在雲栖techday第十五期活動上,阿裡雲idst總監初敏博士給大家帶來了題為《資料智能時代的語音互動》的分享,初敏博士認為當今是一個資料驅動的智能時代,語音互動将是這個時代的第一爆發領域,将會形成新一輪入口之争。她主要從語音識别與合成、人機對話、應用案例分析三部分展開了此次分享。
下面是現場分享觀點整理。
自從谷歌的alphago戰勝李世石後,人工智能在全世界範圍内引起了高度關注。細看近年來備受熱議的人工智能案例,實際上是機器學習特别是深度學習技術的發展和普及的結果。而今天的深度學習,跟三四十年前神經網絡技術在原理上其實沒有本質差别,最大的差異就是網絡規模。以前大家隻敢嘗試一個隐含層,今天語音識别中常用的是7、8個隐層,甚至有人嘗試一百多個隐層。以前一個隐層上也就放二三十個節點,今天可以放1024或2048個。我們之是以可以這麼任性地增加網絡規模,并不斷建構出各種複雜的網絡結構,一方面是計算能力的增強,另一方面是可以用來訓練模型的資料規模的增加。是以可以說,近幾年人工智能發展最主要是大資料驅動的機器學習技術的發展。
今天我們所做的學習,其實是在向資料學習;而今天看到的機器智能,大多數是從資料中學來的。是以,現在是一個資料驅動的智能時代。
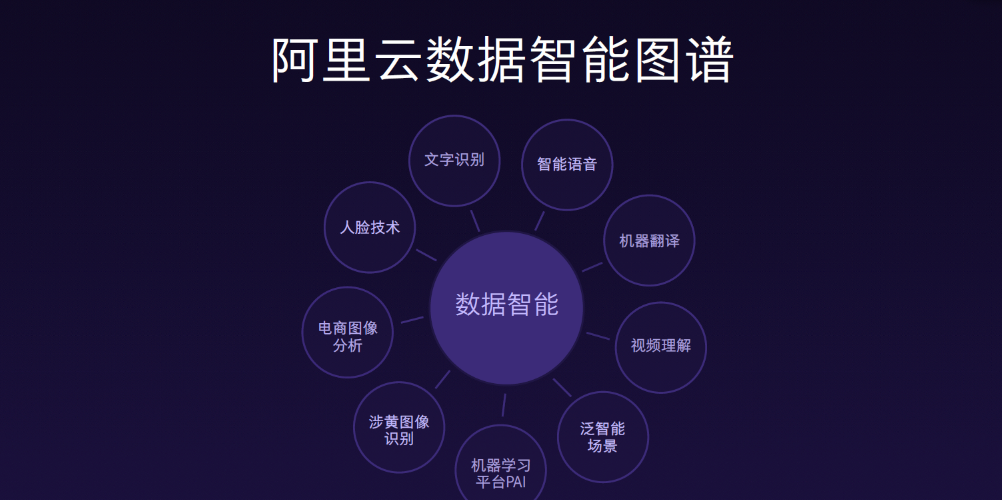
<b>圖一 阿裡雲資料智能圖譜</b><b></b>
阿裡在這個方向上,做了大量的布局,比如文字識别、人臉識别、圖象識别,特别在電商領域做很多圖象的分析。
我們為什麼稱之智能語音呢?這是因為語音不僅僅局限語音識别本身,同時還包括對所得到的文字的真正了解,甚至進一步的互動,這樣才具有真正的智能性,而并非傳統的将語音轉化為文字。語音在人工智能這個圈子裡,可以說是最成熟、最接近應用的領域之一。随着移動網際網路時代的到來,手機、智能家居等裝置呈現小型化、無屏化的趨勢,語音就成為了一個最友善的入口。是以,在這個正在到來的資料智能時代,我們認為語音互動将是第一爆發的領域,将會形成新一輪入口之争。

<b>圖二 阿裡巴巴豐富的應用場景</b><b></b>
到目前為止,阿裡對語音的研發大概隻有一年多的時間。阿裡本身具有很大的客服系統,每天都有幾千個坐席用于電話服務,同時還保留通話錄音。但是這些錄音是無用的資料,因為沒有人來聽它,除了客服團隊會對很小一部分進行服務品質的抽檢調查。而客戶為同一件事再打客服電話時,遇到一個新的服務人員,就又需要重複之前所講過的事情,導緻客戶體驗非常之差。
那麼智能語音可在其中發揮怎樣的作用呢?它能将這些錄音轉化為文字,再通過自然語言的處理加以應用。例如在“質檢”場景中,從文字提取有用資訊,檢測每一通電話是否存在問題。以螞蟻客服為例,原本30多人的質檢團隊隻能抽檢1%的通話。而使用語音智能質檢系統後,隻保留10+人的質檢團隊就做到了100%的質檢。
<b>語音識别與合成</b>
上述講的是目前人工智能整體的大背景,未來所謂的人工智能最核心的是資料驅動的人工智能。在整個過程中,不僅僅是一個算法、深度學習,其中最本質的是要用資料将其驅動起來,才能獲得真正的智能。
我們目前所做的工作,主要集中在語音和人機互動兩個方面,一部分是基礎的語音識别、合成;另一部分是人機間的互動對話。首先介紹的是我們在語音識别方面的工作。
<b>圖三 語音識别的基本原理</b><b></b>
如果将語音識别系統看成一個黑箱過程的話,那麼它的作用就是把語音轉換為文字的過程。從大體的原理上來講的話,語音識别解碼器最大後驗決策的過程,給出一個語音的特征序列x,找出後驗機率最大的一個文本串w。實際實施的時候,通過貝葉斯公式的分解成為兩個模型,一個是聲學模型,它的功能就是評估你的發音是什麼,比如是發的是 b/p/m/f,還是d/t/n/l。 目前是使用深度神經網模型來完成;另一個是語言模型,這一部分則是評估哪一個文字串是更自然的語言。一般是用ngram模型,目前大家也在探索各種深度學習模型。另外還會用到發音詞典這個資源。
