ZooKeeper簡介
ZooKeeper是一個開放源碼的分布式應用程式協調服務,它包含一個簡單的原語集,分布式應用程式可以基于它實作同步服務,配置維護和命名服務等。
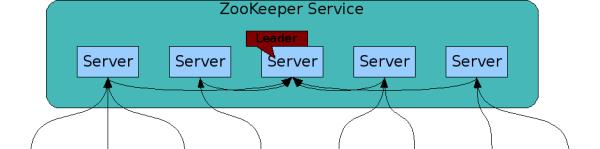
ZooKeeper設計目的
1.最終一緻性:client不論連接配接到哪個Server,展示給它都是同一個視圖,這是zookeeper最重要的性能。
2.可靠性:具有簡單、健壯、良好的性能,如果消息m被到一台伺服器接受,那麼它将被所有的伺服器接受。
3.實時性:Zookeeper保證用戶端将在一個時間間隔範圍内獲得伺服器的更新資訊,或者伺服器失效的資訊。但由于網絡延時等原因,Zookeeper不能保證兩個用戶端能同時得到剛更新的資料,如果需要最新資料,應該在讀資料之前調用sync()接口。
4.等待無關(wait-free):慢的或者失效的client不得幹預快速的client的請求,使得每個client都能有效的等待。
5.原子性:更新隻能成功或者失敗,沒有中間狀态。
6.順序性:包括全局有序和偏序兩種:全局有序是指如果在一台伺服器上消息a在消息b前釋出,則在所有Server上消息a都将在消息b前被釋出;偏序是指如果一個消息b在消息a後被同一個發送者釋出,a必将排在b前面。
ZooKeeper資料模型
Zookeeper會維護一個具有層次關系的資料結構,它非常類似于一個标準的檔案系統,如圖所示:

Zookeeper這種資料結構有如下這些特點:
1)每個子目錄項如NameService都被稱作為znode,這個znode是被它所在的路徑唯一辨別,如Server1這個znode的辨別為/NameService/Server1。
2)znode可以有子節點目錄,并且每個znode可以存儲資料,注意EPHEMERAL(臨時的)類型的目錄節點不能有子節點目錄。
3)znode是有版本的(version),每個znode中存儲的資料可以有多個版本,也就是一個通路路徑中可以存儲多份資料,version号自動增加。
4)znode的類型:
Persistent 節點,一旦被建立,便不會意外丢失,即使伺服器全部重新開機也依然存在。每個 Persist 節點即可包含資料,也可包含子節點。
Ephemeral 節點,在建立它的用戶端與伺服器間的 Session 結束時自動被删除。伺服器重新開機會導緻 Session 結束,是以 Ephemeral 類型的 znode 此時也會自動删除。
Non-sequence 節點,多個用戶端同時建立同一 Non-sequence 節點時,隻有一個可建立成功,其它勻失敗。并且建立出的節點名稱與建立時指定的節點名完全一樣。
Sequence 節點,建立出的節點名在指定的名稱之後帶有10位10進制數的序号。多個用戶端建立同一名稱的節點時,都能建立成功,隻是序号不同。
5)znode可以被監控,包括這個目錄節點中存儲的資料的修改,子節點目錄的變化等,一旦變化可以通知設定監控的用戶端,這個是Zookeeper的核心特性,Zookeeper的很多功能都是基于這個特性實作的。
6)ZXID:每次對Zookeeper的狀态的改變都會産生一個zxid(ZooKeeper Transaction Id),zxid是全局有序的,如果zxid1小于zxid2,則zxid1在zxid2之前發生。
ZooKeeper Session
Client和Zookeeper叢集建立連接配接,整個session狀态變化如圖所示:
如果Client因為Timeout和Zookeeper Server失去連接配接,client處在CONNECTING狀态,會自動嘗試再去連接配接Server,如果在session有效期内再次成功連接配接到某個Server,則回到CONNECTED狀态。
注意:如果因為網絡狀态不好,client和Server失去聯系,client會停留在目前狀态,會嘗試主動再次連接配接Zookeeper Server。client不能宣稱自己的session expired,session expired是由Zookeeper Server來決定的,client可以選擇自己主動關閉session。
ZooKeeper Watch
Zookeeper watch是一種監聽通知機制。Zookeeper所有的讀操作getData(), getChildren()和 exists()都可以設定監視(watch),監視事件可以了解為一次性的觸發器,官方定義如下: a watch event is one-time trigger, sent to the client that set the watch, whichoccurs when the data for which the watch was set changes。Watch的三個關鍵點:
*(一次性觸發)One-time trigger
當設定監視的資料發生改變時,該監視事件會被發送到用戶端,例如,如果用戶端調用了getData("/znode1", true) 并且稍後 /znode1 節點上的資料發生了改變或者被删除了,用戶端将會擷取到 /znode1 發生變化的監視事件,而如果 /znode1 再一次發生了變化,除非用戶端再次對/znode1 設定監視,否則用戶端不會收到事件通知。
