本期分享專家:隽勇, 曾就職微軟,擅長網絡、windows相關技術,網絡問題的終結者,現就職阿裡雲專注于彈性計算方面的技術研究,“<b>對技術負責,更對使用者負責</b>”
針對客戶回報的問題,不但要解決,還要總結分析,隽勇針對slb問題進行了分析總結,發現大家遇到的很多負載均衡(簡稱 slb)異常問題都與健康檢查配置相關。不合理的健康檢查政策可能會導緻很多問題出現:
例如:
· 健康檢查間隔設定過長,無法準确發現後端 ecs 出現服務不可用,造成業務中斷。
· 使用 http 模式健康檢查,未合理配置後端,導緻後端日志内容記錄大量健康檢查 head 日志,造成磁盤負載壓力。
如何解決這些問題,為了讓大家走出常見的誤區,隽勇今天帶大家來了解下健康檢查的原理、常見的誤區以及最佳實踐。從此 slb 健康檢查用起來得心應手,再也不用踩坑了。
<b>原理要點</b>
文章重點闡述了如下幾個方面:
· 健康檢查處理過程
· 健康檢查政策配置說明
· 健康檢查機制說明
· 健康檢查狀态切換時間窗
<b>總結要點如下:</b>
<b></b>
1、4層tcp健康檢查通過tcp 3次握手檢查後端 ecs 端口是否監聽。與普通的tcp連接配接使用tcp fin方式銷毀過程不同,健康檢查的連接配接在3次握手建立成功後,以tcp reset方式主動将連接配接斷開。
2、7層健康檢查通過http head 請求檢查指定url路徑的傳回值,如果傳回值與自定義的健康檢查成功傳回值相比對,則判定檢查成功。
3、負載均衡使用 tcp 協定監聽時,健康檢查方式可選 tcp協定 或 http協定。
4、udp協定的健康檢查是通過icmp port unreachable消息來判斷,可能存在服務真實狀态與健康檢查不一緻的問題,我們後續會持續産品改進解決該問題。
5、健康檢查機制的引入,有效提高了承載于負載均衡的業務服務的可用性。但是,為了避免頻繁的健康檢查失敗引發的切換,對系統可用性帶來的沖擊,健康檢查隻有在<b>【連續】</b>多次檢查成功或失敗後,才會進行狀态切換(判定為健康檢查成功或失敗)。
<b>使用誤區</b>
以下是通過客戶問題回報進行的梳理,我們總結的常見健康檢查的了解和使用配置誤區:
<b>誤區1</b> <b>: 懷疑slb健康檢查形成ddos攻擊,導緻伺服器性能下降。</b>
例如,某使用者誤認為slb服務端使用上百台機器進行健康檢查,大量的tcp請求會形成ddos攻擊,造成後端機器性能低下。但實際上,無論是tcp/udp/http協定的健康檢查,其根本無法形成ddos攻擊。
原理上,slb叢集會利用多台機器(假定m個,個位數級别)對後端 ecs 的每個服務監聽端口 (假定n個) ,按照配置的健康檢查間隔(假定o秒,一般建議最少2秒)進行健康檢查。以tcp協定為例,每秒的tcp連接配接建立數為:m*n/o。
是以,健康檢查帶來的每秒tcp并發數,主要取決于建立的監聽端口數量。除非監聽端口達到巨量,否則健康檢查對後端ecs的tcp并發連接配接請求,根本無法達到syn flood的攻擊級别,實際對後端ecs的網絡壓力極低。
<b>誤區2 </b><b>: 使用者為了避免slb健康檢查的影響,将健康檢查間隔設定很長。</b>
該配置會導緻當後端ecs出現異常時,負載均衡需要較長時間才能偵測到後端ecs不可用。尤其當後端ecs間斷不可用時,由于slb需要【連續】檢測失敗時才會移除異常ecs,較長的檢查間隔會導緻負載均衡叢集可能根本無法發現後端ecs不可用。
<b>舉一個實際案例</b>:
<b>背景資訊</b>:
某使用者1個公網負載均衡, 後端有2台ecs對外提供服務,tcp協定的健康檢查間隔設定為50秒。某天使用者做了應用代碼改進後,釋出到1台測試ecs,而後将該ecs加入負載均衡。但是由于應用問題以及不合理的健康檢查的設定,出現了連續2次業務不可用。
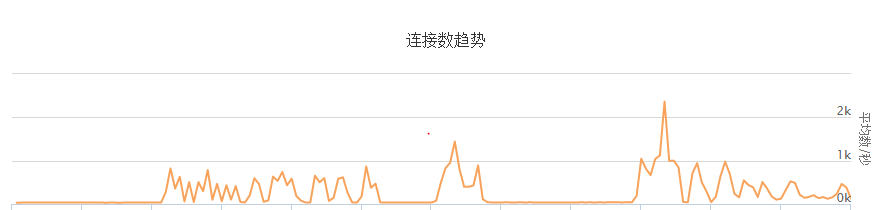
圖示. <b>失敗連接配接數趨勢</b>
上圖"<b>連接配接數趨勢</b>"代表負載均衡失敗連接配接數的變化趨勢。從圖中可以看到,出現了2次負載均衡業務間斷不可用的情況。
階段1: 15:29 - 16:44: 該問題由于應用代碼的原因導緻。
階段2: 17:12起 : 該問題由于單台ecs無法承擔業務量導緻。
<b>如下是複盤的詳細過程</b>:
【15:26】 使用者建立ecs機器(假定名稱i-test), 部署最新的應用代碼,加入負載均衡叢集中。
【15:29】由于新應用代碼的問題,該ecs i-test上線後,負載均衡将業務轉發至該ecs後,其cpu飙升至100%。