其中擷取聲學模型和語言模型的過程稱為模型訓練過程。執行最大後驗機率決策的過程成為語音識别解碼過程。,
<b>圖四 聲學模組化</b><b></b>
人的發音實際上是聲帶振動,通過振動産生周期性的波;聲道相當于一個截面積不斷變化的管子,不同形狀的管子具有不同的共振頻率,我們稱之為共振峰,共振峰不同所發出的音就不同。 所謂的聲學模型就是基于這類特征進行模組化,比如說/a/和/i/的共振峰差異就很明顯。最小的模組化機關稱之為音素(/a/、/i/、/u/、/z/、/c/、/sh/等)。在中文和英文中,最小機關是不同的,中文通常會大一些。
傳統上比較流行的模組化方式是采用馬爾科夫鍊來描述一個音,包含不同的狀态。但經過二三十年的發展,已經達到了盡頭,每次優化的效果錯誤率下降僅僅相對8%-10%左右。在2011年,微軟鄧力、餘棟等在大規模連續語音識别任務上成功的應用的dnn深度學習模型。它是把這個語譜圖灌進去,在馬爾科夫鍊的基礎上,再用深度學習訓練,可實作30%相對錯誤率的下降。在此基礎上,語音識别就逐漸變得可用起來,是以可以說深度學習最初的成功是在語音識别方面的,這是因為語音識别是一個非常好的封閉學習系統,學習目标是非常清楚的。
剛才所講的是一個簡單的dnn的模型。随着深度學習的發展,人們逐漸在模型的拓撲結構上做文章。lstm是一個rnn模型,通過設定門的開關有選擇地實作記憶與遺忘。另外一種是blstm,其在進行目前判決時不僅考慮曆史資料,還會等待後面的資料進來後一起用來做判決。是以準确率會大大提高,相比于dnn模型,又可以實作錯誤率25%左右的相對下降。但是它帶來的問題是:因為要在收到右邊的内容後才能完成現在的判決,在時間上,就會形成判決的延遲。是以我們目前做的是長度受限(lc)blstm,兼顧準确性和時效性。該模型計算複雜度比較高,應用的難度在于時效性。我們在這個方面做了很多優化工作,最終使得這個算法可以達到0.6倍的實時,并完成第一個工業界生産系統的部署。如今,這個系統已經成為阿裡雲雲栖大會的标配(提供實時語音字幕)。
<b>圖五 語言模型</b><b></b>
關于語言模型,它本質就是描述句子出現的機率。通常符合人說話規律的句子的機率會高于随機詞組組合而成的語句。過去流行的模型是n-gram模型,現在仍然是主流模型之一。但是目前的研究熱點是rnn模型。從套路上講,語音識别在過去的二三十年内并沒有發生太大的變化。真正的變化在于深度學習本身。
<b>圖六 資料規模和計算效率至關重要</b><b></b>
在今天會議現場,大家可能注意到在我講話的時候,可以實時産生滾動字幕,這就是我們的小ai語音識别系統。小ai的這項能力,今年3月首次在内部亮相,當時小ai參加了阿裡雲年會,并當場跟中國速記第一人姜毅進行了pk。最終,小ai以微弱優勢勝出。
我們是春節前接到要在阿裡雲年會上進行人機pk的任務,包含春節假期一共不到一個月的準備時間。為了取得最好的效果,我們決定采用blstm模型,是深度學習中一個比較複雜但學習能力更強的模型。這個模型當時還在研發階段。是以大家兵分兩路:一路同學利用我們已經采集到的1萬多小時手機語音,做各種實驗,來确定模型的最佳結構和參數,這就意味在數十塊gpu卡上,并行進行好幾組實驗。兩三周的時間這個模型小組完成了幾十組對比實驗。與此同時,另一路同學在集團内外到處收集各種演講資料,在網上收集關于雲計算、大資料領域的各種新聞和文章。這些資料的目的是幫助小ai适應垂直領域演講。