*(發送至用戶端)Sent to the client
Zookeeper用戶端和服務端是通過 socket 進行通信的,由于網絡存在故障,是以監視事件很有可能不會成功地到達用戶端,監視事件是異步發送至監視者的,Zookeeper 本身提供了順序保證(ordering guarantee):即用戶端隻有首先看到了監視事件後,才會感覺到它所設定監視的znode發生了變化(a client will never see a change for which it has set a watch until it first sees the watch event)。網絡延遲或者其他因素可能導緻不同的用戶端在不同的時刻感覺某一監視事件,但是不同的用戶端所看到的一切具有一緻的順序。
*(被設定 watch 的資料)The data for which the watch was set
這意味着znode節點本身具有不同的改變方式。你也可以想象 Zookeeper 維護了兩條監視連結清單:資料監視和子節點監視(data watches and child watches) getData() 和exists()設定資料監視,getChildren()設定子節點監視。或者你也可以想象 Zookeeper 設定的不同監視傳回不同的資料,getData() 和 exists() 傳回znode節點的相關資訊,而getChildren() 傳回子節點清單。是以,setData() 會觸發設定在某一節點上所設定的資料監視(假定資料設定成功),而一次成功的create() 操作則會出發目前節點上所設定的資料監視以及父節點的子節點監視。一次成功的 delete操作将會觸發目前節點的資料監視和子節點監視事件,同時也會觸發該節點父節點的child watch。
Zookeeper 中的監視是輕量級的,是以容易設定、維護和分發。當用戶端與 Zookeeper 伺服器失去聯系時,用戶端并不會收到監視事件的通知,隻有當用戶端重新連接配接後,若在必要的情況下,以前注冊的監視會重新被注冊并觸發,對于開發人員來說這通常是透明的。隻有一種情況會導緻監視事件的丢失,即:通過exists()設定了某個znode節點的監視,但是如果某個用戶端在此znode節點被建立和删除的時間間隔内與zookeeper伺服器失去了聯系,該用戶端即使稍後重新連接配接 zookeeper伺服器後也得不到事件通知。
Consistency Guarantees
Zookeeper是一個高效的、可擴充的服務,read和write操作都被設計為快速的,read比write操作更快。
順序一緻性(Sequential Consistency):從一個用戶端來的更新請求會被順序執行。
原子性(Atomicity):更新要麼成功要麼失敗,沒有部分成功的情況。
唯一的系統鏡像(Single System Image):無論用戶端連接配接到哪個Server,看到系統鏡像是一緻的。
可靠性(Reliability):更新一旦有效,持續有效,直到被覆寫。
時間線(Timeliness):保證在一定的時間内各個用戶端看到的系統資訊是一緻的。
ZooKeeper的工作原理
在zookeeper的叢集中,各個節點共有下面3種角色和4種狀态:
角色:leader,follower,observer
狀态:leading,following,observing,looking
Zookeeper的核心是原子廣播,這個機制保證了各個Server之間的同步。實作這個機制的協定叫做Zab協定(ZooKeeper Atomic Broadcast protocol)。Zab協定有兩種模式,它們分别是恢複模式(Recovery選主)和廣播模式(Broadcast同步)。當服務啟動或者在上司者崩潰後,Zab就進入了恢複模式,當上司者被選舉出來,且大多數Server完成了和leader的狀态同步以後,恢複模式就結束了。狀态同步保證了leader和Server具有相同的系統狀态。
為了保證事務的順序一緻性,zookeeper采用了遞增的事務id号(zxid)來辨別事務。所有的提議(proposal)都在被提出的時候加上了zxid。實作中zxid是一個64位的數字,它高32位是epoch用來辨別leader關系是否改變,每次一個leader被選出來,它都會有一個新的epoch,辨別目前屬于那個leader的統治時期。低32位用于遞增計數。
每個Server在工作過程中有4種狀态:
LOOKING:目前Server不知道leader是誰,正在搜尋。
LEADING:目前Server即為選舉出來的leader。
FOLLOWING:leader已經選舉出來,目前Server與之同步。
OBSERVING:observer的行為在大多數情況下與follower完全一緻,但是他們不參加選舉和投票,而僅僅接受(observing)選舉和投票的結果。
Leader Election
