爬蟲之前
在着手寫爬蟲之前,要先把其需要的知識線路理清楚。
第一:了解相關Http協定知識
HTTP是Hyper Text Transfer Protocol(超文本傳輸協定)的縮寫。它的發展是網際網路協會(World Wide Web Consortium)和Internet工作小組IETF(Internet Engineering Task Force)合作的結果,(他們)最終釋出了一系列的RFC,RFC 1945定義了HTTP/1.0版本。其中最著名的就是RFC 2616。RFC 2616定義了今天普遍使用的一個版本——HTTP 1.1。
HTTP協定(HyperText Transfer Protocol,超文本傳輸協定)是用于從WWW伺服器傳輸超文本到本地浏覽器的傳送協定。它可以使浏覽器更加高效,使網絡傳輸減少。它不僅保證計算機正确快速地傳輸超文本文檔,還确定傳輸文檔中的哪一部分,以及哪部分内容首先顯示(如文本先于圖形)等。
HTTP的請求響應模型
HTTP協定永遠都是用戶端發起請求,伺服器回送響應。
這樣就限制了使用HTTP協定,無法實作在用戶端沒有發起請求的時候,伺服器将消息推送給用戶端。
HTTP協定是一個無狀态的協定,同一個用戶端的這次請求和上次請求是沒有對應關系。
工作流程
一次HTTP操作稱為一個事務,其工作過程可分為四步:
1)首先客戶機與伺服器需要建立連接配接。隻要單擊某個超級連結,HTTP的工作開始。
2)建立連接配接後,客戶機發送一個請求給伺服器,請求方式的格式為:統一資源辨別符(URL)、協定版本号,後邊是MIME資訊包括請求修飾符、客戶機資訊和可能的内容。
3)伺服器接到請求後,給予相應的響應資訊,其格式為一個狀态行,包括資訊的協定版本号、一個成功或錯誤的代碼,後邊是MIME資訊包括伺服器資訊、實體資訊和可能的内容。
4)用戶端接收伺服器所傳回的資訊通過浏覽器顯示在使用者的顯示屏上,然後客戶機與伺服器斷開連接配接。
如果在以上過程中的某一步出現錯誤,那麼産生錯誤的資訊将傳回到用戶端,有顯示屏輸出。對于使用者來說,這些過程是由HTTP自己完成的,使用者隻要用滑鼠點選,等待資訊顯示就可以了。
第二:了解Python中urllib庫
Python2系列使用的是urllib2,Python3後将其全部整合為urllib;我們所需學習的是幾個常用函數。細節可去官網檢視。
第三:開發工具
Python自帶編譯器 -- IDLE,十分簡潔;PyCharm -- 互動很好的Python一款IDE;Fiddler -- 網頁請求監控工具,我們可以使用它來了解使用者觸發網頁請求後發生的詳細步驟;
簡單網頁爬蟲
代碼
'''
第一個示例:簡單的網頁爬蟲
爬取豆瓣首頁
'''
import urllib.request
#網址
url = "https://www.douban.com/"
#請求
request = urllib.request.Request(url)
#爬取結果
response = urllib.request.urlopen(request)
data = response.read()
#設定解碼方式
data = data.decode('utf-8')
#列印結果
print(data)
#列印爬取網頁的各類資訊
print(type(response))
print(response.geturl())
print(response.info())
print(response.getcode())
結果
截取部分結果如下圖:
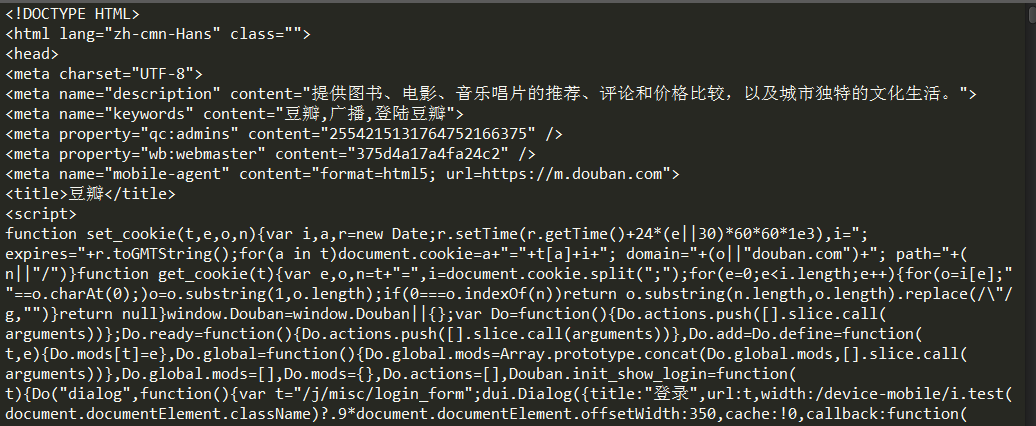
轉載于:https://www.cnblogs.com/gswang/p/7472709.html
![TestLink導出用例轉換工具(XML2Excel)[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)