圖示. <b>ecs cpu</b>
從前圖"<b>失敗連接配接數趨勢</b>"可以看出,15:30分,負載均衡報出4層tcp轉發失敗的連接配接數開始飙升,原因就是新加入的ecs i-test機器在cpu 100%的情況下,出現業務不可用。而且從15:34分開始,後端的ecs健康檢查日志中開始出現健康檢查失敗的資訊,但是由于使用者設定的間隔為50秒,而後端ecs i-test也不是完全不響應,偶爾的tcp 三次握手健康檢查還可以成功,是以未出現【<b>連續</b>】健康檢查失敗,是以該負載均衡的監聽端口未報出異常狀态。
使用者接到終端客戶回報,業務出現斷續不可用的情況,使用者開始緊急自查。但由于負載均衡狀态未報出異常,使用者将排查集中在應用側。
【16:44】使用者緊急将ecs i-test從負載均衡中下線,更換為老版本的應用。
【16:56】使用者将裝有老版本應用的ecs i-test上線到負載均衡叢集。此時,負載均衡叢集有3個ecs在提供服務,業務恢複正常。從前圖"<b>失敗連接配接數趨勢</b>"中,可以看到失敗的數量降到0。
【17:12】業務恢複後,使用者認為之前問題是由于業務代碼的問題導緻。此時使用者通過将權重設定為0将2台原先的ecs下線,由新上線的那台ecs i-test承擔所有業務。此時,ecs i-test由于業務量陡增,ip conntrack表耗盡,大量建立tcp連接配接失敗。是以看到從17:12分起,負載均衡大量的連接配接建立失敗。由于健康檢查間隔高,我們從負載均衡的日志中看到,該ecs的健康檢查狀态在很長一段時間内保持正常,負載均衡叢集無法及時判斷後端ecs實際狀态,目前端使用者回報後,才發現實際業務影響,導緻業務中斷時間較長。
從該示例可以看出,合理的配置健康檢查間隔對于及時發現業務不可用問題非常重要。
<b>誤區3 : 使用http模式健康檢查,未合理配置後端,導緻後端日志内容記錄大量健康檢查head日志,造成磁盤負載壓力。</b>
我們确實遇到過一例健康檢查配置,導緻後端ecs的性能低下的案例。使用者購買低配(1核1g) ecs,使用7層http健康檢查,健康檢查間隔低,同時配置多個監聽,後端ecs的web服務記錄大量的head請求日志,導緻io占用高,引起性能低下。
<b>最佳實踐</b>
結合負載均衡健康檢查的技術要點和實際中所遇到的使用誤區,我們提供如下最佳實踐:
<b>1、根據業務需要合理選擇tcp 或 http的健康檢查模式。</b>
如果使用http 健康檢查模式,請合理配置後端日志配置,避免健康檢查head請求過多對io的影響。
http健康檢查請不要對根目錄進行檢查,可以配置為對某個html檔案檢查以确認web服務正常。
<b>2、合理配置健康檢查間隔</b>
根據實際業務需求配置健康檢查間隔,避免因為健康檢查間隔過長導緻無法及時發現後端ecs出現問題。具體請參考:
<a href="https://help.aliyun.com/knowledge_detail/39453.html">健康檢查的相關配置,是否有相對合理的推薦值?</a>
<b>3、合理配置負載均衡架構,監聽、虛拟伺服器組合轉發政策。</b>
為滿足使用者的複雜場景需求,目前負載均衡可以配置虛拟伺服器組和轉發政策。詳情請參考文檔:
<a href="https://help.aliyun.com/document_detail/45277.html">如何實作域名 / url 轉發功能</a>
對于虛拟伺服器組、轉發政策,其與監聽對健康檢查并發的影響相同,如下圖:
<b>次元</b>
<b>健康檢查配置</b>
<b>健康檢查目标伺服器</b>
後端伺服器
使用配置監聽時的健康檢查配置
所有後端 ecs
虛拟伺服器組
相應虛拟伺服器組包含的伺服器
轉發政策
建議使用者根據實際業務需求,合理配置監聽、虛拟伺服器組和轉發政策。
a、對于4層tcp協定,由于虛拟伺服器組可以是有後端ecs不同的端口承載業務,是以在配置4層tcp的健康檢查時不要設定檢查端口,而"預設使用後端伺服器的端口進行健康檢查", 否則可能導緻後端ecs健康檢查失敗。
b、對于7層http協定,使用虛拟伺服器組合轉發政策時,確定健康檢查配置政策中的url在後端每台機器上都可以通路成功。
c、避免過多的配置監聽、虛拟伺服器組和轉發政策,以免對後端ecs形成一定的健康檢查壓力。
經過上邊原理、誤區和最佳實踐,是不是有種恍然大悟的感覺,那說明你認真看完了整篇文章。小編給你一個大大的贊。關于slb健康檢查還有哪些想了解的,歡迎留言讨論。本期就到這裡了,我們下期再見。