發式的政策預估出需要多少硬體資源,使用什麼樣的分布式執行政策可以盡可能逼近使用者的期望。
4). 軟硬體協同優化
上面提到的3個優化政策主要集中在任務的離線訓練環節,而deep learning在具體業務場景的成功應用,除了離線訓練以外,也離不開線上布署環節。作為典型的複雜模型,無論是功耗、計算性能還是模型動态更新的開銷,deep learning模型為線上部署提出了更高的要求和挑戰。在pai平台裡,關于線上部署,我們除了軟體層面的優化之後,也探索了軟硬體協同優化的技術路線。目前在pai平台裡,我們正在基于fpga實作線上inference的軟硬體協同優化。在pai裡實作軟硬體協同優化的政策與業界其他同行的作法會有所不同,我們将這個問題抽象成一個domain-specific的定制硬體編譯優化的問題,通過這種抽象,我們可以采取更為通用的方式來解決一大批問題,進而更為有效地滿足模型多樣性、場景多樣性的需求。
<b>3. </b><b>小結</b>
大規模深度學習優化是一個方興未艾的技術方向
,無論是工業界還是學術界在對這個領域都有着極高的關注度,圍繞這個主題也湧現出若幹個成功的start-up,通過分享這篇文章,我們期望能夠讓pai的終端使用者了解到為了提升使用者提升,改善使用者模組化效率,我們在背後所做出的優化努力。
今年5月份,nvidia gtc 2017北美主場會在矽谷舉行,pai團隊也會在矽谷現場給出一個以大規模深度學習優化為主題的分享。今年7月份,在strats+hadoop world 2017大會上,pai團隊也會做一個相關主題的分享。也希望能夠以這篇文章為引子,以這篇個技術會議為管道,跟國内外更多從事相關領域工作的業界同行有更多交流和碰撞,一起來推進大規模深度學習這個技術方向的進展和建設。
參考文獻
[1]. alex krizhevsky, ilya sutskever, and geoffrey e hinton. imagenet
classification with deep
convolutional neural networks. in advances in neural information processing
systems , pages
1097–1105, 2012.
[2]. kaiming he, xiangyu zhang, shaoqing ren, and jian sun. deep residual
learning for image
recognition. in proceedings of the ieee conference on computer vision and
pattern recognition ,
pages 770–778, 2016.
[3]. geoffrey hinton, li deng, dong yu, george e dahl, abdel-rahman
mohamed, navdeep jaitly,
andrew senior, vincent vanhoucke, patrick nguyen, tara n sainath, et al.
deep neural networks
for acoustic modeling in speech recognition: the shared views of four
research groups.
ieee signal processing magazine , 29(6):82–97, 2012.
[4]. sharan chetlur, cliff woolley, philippe vandermersch, jonathan cohen,
john tran, bryan
catanzaro, and evan shelhamer. cudnn: efficient primitives for deep
learning. arxiv preprint
arxiv:1410.0759 , 2014.
[5]. nitish srivastava, geoffrey e hinton, alex krizhevsky, ilya
sutskever, and ruslan salakhutdinov.
dropout: a simple way to prevent neural networks from overfitting. journal
of machine
learning research , 15(1):1929–1958, 2014.
[6]. george e dahl, tara n sainath, and geoffrey e hinton. improving deep
neural networks
for lvcsr using rectified linear units and dropout. in acoustics, speech
and signal processing
(icassp), 2013 ieee international conference on , pages 8609–8613. ieee,
2013.
[7]. jiquan ngiam, adam coates, ahbik lahiri, bobby prochnow, quoc v le,
and andrew y
ng. on optimization methods for deep learning. in proceedings of the 28th
international
conference on machine learning (icml-11) , pages 265–272, 2011.
[8]. sergey ioffe and christian szegedy. batch normalization: accelerating
deep network training
by reducing internal covariate shift. arxiv preprint arxiv:1502.03167 ,
2015.
[9]. diederik kingma and jimmy ba. adam: a method for stochastic
optimization. arxiv preprint
arxiv:1412.6980 , 2014.
[10]. jimmy lei ba, jamie ryan kiros, and geoffrey e hinton. layer
normalization. arxiv preprint
arxiv:1607.06450 , 2016.
[11]. chun-wei tsai, chin-feng lai, ming-chao chiang, laurence t yang, et
al. data mining for
internet of things: a survey. ieee communications surveys and tutorials ,
16(1):77–97, 2014.
[12]. a hannun, c case, j casper, b catanzaro, g diamos, e elsen, r
prenger, s satheesh, s sengupta, a coates, et al. deepspeech: scaling up
end-to-end speech recognition. 2014. arxiv
preprint arxiv:1412.5567 .
[13]. dario amodei, rishita anubhai, eric battenberg, carl case, jared
casper, bryan catanzaro,
jingdong chen, mike chrzanowski, adam coates, greg diamos, et al. deep
speech 2: endto-
end speech recognition in english and mandarin. arxiv preprint
arxiv:1512.02595 , 2015.
ronan collobert and jason weston. a unified architecture for natural
language processing:
[14]. deep neural networks with multitask learning. in proceedings of the
25th international conference
on machine learning , pages 160–167. acm, 2008.
[15]. yonghui wu, mike schuster, zhifeng chen, quoc v le, mohammad
norouzi, wolfgang
macherey, maxim krikun, yuan cao, qin gao, klaus macherey, et al. google’s
neural machine
translation system: bridging the gap between human and machine
translation. arxiv
preprint arxiv:1609.08144 , 2016.
[16]. ilya sutskever, oriol vinyals, and quoc v le. sequence to sequence
learning with neural
networks. in advances in neural information processing systems , pages
3104–3112, 2014.