當leader崩潰或者leader失去大多數的follower,這時候zk進入恢複模式,恢複模式需要重新選舉出一個新的leader,讓所有的Server都恢複到一個正确的狀态。Zk的選舉算法有兩種:一種是基于basic paxos實作的,另外一種是基于fast paxos算法實作的。系統預設的選舉算法為fast paxos。先介紹basic paxos流程:
1.選舉線程由目前Server發起選舉的線程擔任,其主要功能是對投票結果進行統計,并選出推薦的Server;
2.選舉線程首先向所有Server發起一次詢問(包括自己);
3.選舉線程收到回複後,驗證是否是自己發起的詢問(驗證zxid是否一緻),然後擷取對方的id(myid),并存儲到目前詢問對象清單中,最後擷取對方提議的leader相關資訊(id,zxid),并将這些資訊存儲到當次選舉的投票記錄表中;
4.收到所有Server回複以後,就計算出zxid最大的那個Server,并将這個Server相關資訊設定成下一次要投票的Server;
5.線程将目前zxid最大的Server設定為目前Server要推薦的Leader,如果此時獲勝的Server獲得n/2 + 1的Server票數,設定目前推薦的leader為獲勝的Server,将根據獲勝的Server相關資訊設定自己的狀态,否則,繼續這個過程,直到leader被選舉出來。
通過流程分析我們可以得出:要使Leader獲得多數Server的支援,則Server總數必須是奇數2n+1,且存活的Server的數目不得少于n+1.
每個Server啟動後都會重複以上流程。在恢複模式下,如果是剛從崩潰狀态恢複的或者剛啟動的server還會從磁盤快照中恢複資料和會話資訊,zk會記錄事務日志并定期進行快照,友善在恢複時進行狀态恢複。
fast paxos流程是在選舉過程中,某Server首先向所有Server提議自己要成為leader,當其它Server收到提議以後,解決epoch和zxid的沖突,并接受對方的提議,然後向對方發送接受提議完成的消息,重複這個流程,最後一定能選舉出Leader。
Leader工作流程
Leader主要有三個功能:
1.恢複資料;
2.維持與follower的心跳,接收follower請求并判斷follower的請求消息類型;
3.follower的消息類型主要有PING消息、REQUEST消息、ACK消息、REVALIDATE消息,根據不同的消息類型,進行不同的處理。
PING消息是指follower的心跳資訊;REQUEST消息是follower發送的提議資訊,包括寫請求及同步請求;
ACK消息是follower的對提議的回複,超過半數的follower通過,則commit該提議;
REVALIDATE消息是用來延長SESSION有效時間。
Follower工作流程
Follower主要有四個功能:
1. 向Leader發送請求(PING消息、REQUEST消息、ACK消息、REVALIDATE消息);
2.接收Leader消息并進行處理;
3.接收Client的請求,如果為寫請求,發送給Leader進行投票;
4.傳回Client結果。
Follower的消息循環處理如下幾種來自Leader的消息:
1.PING消息:心跳消息
2.PROPOSAL消息:Leader發起的提案,要求Follower投票
3.COMMIT消息:伺服器端最新一次提案的資訊
4.UPTODATE消息:表明同步完成
5.REVALIDATE消息:根據Leader的REVALIDATE結果,關閉待revalidate的session還是允許其接受消息
6.SYNC消息:傳回SYNC結果到用戶端,這個消息最初由用戶端發起,用來強制得到最新的更新。
Zab: Broadcasting State Updates
Zookeeper Server接收到一次request,如果是follower,會轉發給leader,Leader執行請求并通過Transaction的形式廣播這次執行。Zookeeper叢集如何決定一個Transaction是否被commit執行?通過“兩段送出協定”(a two-phase commit):
Leader給所有的follower發送一個PROPOSAL消息。
一個follower接收到這次PROPOSAL消息,寫到磁盤,發送給leader一個ACK消息,告知已經收到。
當Leader收到法定人數(quorum)的follower的ACK時候,發送commit消息執行。
Zab協定保證:
1.如果leader以T1和T2的順序廣播,那麼所有的Server必須先執行T1,再執行T2。
2.如果任意一個Server以T1、T2的順序commit執行,其他所有的Server也必須以T1、T2的順序執行。
“兩段送出協定”最大的問題是如果Leader發送了PROPOSAL消息後crash或暫時失去連接配接,會導緻整個叢集處在一種不确定的狀态(follower不知道該放棄這次送出還是執行送出)。Zookeeper這時會選出新的leader,請求處理也會移到新的leader上,不同的leader由不同的epoch辨別。切換Leader時,需要解決下面兩個問題:
1. Never forget delivered messages
Leader在COMMIT投遞到任何一台follower之前crash,隻有它自己commit了。新Leader必須保證這個事務也必須commit。
