1 資料解釋
資料集:wiki資料集(2405個網頁,17981條網頁間的關系)
輸入樣本:node1 node2 <edge_weight>
輸出:每個node的embedding
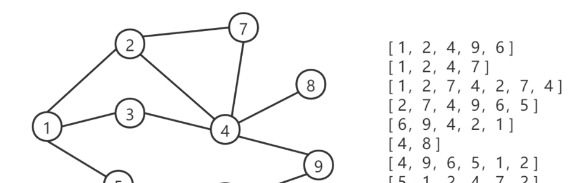
根據随機遊走的序列,輸入到word2vec的模型當中,然後就能訓練後表示出該節點的embedding
2 代碼思想
步驟① 建構一個有向圖 ② 進行deepwalk取樣本 ③ 輸入到word2vec當中訓練 ④ 得到了訓練好的word2vec,進行evaluate
⑤ 資料分為x_train,x_test, 使用logistics函數,訓練embedding後x_train對應的label,然後通過logstics函數預測x_test的标簽(标簽是0-16所屬分類)
⑥畫圖
① 建構一個有向圖
G = nx.read_edgelist('../data/wiki/Wiki_edgelist.txt',
create_using=nx.DiGraph(), nodetype=None, data=[('weight', int)])
② 進行deepwalk取樣本 其中 deepwalk就是根據步長,進行深度優先周遊,如果該節點沒有鄰居節點了,就break出來

def deepwalk_walk(self, walk_length, start_node):
walk = [start_node]
while len(walk) < walk_length:
cur = walk[-1]
cur_nbrs = list(self.G.neighbors(cur))
if len(cur_nbrs) > 0:
walk.append(random.choice(cur_nbrs))
else:
break
return walk
③ 輸入到word2vec當中訓練,得到該點的embedding表示
④ 得到了訓練好的word2vec,得到了2405X128的embedding,然後進行模型的評價
class Classifier(object):
def __init__(self, embeddings, clf):
self.embeddings = embeddings
self.clf = TopKRanker(clf)
self.binarizer = MultiLabelBinarizer(sparse_output=True) # multi one-hot
def train(self, X, Y, Y_all):
self.binarizer.fit(Y_all)
X_train = [self.embeddings[x] for x in X]
Y = self.binarizer.transform(Y)
self.clf.fit(X_train, Y)
def evaluate(self, X, Y):
top_k_list = [len(l) for l in Y]
Y_ = self.predict(X, top_k_list)
Y = self.binarizer.transform(Y)
averages = ["micro", "macro", "samples", "weighted"]
results = {}
for average in averages:
results[average] = f1_score(Y, Y_, average=average)
results['acc'] = accuracy_score(Y,Y_)
print('-------------------')
print(results)
return results
print('-------------------')
def predict(self, X, top_k_list):
X_ = numpy.asarray([self.embeddings[x] for x in X])
Y = self.clf.predict(X_, top_k_list=top_k_list)
return Y
def split_train_evaluate(self, X, Y, train_precent, seed=0):
state = numpy.random.get_state() # 使随機生成器保持相同狀态
training_size = int(train_precent * len(X))
numpy.random.seed(seed)
shuffle_indices = numpy.random.permutation(numpy.arange(len(X))) # 随機打亂順序
X_train = [X[shuffle_indices[i]] for i in range(training_size)]
Y_train = [Y[shuffle_indices[i]] for i in range(training_size)]
X_test = [X[shuffle_indices[i]] for i in range(training_size, len(X))]
Y_test = [Y[shuffle_indices[i]] for i in range(training_size, len(X))]
'''前面部分都是為了打亂順序'''
self.train(X_train, Y_train, Y) # 把label轉成Multi hot 形式,把x_train轉成embedding形式
numpy.random.set_state(state)
return self.evaluate(X_test, Y_test)
⑤ 先使用split_train_evaluate 函數,
(1)打亂資料 (2)把embedding後的x_train與 轉換為mulit-hot的 Y 通過logistics 模型進行訓練
(3) 把測試資料x_test 傳入 logistics模型,得到評估的F1 score
首先測試資料放進logistics模型,并選擇topk的目标值,打上标簽1
然後轉換回label标簽,通過f1 score進行計算
class TopKRanker(OneVsRestClassifier):
def predict(self, X, top_k_list):
probs = numpy.asarray(super(TopKRanker, self).predict_proba(X)) # 預測出來NX17,一共有17個label
all_labels = []
for i, k in enumerate(top_k_list):
probs_ = probs[i, :]
labels = self.classes_[probs_.argsort()[-k:]].tolist()
probs_[:] = 0
probs_[labels] = 1
all_labels.append(probs_)
return numpy.asarray(all_labels)
def evaluate(self, X, Y):
top_k_list = [len(l) for l in Y]
Y_ = self.predict(X, top_k_list)
Y = self.binarizer.transform(Y) # 轉換為label值
averages = ["micro", "macro", "samples", "weighted"]
results = {}
for average in averages:
results[average] = f1_score(Y, Y_, average=average)
results['acc'] = accuracy_score(Y,Y_)
print('-------------------')
print(results)
return results
print('-------------------')
⑥畫圖
通過TSNE進行降維,然後根據 embedding降維後與 wiki_labels的值對應上,畫出二維效果圖
參考文章:
https://zhuanlan.zhihu.com/p/56380812