這次主要是進行京東具體某個店鋪手機評論内容的爬取。
本來是跟上一起寫的,隻是沒有時間一塊做總結,現在寫上來是有點生疏了。這裡是暫時擷取一個商品的評論内容
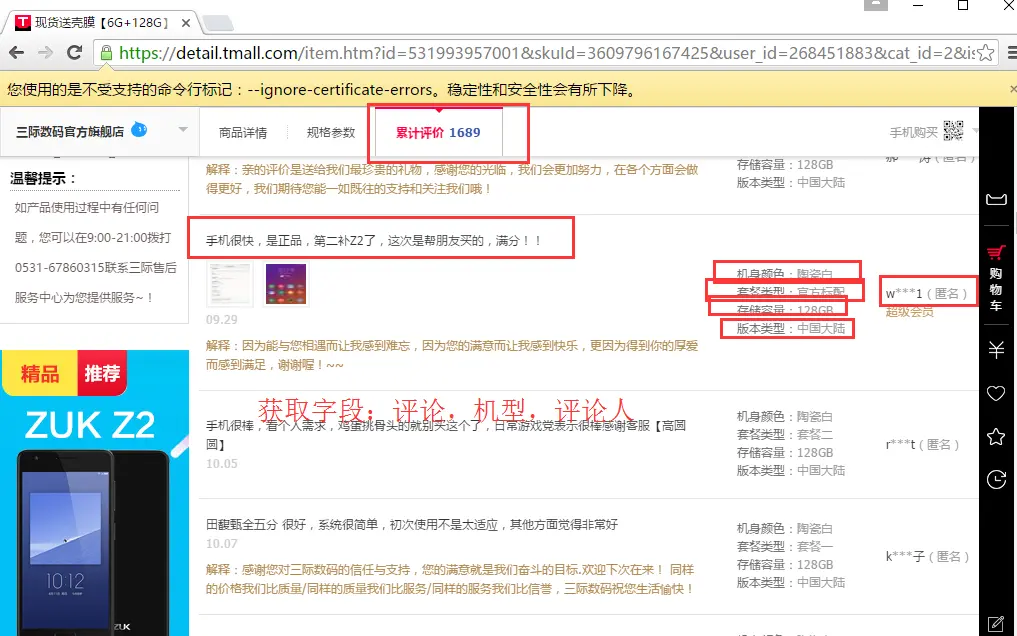
爬取的字段:評論内容,購買機型,評論人
上代碼:
# -*- coding: utf-8 -*-
# @Time : 2017/9/18 23:16
# @Author : 蛇崽
# @Email : [email protected]
# @File : TaoBaoZUK1Detail.py zuk z1 詳情頁内容
import time
from selenium import webdriver
from lxml import etree
chromedriver = "C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe"
browser = webdriver.Chrome(chromedriver)
# 擷取第一頁的資料
def gethtml():
url = "https://detail.tmall.com/item.htm?id=531993957001&skuId=3609796167425&user_id=268451883&cat_id=2&is_b=1&rn=71b9b0aeb233411c4f59fe8c610bc34b"
browser.get(url)
time.sleep()
browser.execute_script('window.scrollBy(0,3000)')
time.sleep()
browser.execute_script('window.scrollBy(0,5000)')
time.sleep()
# 累計評價
btnNext = browser.find_element_by_xpath('//*[@id="J_TabBar"]/li[3]/a')
btnNext.click()
html = browser.page_source
return html
def getcomments(html):
source = etree.HTML(html)
commens = source.xpath("//*[@id='J_TabBar']/li[3]/a/em/text()")
print('評論數一:',commens)
# 将評論轉為int類型
commens = (int(commens[]) / ) +
# 擷取到總評論
print('評論數:',int(commens))
return int(commens)
# print(html)
def parseHtml(html):
html = etree.HTML(html)
commentlist = html.xpath("//*[@class='rate-grid']/table/tbody")
for comment in commentlist:
# 評論
vercomment = comment.xpath(
"./tr/td[@class='tm-col-master']/div[@class='tm-rate-content']/div[@class='tm-rate-fulltxt']/text()")
# 機器類型
verphone = comment.xpath("./tr/td[@class='col-meta']/div[@class='rate-sku']/p[@title]/text()")
print(vercomment)
print(verphone)
# 使用者(頭尾各一個字,中間用****代替)
veruser = comment.xpath("./tr/td[@class='col-author']/div[@class='rate-user-info']/text()")
print(veruser)
print(len(commentlist))
# parseHtml(html)
# print('*'*20)
def nextbuttonwork(num):
if num != :
browser.execute_script('window.scrollBy(0,3000)')
time.sleep()
# browser.find_element_by_css_selector('#J_Reviews > div > div.rate-page > div > a:nth-child(6)').click()
try:
browser.find_element_by_css_selector('#J_Reviews > div > div.rate-page > div > a:last-child').click()
# browser.find_element_by_xpath('//*[@id="J_Reviews"]/div/div[7]/div/a[3][contains(text(), "下一頁")]').click()
except:
pass
# browser.find_element_by_xpath('//*[@id="J_Reviews"]/div/div[7]/div/a[3][contains(text(), "下一頁")]').click()
time.sleep()
browser.execute_script('window.scrollBy(0,3000)')
time.sleep()
browser.execute_script('window.scrollBy(0,5000)')
time.sleep()
html = browser.page_source
parseHtml(html)
print('nextclick finish ')
def selenuim_work(html):
print('selenuim start ... ')
parseHtml(html)
nextbuttonwork()
print('selenuim end....')
pass
def gettotalpagecomments(comments):
html = gethtml()
for i in range(,comments):
selenuim_work(html)
data = gethtml()
# 得到評論
commens = getcomments(data)
# 根據評論内容進行周遊
gettotalpagecomments(commens)
這裡頭還是好的

不足:
這裡主要進行了單頁的爬取, 下一頁的按鈕還是沒有擷取到,不知道為什麼擷取不到,可能是axaj的原因吧, 另外想說一下大公司确實tm牛, 當然了作為爬蟲工程師,這在工作中是不可避免的。還麻煩寫京東商品評論的幫忙指導一下小白。