2. Let go of messages that are skipped
Leader産生某個proposal,但是在crash之前,沒有follower看到這個proposal。該server恢複時,必須丢棄這個proposal。
Zookeeper會盡量保證不會同時有2個活動的Leader,因為2個不同的Leader會導緻叢集處在一種不一緻的狀态,是以Zab協定同時保證:
1)在新的leader廣播Transaction之前,先前Leader commit的Transaction都會先執行。
2)在任意時刻,都不會有2個Server同時有法定人數(quorum)的支援者。
這裡的quorum是一半以上的Server數目,确切的說是有投票權力的Server(不包括Observer)。
ZooKeeper的讀寫流程
來詳細看下ZooKeeper的讀寫流程,以及ZooKeeper在并發情況下的讀寫控制。以求對ZooKeeper有進一步的了解。
1)讀流程分析
讀流程如下圖所示:
因為ZooKeeper叢集中所有的server節點都擁有相同的資料,是以讀的時候可以在任意一台server節點上,用戶端連接配接到叢集中某一節點,讀請求,然後直接傳回。當然因為ZooKeeper協定的原因(一半以上的server節點都成功寫入了資料,這次寫請求便算是成功),讀資料的時候可能會讀到資料不是最新的server節點,是以比較推薦使用watch機制,在資料改變時,及時感應到。
2)寫流程分析
寫流程如下圖所示:
當一個用戶端進行寫資料請求時,會指定ZooKeeper叢集中的一個server節點,如果該節點為Follower,則該節點會把寫請求轉發給Leader,Leader通過内部的協定進行原子廣播,直到一半以上的server節點都成功寫入了資料,這次寫請求便算是成功,然後Leader便會通知相應Follower節點寫請求成功,該節點向client傳回寫入成功響應。
ZooKeeper并發讀寫情況分析
我們已經知道ZooKeeper的資料模型是層次型,類似檔案系統,不過ZooKeeper的設計目标定位是簡單、高可靠、高吞吐、低延遲的記憶體型存儲系統,是以它的value不像檔案系統那樣适合儲存大的值,官方建議儲存的value大小要小于1M,key為路徑。
ZooKeeper的層次模型是通過ConcurrentHashMap實作的,key為path,value為DataNode,DataNode儲存了znode中的value、children、 stat等資訊。而ConcurrentHashMap是線程安全的Hash Table,它采用了鎖分段技術來減少鎖競争,提高性能的同時又保證了并發安全。
對于ZooKeeper來講,ZooKeeper的寫請求由Leader處理,Leader能夠保證并發寫入的有序性,即同一時刻,隻有一個寫操作被準許,然後對該寫操作進行全局編号,最後進行原子廣播寫入,是以ZooKeeper的并發寫請求是順序處理的,而底層又是用了ConcurrentHashMap,理所當然寫請求是線程安全的。而對于并發讀請求,同理,因為用了ConcurrentHashMap,當然也是線程安全的了。總結來說,ZooKeeper的并發讀寫是線程安全的。
但是對于ZooKeeper的用戶端來講,如果使用了watch機制,在進行了讀請求但是watch znode前這段時間中,如果znode的資料變化了,用戶端是無法感覺到的,這段時間用戶端的資料就有一定的滞後性了,隻有當下次資料變化後,用戶端才能感覺到,是以對于用戶端來說,資料是最終一緻性。
zookeeper叢集
zookeeper叢集配置:
分别在每個伺服器/home/zookeeper-3.4.14下建立myid檔案,内容如下:
日志配置:
啟停:bin/zkServer.sh start/stop/status
zk client指令:bin/zkCli.sh -server localhost:2181
總結
簡單介紹了Zookeeper的基本原理,資料模型,Session,Watch機制,一緻性保證,Leader Election,Leader和Follower的工作流程和Zab協定。
參考:
http://zookeeper.apache.org/doc/trunk/zookeeperOver.html
https://www.jianshu.com/p/d01b1913cced
http://www.ibm.com/developerworks/cn/opensource/os-cn-zookeeper/index.html
《ZooKeeper—Distributed Process Coordination》 by FlavioJunqueira and Benjamin Reed
《ZooKeeper的一緻性算法賞析》https://my.oschina.net/pingpangkuangmo/blog/778927
作者:阿凡盧
出處:http://www.cnblogs.com/luxiaoxun/
本文版權歸作者所有,歡迎轉載,但未經作者同意必須保留此段聲明,且在文章頁面明顯位置給出原文連接配接,否則保留追究法律責任的權利。