剛才講的是語音識别大的架構,如果說難是非常難。因為必須把每一個細節都十分完美地解決,最後才能得到特别好的效果。但整體來看,并沒有特别神奇的點,僅僅是在不同的深度學習的模型上進行調試,重要的地方就是疊代能力和資料量的大小。是以資料的采集和使用就變得尤為重要,是以機器學習遠遠不是隻研究某個算法,對企業而言,真正好用的資料模型一定是經過大量的資料驗證的。
對于語音合成的前端處理,之前比較流行的是用crf算法來預測停頓邊界和等級,現在大家更多的嘗試使用機器學習來解決這個問題。聲音合成部分目前存在兩種方法,一種是參數合成;另一種是波形拼接合成。
<b>人機對話</b><b></b>
剛才所講的是語音的識别與合成,但這相對于今天所說的智能語音而言是遠遠不夠的,這是因為我們希望在識别過程中能夠進行了解,可以進行人機對話、互動。
<b>圖七 人機對話的發展趨勢</b><b></b>
從上圖可以看到,人機對話分為口語了解+單輪查詢、多輪對話、開發者平台+定制互動流程三個階段。其中各階段最為核心的在于自然語言的了解,例如在“訂一張上海飛北京的頭等艙,下午5點出發,國航的”語句中,通過分類器将場景中最為重要的參數提取出來,然後用到火車票的資料服務去取結果并傳回給使用者。但使用者往往不能在一句話中把所有的資訊都提供出來。那麼就需要通過多輪對話明确使用者意圖,一般是分為兩個階段:第一階段,通過對話得到結構化查詢;第二階段,将查詢的結果通過自然語言回報給使用者。
<b>圖八 自助服務機器人</b><b></b>
在問答場景中,需要準确找到使用者問題的對應答案。通過問答引擎後,又分為三種形式:基于知識庫的問答、基于知識圖譜的問答、開放式聊天。每個企業都肯能使用者自己的faq或者知識庫或知識圖譜,資料來源可以是企業内部資料庫或網際網路資料。
<b>圖九 賦能生态圈</b><b></b>
剛才所講的這些技術點,阿裡目前也正在做。我們希望能夠自行搭建最核心的基礎平台,然後提供給開發者用于定制化開發。是以我們會做底層核心技術的研發,在此之上提供了一些定制工具。通過使用者上傳資料或者典型的資料,對應的在使用者所處的環境内進行優化。
在用戶端,因為語音是比較複雜的,因為它必須有個資料采集端(錄音口),這一點尤為重要,如果錄音出了差錯,那之後的工作基本就等于白費了。是以一般選用麥克風矩陣進行采樣,在噪聲較大的環境中還需要降噪處理,以保證錄音的品質。
今天我們通過阿裡雲數加平台釋出了一部分成果,包含技術文檔、sdk等等,感興趣的聽衆可以去自行檢視。
<b>應用案例分析</b><b></b>
剛才更多講的是技術,下面我分享幾個具體的案例。
<b>圖十 語音識别助力行業變革</b><b></b>
我們和螞蟻客服有着深度合作。在雙11當天大概有500萬使用者的查詢,實際上94%都是自動解決的,隻有6%是通過人工解決。這背後采用了大量的人工智能的技術,如上圖顯示的“安娜”。這是一個自動問答機器人,不僅可以回答你詢問的問題,而且會根據你的曆史行為進行提早預測你可能遇到的問題并給出建議。
另外一個工作就是:在客服電話時,使用者可以通過語音來表述自己的問題,通過智能語音識别和互動轉接到對應的客服上,免去了傳統的不停跟随提示按鍵的步驟,縮短了服務過程。
<b>圖十一</b><b> </b><b>yunos手機中的個人助理</b><b></b>
另外一個是在yunos手機中的個人助理,其中包含了二十幾個領域的資訊,還包括一些可執行指令,例如設鬧鐘、發短信、打電話等。後續還會加入人性化的功能。
<b>圖十二 阿裡小蜜</b><b></b>
最後一個案例是阿裡集團客服的合作——手機淘寶中的阿裡小蜜,它通過語音的互動實作售前、售中、售後的打通,全方位的為消費者服務。
<b>總結</b><b></b>
智能語音可以有很多創新的用法。在未來的幾年内,智能語音一定會非常快地普及和推廣開,并且應用于各類場景。
<b>關于分享者</b>
初敏博士,阿裡雲idst總監