最近在給glog做性能優化, 使用c++版本 glog-0.3.4做壓測,測試資料總量為1.5g, 起12個線程循環寫133個位元組的日志條目,測試結果耗時175s,每秒大約8-9mb的吞吐量。
在此測試基礎上,我對glog進行了一系列的性能優化,優化後耗時16s,性能為glog原生版本的10倍。
檢視glog源碼,在擷取日期的時候使用了localtime, localtime_r這兩個函數,而這兩個函數調用了__tz_convert, __tz_convert有tzset_lock全局鎖,每次擷取時間都會使用到kernel級别的futex鎖,是以優化第一步是去掉glibc的localtime函數,使用getimeofday擷取秒數和時區,用純耗cpu的方式算出日期,稍微複雜一點的計算就是閏年閏月的轉換。将這段函數替換後,耗時從175s減少成46s,性能瞬間提高4-5倍。
再翻看glog的源碼,glog是一個多線程同步寫的操作,簡化代碼就是 lock();dosomething();fwrite();unlock(); fwrite本身就是線程安全的,縮小鎖粒度需要改成lock();dosomething();unlock();fwrite(); 其他變量都比較好處理,比如檔案名之類的,不好處理的是輪轉的時候會更改fd, fwrite()會使用到fd。我使用了指針托管和引用計數的辦法,當輪轉檔案時,将current_fd_ 指派給old_fd_, 不直接delete或fclose, 簡化代碼等于:lock();dosomething();if(true) old_fd_ = current_fd_; currnt_fd_.incr();unlock();fwrite();currnt_fd_.decr(); 當old_fd_ = 0時,才會真正delete 和fclose 這個fd指針。優化後壓測耗時30s。
從第二次優化來看。鎖熱點已經很少了,性能也有不少提升,已經能滿足ocs的需求,但是這種多線程同步堵塞寫io的模式,一旦出現io hang住的情況,所有worker線程都會堵住。可以看下__io_fwrite 這個函數,在寫之前會進行__io_acquire_lock() 鎖住,寫完後解鎖。
為了避免所有線程卡住的情況,需要将多線程同步堵塞轉換成單線程異步的io操作,同時避免引入新的鎖消耗性能,是以引入無鎖隊列,算法複雜度為o(1),結構如圖所示:
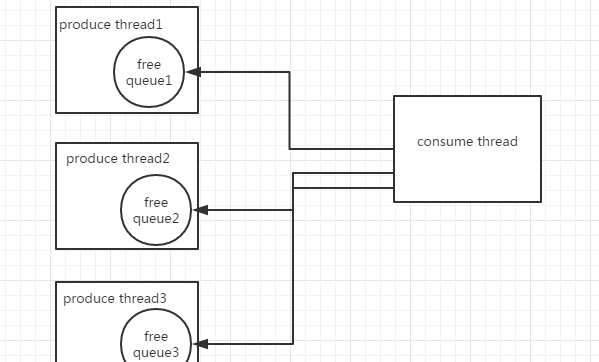
每個生産者線程都有獨自的無鎖隊列,生産者線程做日志的序列化處理等,整個glog有一個單線程的消費線程,消費線程隻處理真正的io請求,無鎖隊列使用環形數組實作,引入tcmalloc做記憶體管理。消費線程也會有hang住的可能,因為無鎖隊列使用cas,當隊列滿了的時候并不會無限增長記憶體,而是會重試幾次後放棄本次操作,避免記憶體暴漲。改造後耗時33s。
glog在linux系統下預設使用的是pthread_rw_lock,在第二步減少鎖粒度的基礎上,現已不需要核心态的讀寫鎖,是以将rwlock替換成使用者态的spinlock。另外__gi_fwrite的熱點還是有一些,采用合并隊列的方法減少一些寫操作,再加上逾時機制,防止緩存的日志不及時落地。總結起來的優化就是:
向前合并隊列寫
glog預設使用的讀寫鎖和mutex鎖,換成spinlock
單條message buffer大小調整
fwrite設定file buffer
這些優化完成後耗時時間為16s。
優化後的glog版本适合使用在需要高日志吞吐量的産品, 比如ocs這種分布式高并發高吞吐量的系統。
從以上優化可以總結出高性能的日志系統的特性:
使用異步io實作高并發的日志吞吐量,日志線程與worker線程解耦,worker線程隻做序列化之類的工作,日志線程隻做io,避免當磁盤滿了等異常情況發生時主路徑阻塞導緻服務完全不可用,這在任何一個高并發的系統中都需要注意的。
其他細節點特性:
不使用localtime取日期,單測localtime和getimeofday 擷取時間, gettimeofday 速度比localtime快20倍
選用無鎖隊列可重試放棄操作,避免記憶體暴漲。
使用記憶體池管理,比如tcmalloc
對fd等關鍵指針做引用計數處理,避免大粒度的鎖。