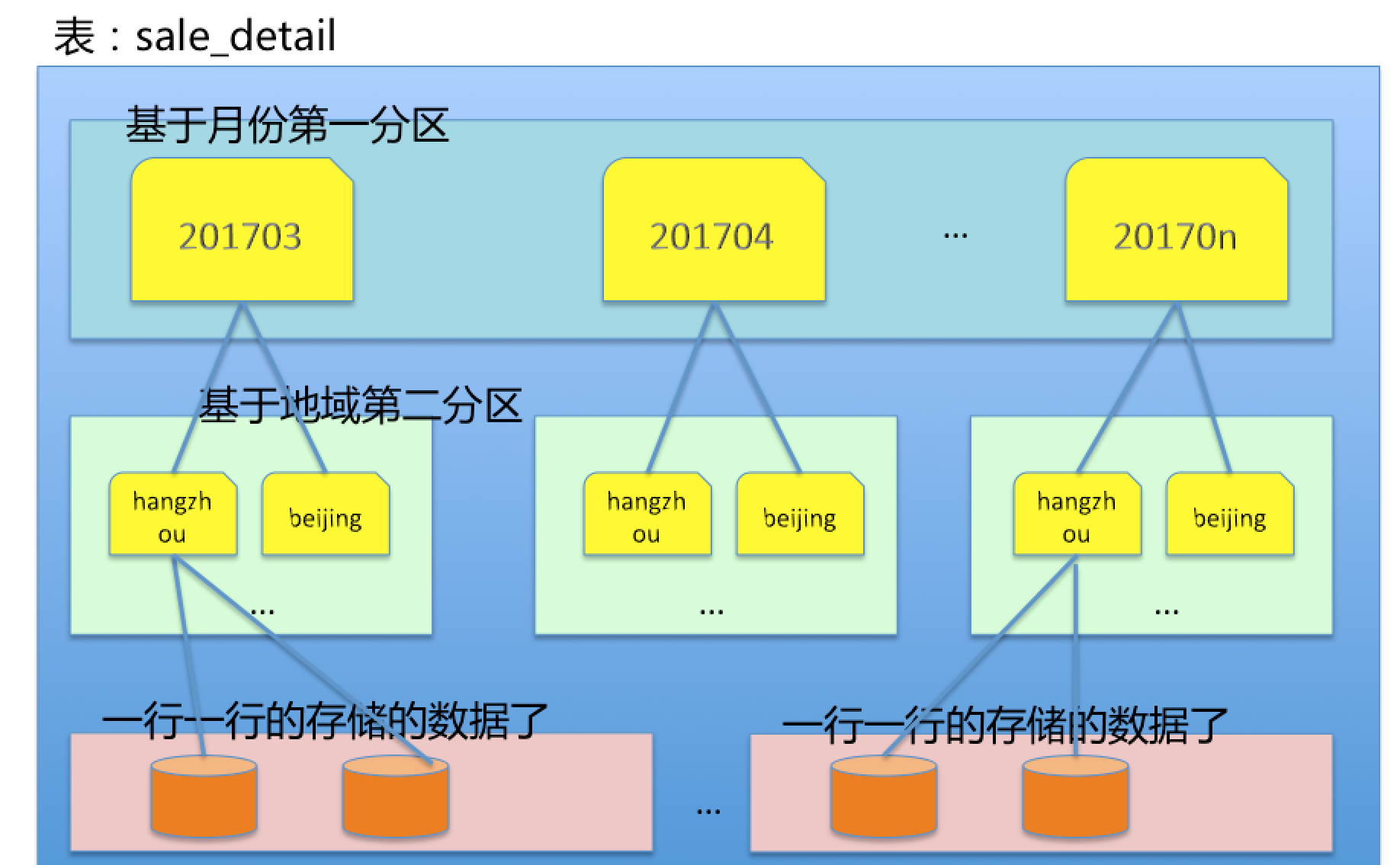
分區字段一般來說都是重複性非常強的字段,比如說時間,某一天可能會産生幾萬條資料,把這一天産生的資料就存入到一個分區中,而時間(某天)就是分區字段,時間(某天)所在的列就是分區列。也就是說,基于分區列的資料作為一個緯度,進行了資料塊的劃分存儲,加快查詢速度。每一個分區塊裡面的資料是完整性的,而不是分區列裡的一列或者幾列資料。在odps中最多支援六級分區。也就是說partition by裡面可以有六個字段可以設定為分區列,而且是有順序的。比如說有兩個分區列,sale_date和region , 那麼這個表可能存在多少個分區呢?可能無數個,分區分為幾級呢,兩級。第一級為銷售時間,第二級為區域。
create table sale_detail(shop_name string, customer_id string , total_price decimal) partition by(sale_date string, region string);
alter table sale_detail add partition (sale_date = ‘201703’, region=’hangzhou’);
其實可以了解更加簡單一些,就是有個叫sale_detail的檔案夾,下面存了一堆201703,201704...的檔案夾,201703這個檔案夾下面又存了一堆hangzhou、beijing、qingdao...的檔案夾,這些檔案夾裡面存的是一條一條的資料,隻不過資料都是基于時間和地域緯度的。想清楚了,就是一層窗戶紙的事情。
![資料庫設計理論及應用(4)——概念結構設計1.概念模型 2.銷售子系統的分E-R圖 3.視圖的內建 4.設計基本E-R圖[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)